
Python实现堆排序的方法详解实现堆排序的方法详解
主要介绍了Python实现堆排序的方法,结合实例形式详细分析了堆排序的原理,实现方法与相关注意事项,需要的
朋友可以参考下
本文实例讲述了Python实现堆排序的方法。分享给大家供大家参考,具体如下:
堆排序作是基本排序方法的一种,类似于合并排序而不像插入排序,它的运行时间为O(nlogn),像插入排序而不像合并排序,
它是一种原地排序算法,除了输入数组以外只占用常数个元素空间。
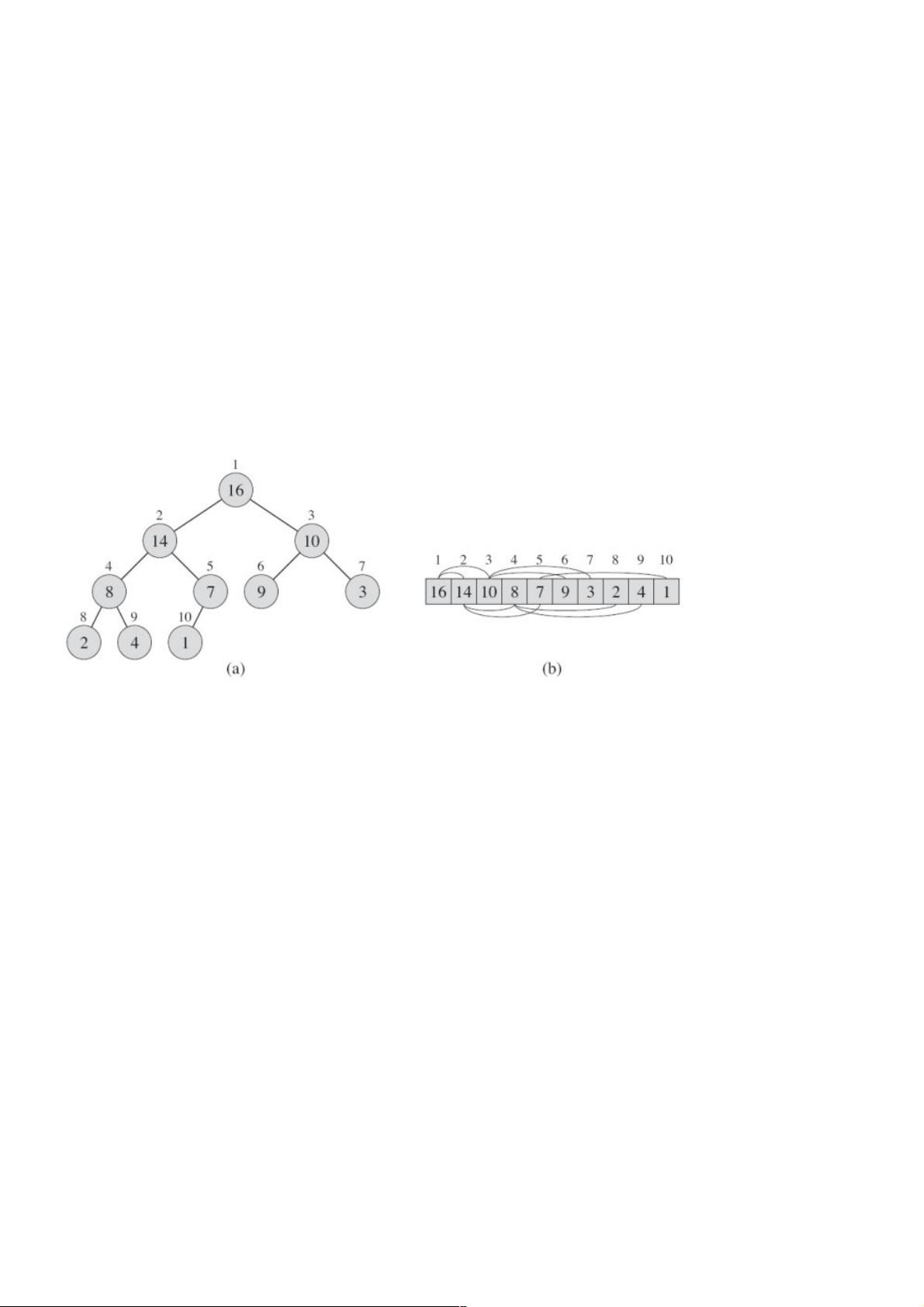
堆(定义):堆(定义):(二叉)堆数据结构是一个数组对象,可以视为一棵完全二叉树。如果根结点的值大于(小于)其它所有结点,
并且它的左右子树也满足这样的性质,那么这个堆就是大(小)根堆。
我们假设某个堆由数组A表示,A[1]为树的根,给定某个结点的下标i,其父结点、左孩子、右孩子的下标都可以计算出来:
PARENT(i):
return i/2
LEFT(i):
return 2i
RIGHT(i):
return 2i+1
堆排序堆排序Python实现实现
所谓堆排序的过程,就是把一些无序的对象,逐步建立起一个堆的过程。
下面是用Python实现的堆排序的代码:
def build_max_heap(to_build_list):
"""建立一个堆"""
# 自底向上建堆
for i in range(len(to_build_list)/2 - 1, -1, -1):
max_heap(to_build_list, len(to_build_list), i)
def max_heap(to_adjust_list, heap_size, index):
"""调整列表中的元素以保证以index为根的堆是一个最大堆"""
# 将当前结点与其左右子节点比较,将较大的结点与当前结点交换,然后递归地调整子树
left_child = 2 * index + 1
right_child = left_child + 1
if left_child < heap_size and to_adjust_list[left_child] > to_adjust_list[index]:
largest = left_child
else:
largest = index
if right_child < heap_size and to_adjust_list[right_child] > to_adjust_list[largest]:
largest = right_child
if largest != index:
to_adjust_list[index], to_adjust_list[largest] = \
to_adjust_list[largest], to_adjust_list[index]
max_heap(to_adjust_list, heap_size, largest)
def heap_sort(to_sort_list):
"""堆排序"""
# 先将列表调整为堆
build_max_heap(to_sort_list)
heap_size = len(to_sort_list)
# 调整后列表的第一个元素就是这个列表中最大的元素,将其与最后一个元素交换,然后将剩余的列表再调整为最大堆
for i in range(len(to_sort_list) - 1, 0, -1):
to_sort_list[i], to_sort_list[0] = to_sort_list[0], to_sort_list[i]
heap_size -= 1
max_heap(to_sort_list, heap_size, 0)
if __name__ == '__main__':
to_sort_list = [4, 1, 3, 2, 16, 9, 10, 14, 8, 7]

weixin_38666527
- 粉丝: 9
- 资源: 911









最新资源
- qimo_text.zip
- 3CDaemon-FTP、syslog、TFTP服务器模拟程序
- 2024年企业级聊天机器人应用与优化指南
- 新能源汽车行业2025年度策略:行业触底回升,新技术加速落地.pdf
- 中国银河-钢铁行业深度报告:供需格局改善,行业产能优化强者更强.pdf
- 电力设备及新能源行业2025年年度投资策略:行业触底,复苏在即.pdf
- OTA行业深度报告:春暖花开,奔赴山海.pdf
- AI深度洞察系列报告(三):Scale up与Scaleout组网变化趋势如何看?.pdf
- 玛莎拉蒂年会活动方案.pdf
- 提升企业开源开发有效性和影响力的路线图 .pdf
- 推动应用创新的九大 AI 趋势.pdf
- 欧洲的开源成熟度:2024年的里程碑、机遇与路径研究报告(英文版).pdf
- 2024年量子技术研究报告:投资于拐点(英文版).pdf
- 2024年地中海南部和东部(SEMED)新就业形态与平台工作研究报告(英文版).pdf
- 2024年环境经济核算体系-生态系统核算报告(英文版).pdf
- 2024年东南亚的可持续航空燃料基于生物的解决办法的区域视角报告(英文版).pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
前往页