

Content-based Image Retrieval Based On Eye-tracking
Ying Zhou
School of Electronic and Information
Engineering
Soochow University
Suzhou, P.R.China
1621328093@qq.com
Jiajun Wang
School of Electronic and Information
Engineering
Soochow University
Suzhou, P.R.China
jjwang@suda.edu.cn
Zheru Chi
Department of Electronic and
Information Engineering
The HongKong Polytechnic
University, Hong Kong
PolyU Shenzhen Research Institute
Shenzhen, P.R.China
chi.zheru@polyu.edu.hk
ABSTRACT
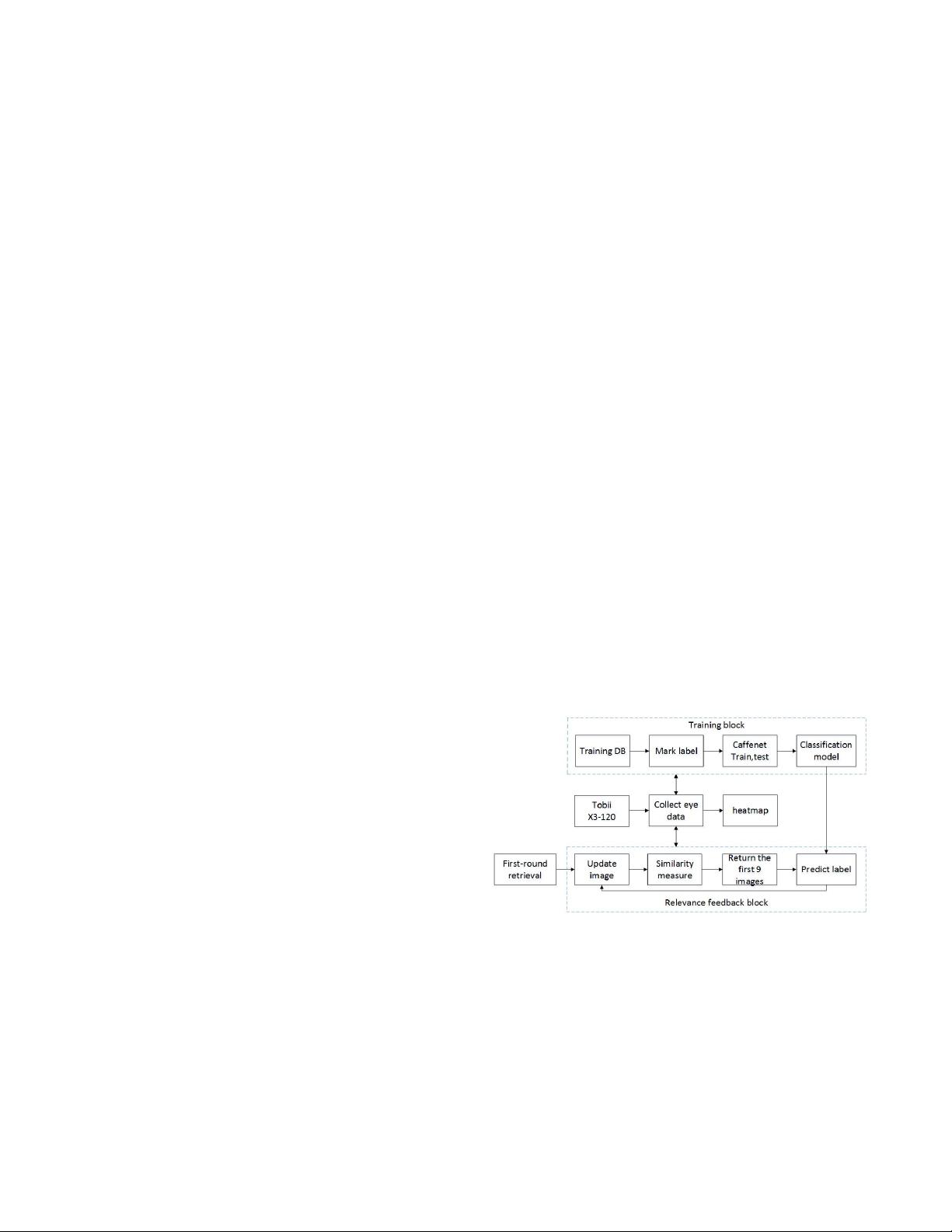
To improve the performance of an image retrieval system, a novel
content-based image retrieval (CBIR) framework with eye track-
ing data based on an implicit relevance feedback mechanism is
proposed in this paper. Our proposed framework consists of three
components: feature extraction and selection, visual retrieval, and
relevance feedback. First, by using the quantum genetic algorithm
and the principle component analysis algorithm, optimal image
features with 70 components are extracted. Second, a ner retriev-
ing procedure based on multiclass support vector machine (SVM)
and fuzzy c-mean (FCM) algorithm is implemented for retrieving
most relevant images. Finally, a deep neural network is trained to
exploit the information of the user regarding the relevance of the
returned images. This information is then employed to update the
retrieving point for a new round retrieval. Experiments on two
databases (Corel and Caltech) show that the performance of CBIR
can be signicantly improved by using our proposed framework.
CCS CONCEPTS
• Information systems → Information retrieval
;
• Informa-
tion retrieval → Retrieval models and ranking
;
• Retrieval
models and ranking → Learning to rank;
KEYWORDS
CBIR, eye tracking, deep neural network
ACM Reference Format:
Ying Zhou, Jiajun Wang, and Zheru Chi. 2018. Content-based Image Re-
trieval Based On Eye-tracking. In COGAIN ’18: Workshop on Communication
by Gaze Interaction, June 14–17, 2018, Warsaw, Poland. ACM, New York, NY,
USA, 7 pages. https://doi.org/10.1145/3206343.3206353
1 INTRODUCTION
With the development of the Internet, computer and multimedia
technology, we have entered the big data era. Every day, the number
of images uploaded to the Internet is growing at an amazing speed.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than ACM
must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,
to post on servers or to redistribute to lists, requires prior specic permission and/or a
fee. Request permissions from permissions@acm.org.
COGAIN ’18, June 14–17, 2018, Warsaw, Poland
© 2018 Association for Computing Machinery.
ACM ISBN 978-1-4503-5790-6/18/06... $15.00
https://doi.org/10.1145/3206343.3206353
It remains to be a challenging problem to retrieve interested images
of users from these vast image data both eciently and accurately.
Since the early 1990s, some well-known universities in the United
States have begun their preliminary study in content based im-
age retrieval (CBIR) techniques [Carson 1999; Ma and Manjunath
1999;Wang et al
.
1995]. Thereafter, more and more researchers
devoted themselves in this led and some CBIR systems were de-
veloped. Typical examples of such systems include the query by
image and video content (QBIC) system [Flickner 1995] and the
multimedia information retrieval system( MIRES). In these systems,
retrieval was primarily performed by extracting image-rich visual
features such as color, texture and shape. In addition to visual fea-
tures, the Scale Invariant Feature Transform (SIFT) descriptors are
also widely used for image retrieval [Peker 2011].
However, due to the dierence between the ways of computers
and human beings in identifying objects, the retrieval systems often
return uninterested results for the users. Human beings identify
two images by accumulated experience and then summarizing the
contents of the images while the computer determines the similarity
of two images by inspecting the similarity degree of the aforemen-
tioned low level features. These two dierent ways often result
in inconsistencies. In some cases, two images are much similar in
terms of low level image features while they are obviously dier-
ent semantically. In other cases, two images are much dierent in
terms of low level features but they belong to the same category
semantically. Therefore, the returns of the low level feature based
retrieval systems often do not meet the requirement of the users
because these systems are implemented in a dierent manner from
human beings. This dierence is usually called the semantic gap.
The most direct and eective way to solve the semantic gap
problem is to develop a closed loop system which permits the
involvement of users upon employing a relevance feedback (RF)
[Qian et al
.
2016;Zhang et al
.
2016] mechanism. The key issue of
such a mechanism is the way to collect the feedback data of the
users regarding the relevance extent of the returns to the query
image. The data can either be collected explicitly through a mouse
or a keyboard or implicitly through the analysis of the data where
the relevance information can be mined. Typical data for such a
purpose include the electroencephalograph (EEG) data [Wang et al
.
2015] and the eye tracking data [Pasupa et al
.
2011]. For implicit
feedback, it is of critical importance to classify the patterns of the
EEG data or the eye tracking data so that the judgement of the user
regarding the relevance extent can be obtained.
剩余6页未读,继续阅读
资源评论













