AQI(Air Quality Index)分析与预测
12 浏览量
2020-12-21
14:35:06
上传
评论 1
收藏 662KB PDF 举报

AQI(Air Quality Index)分析与预测分析与预测
AQI(Air Quality Index)分析与预测分析与预测
背景:背景:
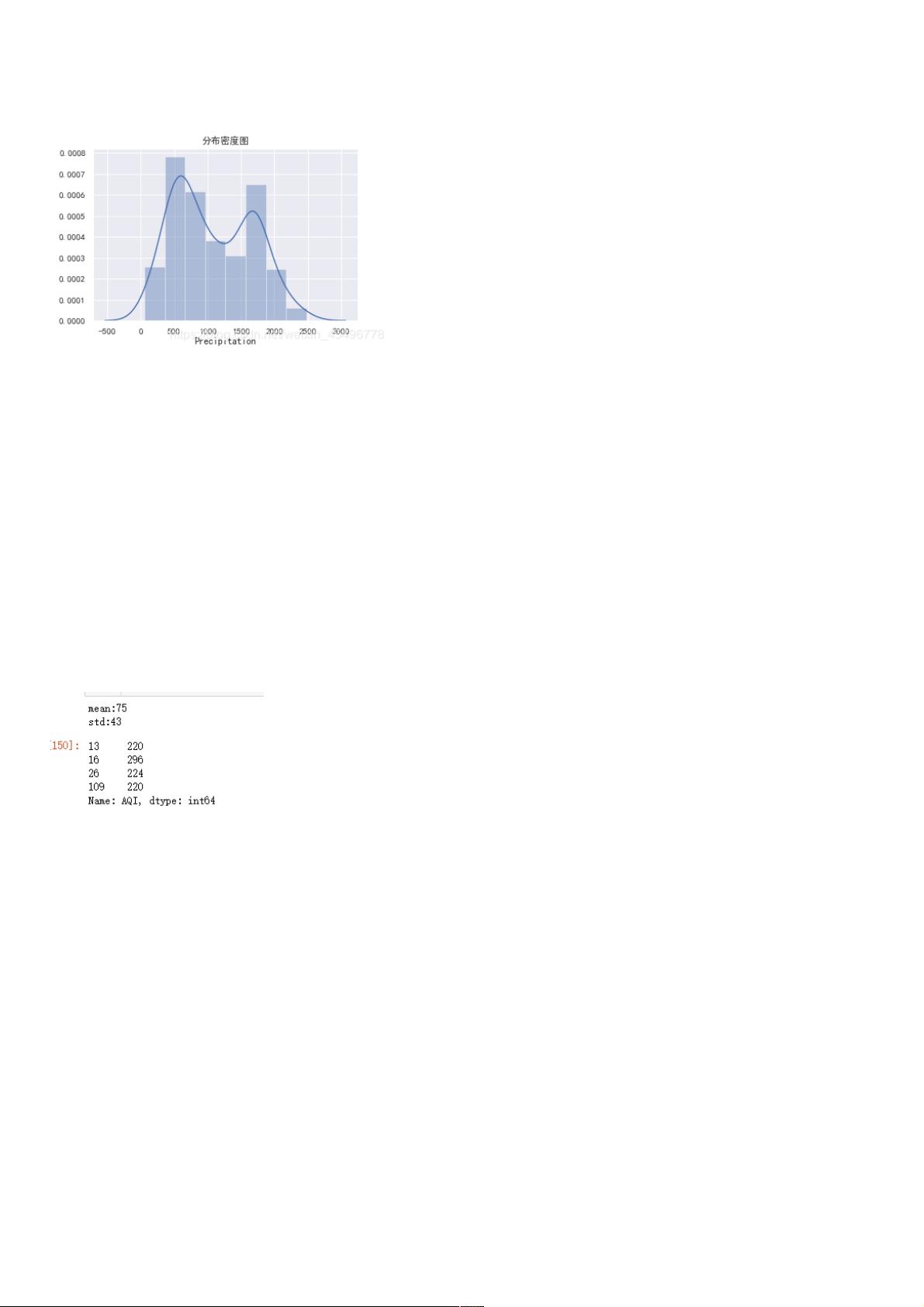
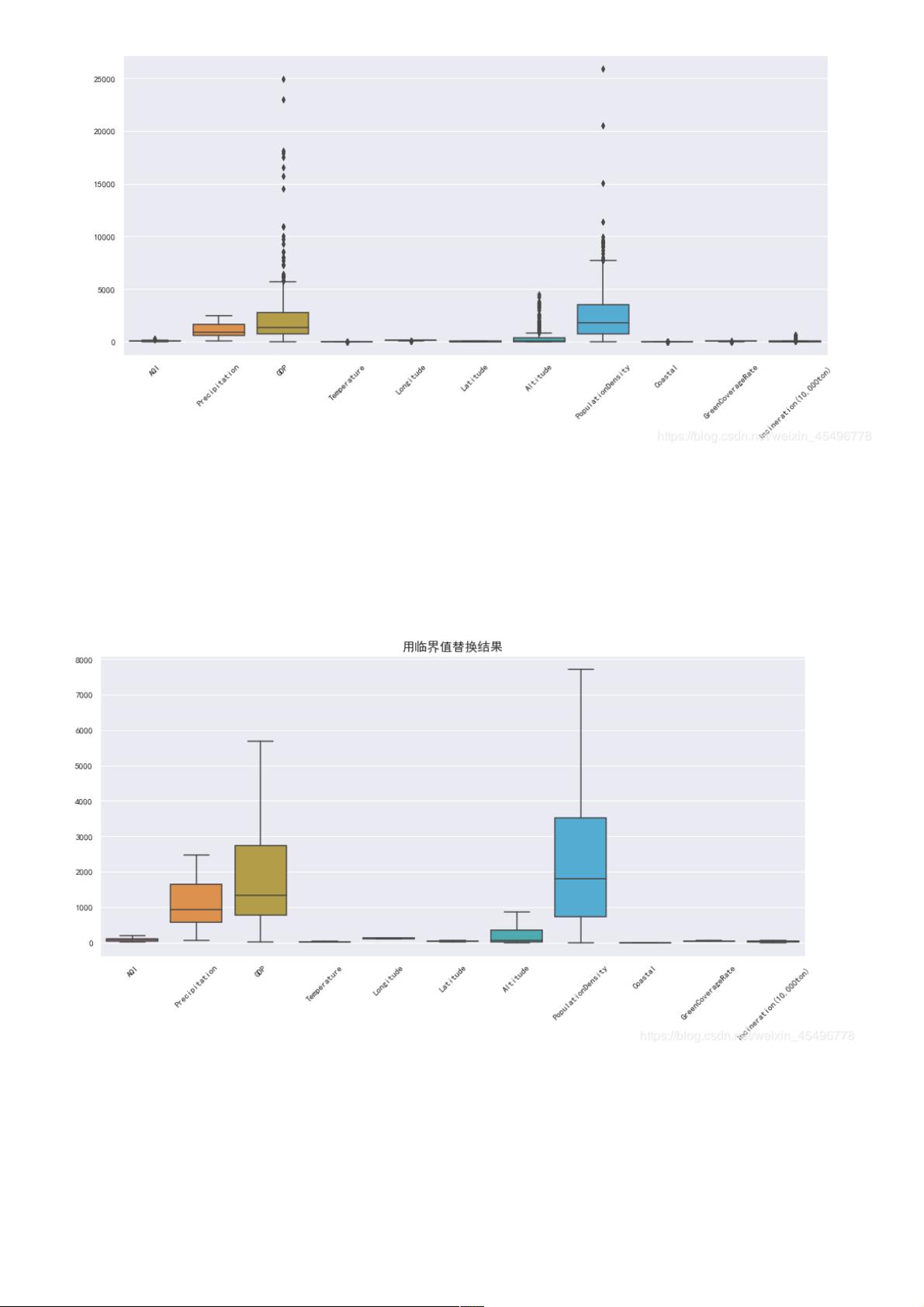
空气质量指数是用来衡量空气清洁或者污染的程度,值越小,表示空气质量越好;近年来,空气质量越来越受到人们的关注。
任务描述:任务描述:
一、描述性统计
那些城市的空气质量较好/较差?
空气质量好坏在地理位置分布上,是否具有一定的规律?
二、推断统计
临海城市的空气质量是否优于内陆城市?
三、相关系数分析
空气质量主要受那些因素的影响?
四、区间估计
全国城市空气质量普遍处于那种水平?
五、统计建模
怎么样预测一个城市的空气质量?
现有数据:现有数据:
2015年全国若干城市空气质量指数集data
特殊指标解析:
AQI:空气质量指数
Altitude:海拔高度
Precipitation:降雨量
Incineration(10,000ton):焚烧量(w吨)
Longitude/Latitude:经/纬度
分析部分分析部分
相关库与数据的导入相关库与数据的导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import matplotlib as mpl
warnings.filterwarnings("ignore")
sns.set(style="darkgrid",font="SimHei",
rc={"axes.unicode_minus":False})#风格,字体,以及正常显示负号
data = pd.read_csv("C://Users//ganyu//Desktop//data.csv")
一、检查数据一、检查数据
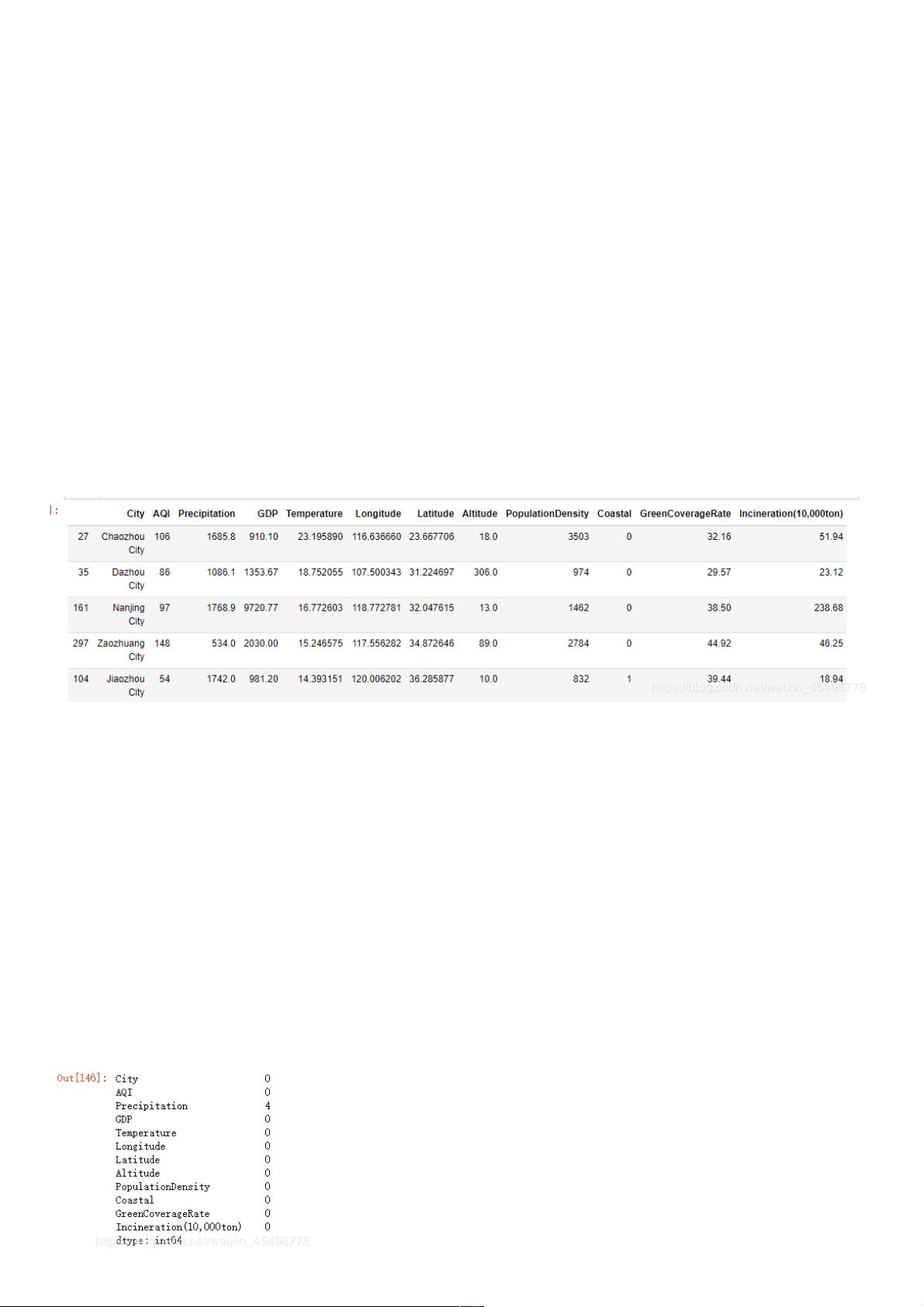
1、检查缺失值、检查缺失值
data.isnull().sum(axis=0)
#data.info()
剩余12页未读,继续阅读













评论0