番外.李宏毅学习笔记.ST4.Sequence Labeling
101 浏览量
2021-01-20
11:20:39
上传
评论
收藏 1.09MB PDF 举报

番外番外.李宏毅学习笔记李宏毅学习笔记.ST4.Sequence Labeling
文章目录文章目录Sequence LabelingDefinitionExample Task: POS taggingHidden Markov Model (HMM)HMM – Step 1HMM – Step 2HMM的数学表达HMM– Estimating the probabilitiesHMM – Viterbi
AlgorithmHMM – SummaryConditional Random Field (CRF)P(x,y) for CRFFeature VectorCRF – Training CriterionCRF – InferenceCRF v.s. HMMCRF – SummaryStructured Perceptron/SVMStructured
PerceptronStructured SVMPerformance of Different Approaches总结
公式输入请参考:在线Latex公式
课程PPT
Sequence Labeling
Definition
来看看定义(这里的定义其实并不严格,先暂时假定输入和输出的Sequence的长度都是相等的,为LLL,实际上有很多种情况,其实在前面的课程有讲过):
RNN can handle this task, but there are other methods based on structured learning(two steps, three problems).
典型应用:
•Name entity recognition
• Identifying names of people, places, organizations, etc.
from a sentence
• Harry Potter is a student of Hogwarts and lived on Privet Drive.
识别结果:
people: Harry Potter
organizations: Hogwarts
places: Privet Drive
not a name entity: 其他部分
但是对于中文的抽取很麻烦,例如下面两句要抽取人名:
楊公再興之神(出自金庸《笑傲江湖》)
馮氏埋香之塚(出自金庸《射雕英雄传》)
下面来看例子
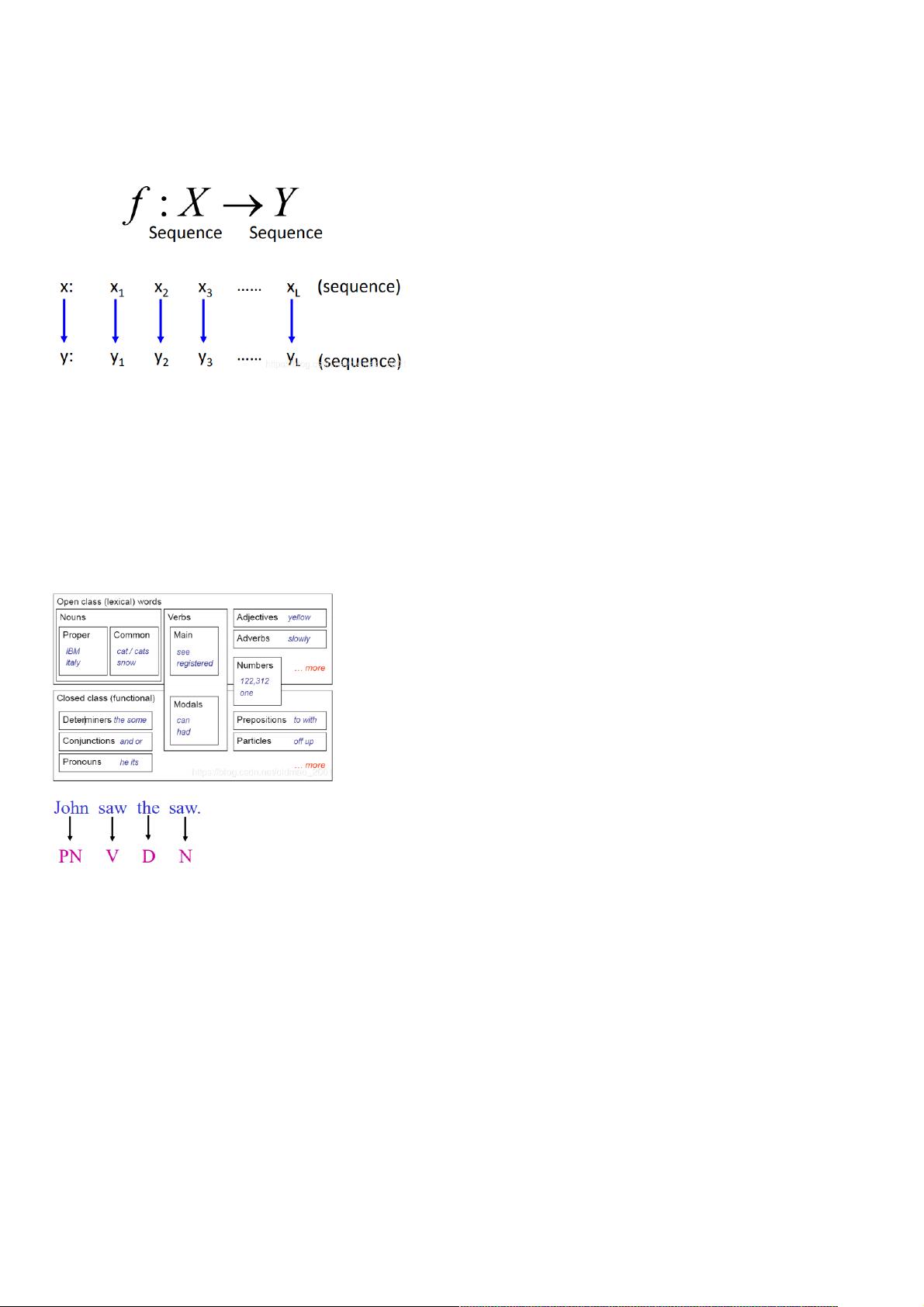
Example Task: POS tagging
Annotate each word in a sentence with a part-of-speech.输入一个句子,输出每个词的类型,例如名词,动词什么的。
Useful for subsequent syntactic parsing and word sense disambiguation, etc.
下面是一个小例子,看到都是saw,有不一样的词性。
这个看起来很简单的东西,明显是不可以直接把词和词性保存下来,然后直接做简单的查询就行了。
“saw” is more likely to be a verb V rather than a noun N,为什么会知道第二个saw是名词呢?因为它在the后面
the second “saw” is a noun N because a noun N is more likely to follow a determiner.
也就是说词性和词序有很大关系。下面就将考虑词序的structed learning的技术依次介绍。
Hidden Markov Model (HMM)
先来看看人是如何构造一个句子:
Step 1
• Generate a POS sequence
• Based on the grammar
Step 2
• Generate a sentence based on the POS sequence
• Based on a dictionary
这实际上和HMM假设是一样的。
HMM – Step 1
根据脑中的语法建立一个POS的sequence:






评论0
最新资源