“数据湖”:概念、特征、架构与案例
198 浏览量
2021-01-27
11:49:10
上传
评论
收藏 1.17MB PDF 举报


“数据湖数据湖”:概念、特征、架构与案例:概念、特征、架构与案例
写在前面:
最近,数据湖的概念非常热,许多前线的同学都在讨论数据湖应该怎么建?阿里云有没有成熟的数据湖解决方案?阿里云的数
据湖解决方案到底有没有实际落地的案例?怎么理解数据湖?数据湖和大数据平台有什么不同?头部的云计算玩家都各自推出
了什么样的数据湖解决方案?带着这些问题,我们尝试写了这样一篇文章,希望能抛砖引玉,引起大家一些思考和共鸣。感谢
南靖同学为本文编写了5.1节的案例,感谢西壁的review。
本文包括七个小节:1、什么是数据湖;2、数据湖的基本特征;3、数据湖基本架构;4、各厂商的数据湖解决方案;5、典型
的数据湖应用场景;6、数据湖建设的基本过程;7、总结。受限于个人水平,谬误在所难免,欢迎同学们一起探讨,批评指
正,不吝赐教。
一、什么是数据湖
数据湖是目前比较热的一个概念,许多企业都在构建或者计划构建自己的数据湖。但是在计划构建数据湖之前,搞清楚什么是
数据湖,明确一个数据湖项目的基本组成,进而设计数据湖的基本架构,对于数据湖的构建至关重要。关于什么是数据湖,有
如下定义。
Wikipedia是这样定义的:
A data lake is a system or repository of data stored in its natural/raw format,[1] usually object blobs or files. A data lake is
usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks
such as reporting, visualization, advanced analytics and machine learning. A data lake can include structured data from
relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails,
documents, PDFs) and binary data (images, audio, video). [2]A data swamp is a deteriorated and unmanaged data lake that
is either inaccessible to its intended users or is providing little value
数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件。数据湖通常是企业中全量数据的单一存储。全
量数据包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,各类任务包括报表、可视化、高级分析和机
器学习。数据湖中包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非
结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)。数据沼泽是一种退化的、缺乏管理的数据
湖,数据沼泽对于用户来说要么是不可访问的要么就是无法提供足够的价值。
AWS的定义相对就简洁一点:
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You
can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards
and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行
结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决
策。
微软的定义就更加模糊了,并没有明确给出什么是Data Lake,而是取巧的将数据湖的功能作为定义:
Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store
data of any size, shape, and speed, and do all types of processing and analytics across platforms and languages. It removes
the complexities of ingesting and storing all of your data while making it faster to get up and running with batch, streaming,
and interactive analytics. Azure Data Lake works with existing IT investments for identity, management, and security for
simplified data management and governance. It also integrates seamlessly with operational stores and data warehouses so
you can extend current data applications. We’ve drawn on the experience of working with enterprise customers and running
some of the largest scale processing and analytics in the world for Microsoft businesses like Office 365, Xbox Live, Azure,
Windows, Bing, and Skype. Azure Data Lake solves many of the productivity and scalability challenges that prevent you
from maximizing the value of your data assets with a service that’s ready to meet your current and future business needs.
Azure的数据湖包括一切使得开发者、数据科学家、分析师能更简单的存储、处理数据的能力,这些能力使得用户可以存储任
意规模、任意类型、任意产生速度的数据,并且可以跨平台、跨语言的做所有类型的分析和处理。数据湖在能帮助用户加速应
用数据的同时,消除了数据采集和存储的复杂性,同时也能支持批处理、流式计算、交互式分析等。数据湖能同现有的数据管
理和治理的IT投资一起工作,保证数据的一致、可管理和安全。它也能同现有的业务数据库和数据仓库无缝集成,帮助扩展现
有的数据应用。Azure数据湖吸取了大量企业级用户的经验,并且在微软一些业务中支持了大规模处理和分析场景,包括
Office 365, Xbox Live, Azure, Windows, Bing和Skype。Azure解决了许多效率和可扩展性的挑战,作为一类服务使得用户可
以最大化数据资产的价值来满足当前和未来需求。
关于数据湖的定义其实很多,但是基本上都围绕着以下几个特性展开。
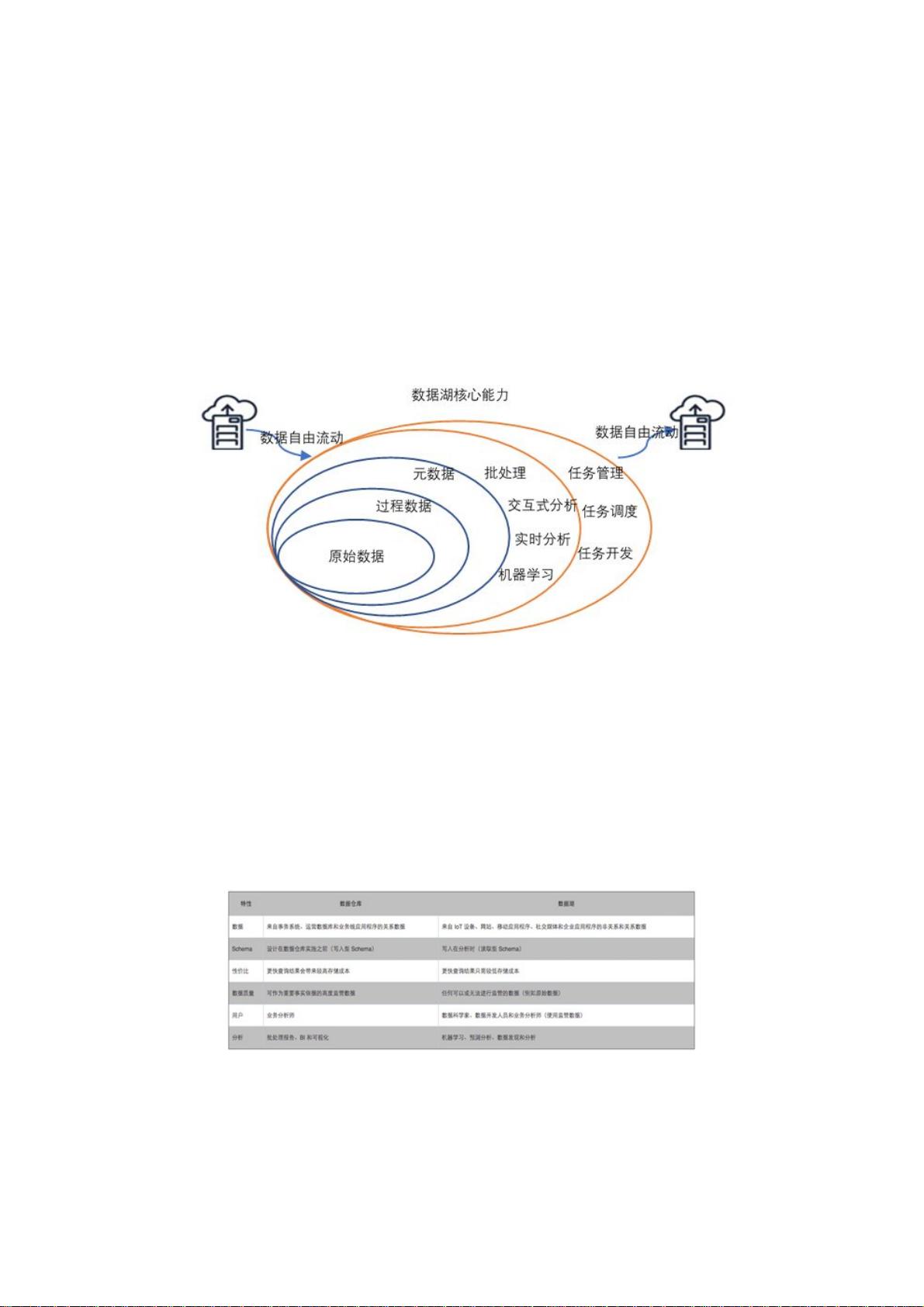
1、 数据湖需要提供足够用的数据存储能力,这个存储保存了一个企业/组织中的所有数据。
2、 数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。

剩余16页未读,继续阅读













评论0