李宏毅机器学习学习笔记
需积分: 0 156 浏览量
2023-08-05
16:43:19
上传
评论
收藏 651KB PDF 举报

本节课主要介绍了 Adaptive Learning Rate 的基本思想和方法。通过使用 Adaptive Learning
Rate 的策略,在训练深度神经网络时程序能实现在不同参数、不同 iteration 中,学习率不同。
本节课涉及到的算法或策略有:Adgrad、RMSProp、Adam、Learning Rate Decay、Warm Up。
本节课参考的资料有:
MIT-Deep Learning:https://www.deeplearningbook.org/
Adam:https://arxiv.org/pdf/1412.6980.pdf
Residual Network:https://arxiv.org/abs/1512.03385
Transformer:https://arxiv.org/abs/1706.03762
RAdam:https://arxiv.org/abs/1908.03265
一、背景:固定learning rate的弊端
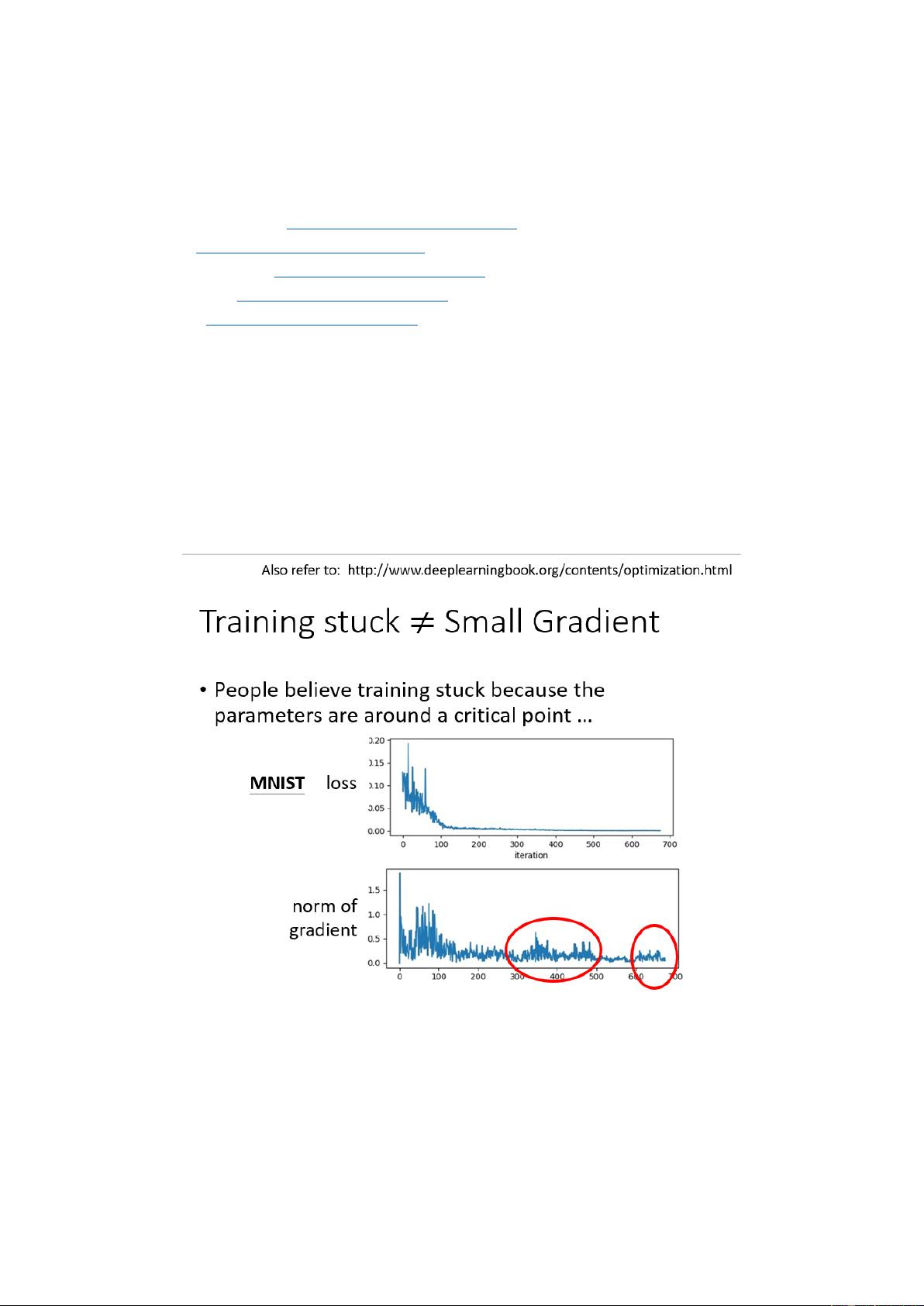
在对神经网络进行训练时,critical point 不一定是训练过程中最大的阻碍点,多数时候,
training 还没有走到 critical point 的时候训练过程就已经停止了。图 1 上半部分反映的是 loss
值随着 iteration 的变化情况,下半部分反映的是 norm of gradient(gradient 向量的长度)随
着 iteration 的变化。可知,随着 iteration 增大,loss 不再下降,但是 gradient 的长度却并没
有减小。此时 gradient 可能在 error surface 山谷的谷壁间不断来回震荡,只是 loss 不再下降,
但并非卡在 critical point。
图 1
图 2 展现的是 training convex optimization 的情景。图中右上部分的叉号标记的为我们的最
优点,其 error surface 是一个椭圆形状(图中只呈现了 error surface 的部分),在横轴方向
gradient 的梯度变化较小,坡度较缓;在纵轴方向 gradient 变化较大,坡度较陡。图中左下
角展示的是当学习率为 10
-2
时,参数 update 的路径,可知 gradient 是处于震荡状态;当将学
习率调整到 10
-7
时,gradient 终于不再震荡,但 update 到图中心的直角处时,始终都走不到
资源评论













