
快速理解快速理解YOLO目标检测目标检测
YOLO(You Only Look Once)论文近些年,R-CNN等基于深度学习目标检测方法,大大提高了检测精度和检测速度。
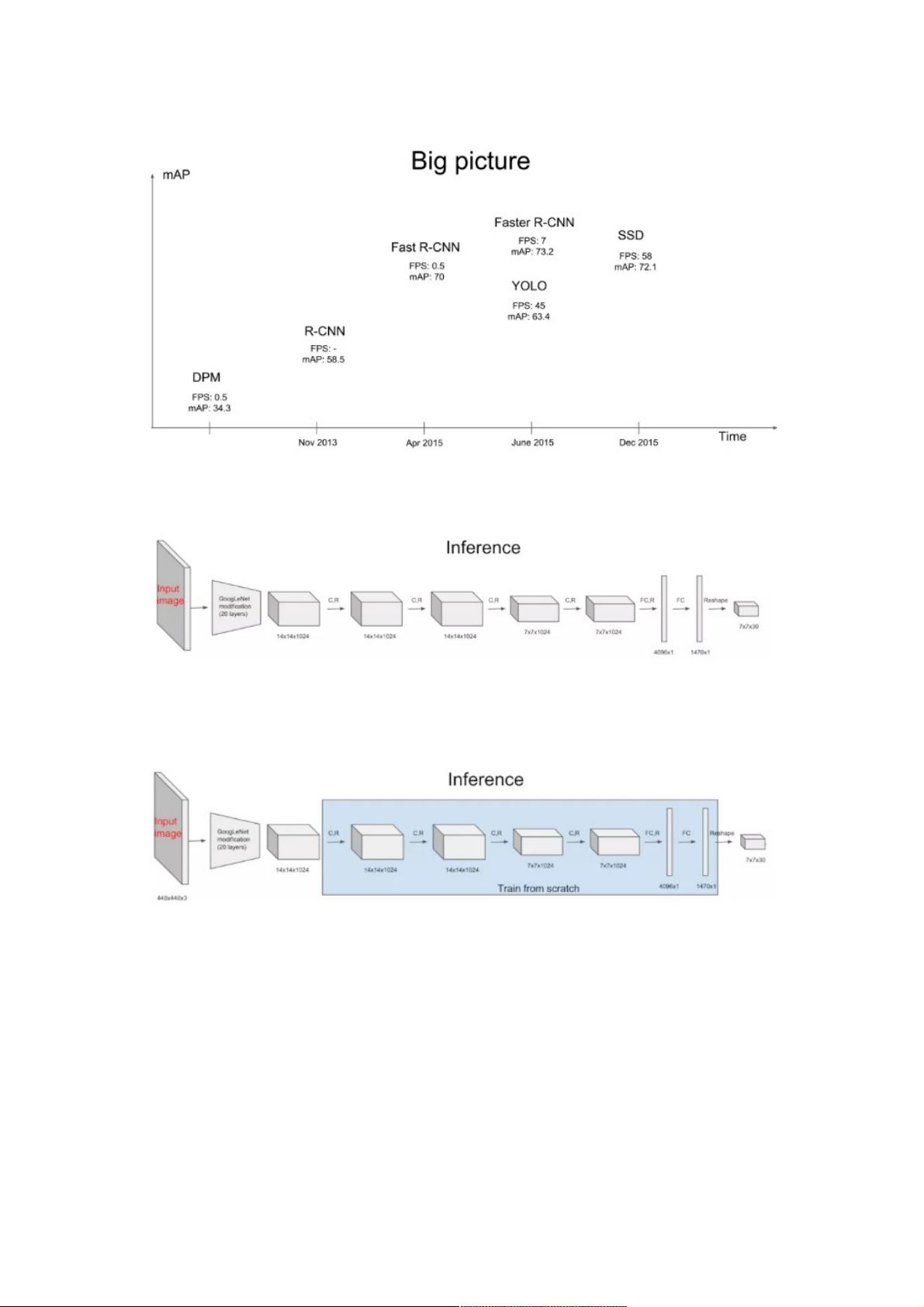
例如在Pascal VOC数据集上Faster R-CNN的mAP达到了73.2。而YOLO和SSD在达到较高的检测精度的同时,检测速度都在
40FPS以上。
整个YOLO的网络结构如图,前面20层使用了改进的GoogleNet,得到14×14×1024的tensor,接下来经过4个卷积层分别进行
3×3的卷积操作和1×1的降维操作,最后经过两个全连接层后输出为7×7×30的tensor。检测目标就能从7×7×30的tensor中得
到。
作者首先取出前面的20层网络,另外再加上一个average-pooling层和一个全连接层,在ImageNet训练集上进行图像分类任务
的欲训练,top-5达到88%的准确度。然后将经过图像分类训练的前20层网络加上后面的网络层进行检测任务的训练。7×7×30
tensor的解释:其实这里的7×7并不是将输入图像划分为7×7的网格,实际上指经过多个卷积层处理过后的特征map是7×7大小
的,而且其中的每个cell是互相有重叠的,但是为了便于直观理解,直接将原始图像用7×7的网格进行划分。可以看到每个cell
向量的前5维分别代表了一个检测框的x坐标,y坐标,宽度和高度,检测框中有目标物体的置信度(P(Object) IOU)。

剩余7页未读,继续阅读
资源评论


weixin_38670065
- 粉丝: 4
- 资源: 923









最新资源
- 光纤到户及通信基础设施报装申请表.docx
- 踝关节功能丧失程度评定表.docx
- 环保设施投资估算表.docx
- 既有建筑物通信报装申请表.docx
- 既有建筑物通信报装现场查勘报告.docx
- 监督机构检查记录表.docx
- 肩关节功能丧失程度评定表.docx
- 大学生创新创业训练计划大创项目的全流程指南
- 简易低风险工业厂房通信报装申请表.docx
- 建设工程消防验收各阶段意见回复表.docx
- 建设工程消防验收模拟验收意见表.docx
- 建设工程消防验收图纸核查意见表.docx
- 建设工程消防验收现场指导意见表.docx
- 建筑工程竣工验收消防设计质量检查报告(表格填写模板).docx
- 建筑工程消防查验意见和结论.docx
- 建筑工程消防施工竣工报告(表格填写模板).docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


