
万亿级日志与行为数据存储查询技术剖析万亿级日志与行为数据存储查询技术剖析
写在前面
近些年,大数据背后的价值也开始得到关注和重视,越来越多的企业开始保存和分析数据,希望从中挖掘大数据的价值。大数
据产生的根本还是增量数据,单纯的用户数据不足以构成大数据,然而用户的行为或行为相关的日志的数据量,加之随着物联
网的发力,产生的增量数据将不可预估,存储和查询增量数据尤为关键。所以,在笔者的工作经历中,本着以下的目标,寻找
更优的大数据存储和查询方案:
数据无损:数据分析挖掘都依赖于我们保存的数据,只有做到数据的无损,才有可能任意的定义指标,满足各种业务需求。
保证数据实时性:数据的实时性越来越重要,实时的数据能够更好的运维产品和调整策略,价值更高。单进程每秒接入3.5万
数据以上,数据从产生到能够查询到结果这个间隔不会超过5秒。
业务需求快速响应:随着越来越快的业务发展和数据应用要求的提高,数据的查询需要更灵活,快速响应不同且多变的需求。
最好是任意定义指标后能够实时查询出结果。
数据灵活探索性:探索性数据分析在对数据进行概括性描述,发现变量之间的相关性以及引导出新的假设。到了大数据时代,
海量的无结构、半结构数据从多种渠道源源不断地积累,不受分析模型和研究假设的限制,如何从中找出规律并产生分析模型
和研究假设成为新挑战。因此,探索性数据分析成为大数据分析中不可缺少的一步并且走向前台。
超大数据集,统计分析秒级响应:万亿数据量级,千级维度(非稀疏)的统计分析秒级响应。
目前大数据存储查询方案大概可以分为:Hbase系、Dremel系、预聚合系、Lucene系,笔者就自身的使用经验说说这几个系
的优缺点,如有纰漏,欢迎一起探讨。
数据查询包括大体可以分为两步,首先根据某一个或几个字段筛选出符合条件的数据,然后根据关联填充其他所需字段信息或
者聚合其他字段信息,本文中提到的大数据技术,都将围绕这两方面。
一、Hbase系
笔者认为Hbase系的解决方案(例如Opentsdb和Kylin)适合相对固定的业务报表类需求,只需要统计少量维度即可满足业务
报表需求,对于单值查询有优势,但很难满足灵活聚合数据的场景。
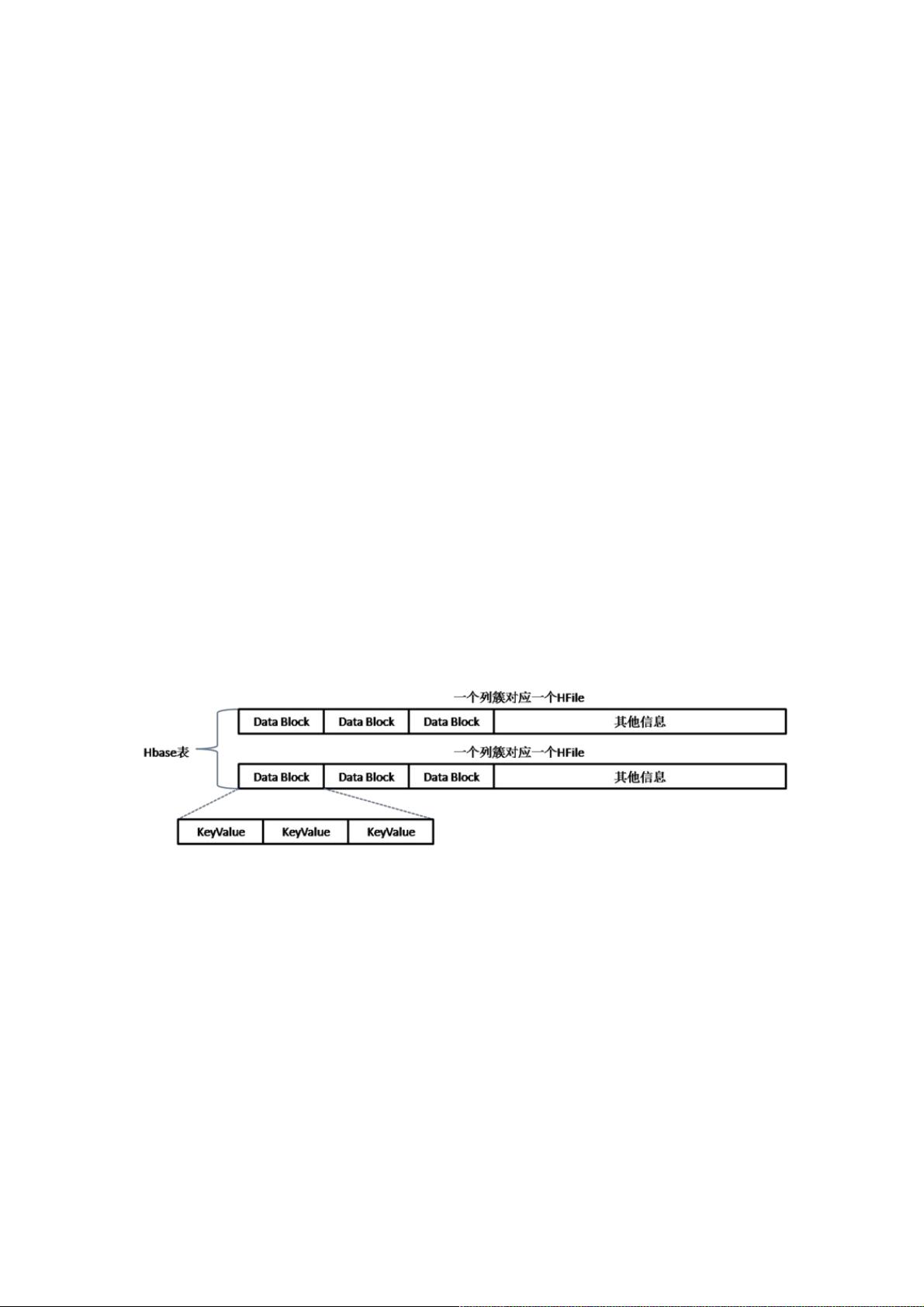
Hbase的表包含的的概念有rowkey、列簇、列限定符、版本(timestamp)和值,对应实际Hdfs的存储结构可以用下图做一个简
单总结:
Hbase表中的每一个列簇会对应一个实际的文件,某种层面来说,Hbase并非真正意义的列式存储方案,只是列簇存储。每个
文件有若干个DataBlock(数据块默认64k),DataBlock是HBase中数据存储的最小单元,DataBlock中以KeyValue的方式存储
用户数据(KeyValue后面有timestamp,图中未标注),其他信息主要包含索引、元数据等信息,在此不做深入探讨。每个
KeyValue都由4个部分构成,分别为key length,value length,key和value。其中key的结构相对复杂,包括rowkey、列、
KeyType等信息,而value值对应具体列值的二进制数据。为了便于查询,对key做了一个简单的倒排索引,直接使用了java的
ConcurrentSkipListMap。
Hbase管理的核心思想是分级分块,存储时根据Rowkey的范围不同,分散到不同的Region,Region又按照列簇分为不同的
Store,每个Store实际上又包括StoreFile(对应Hfile)和MemStore,然后由RegionServer管理不同的Region,RegionServer即
对应具体的进程,分散不同的机器,提供分布式的存储和查询。查询时,首先获取meta表(一种特殊的Region)所在的
RegionServer,通过meta表查找表rowkey相对应的Region和RegionServer信息,最后连接数据所在的RegionServer,查找到
相应的数据。
Hbase的这种结构,特别适合根据rowkey做单值查询,不适合scan的场景,因为大部分Scan的情况基本上需要扫描所有数
据,性能会非常差。虽然也有扩展的Hbase二级索引方案,但基本上都是通过协处理器,需要另外建立一份rowkey的对应关
系,Scan的时候先通过二级索引查找rowkey,然后在根据rowkey查找相应的数据。
这种方式一定程度上能加快数据扫描,但那对于一些识别度不高的列,如性别这样的字段,对应的rowkey相当之多,这样的
字段在查找二级索引时的作用很小,另外二级索引所带来的IO性能的开销都会随之增加。而在需要聚合的场景,对于Hbase而
言恰恰需要大量scan数据,会非常影响性能。Hbase只有一个简单rowkey的倒排索引,缺少列索引,所有的查询和聚合只能
依赖于rowkey,很难解决聚合的性能问题。
随着Hbase的发展,基于Hbase做数据存储包括Opentsdb和Kylin也随之产生,例如Kylin也是一种预聚合方案,因其底层存储
资源评论













