使用卷积神经网络(CNN)做人脸识别的示例代码
39 浏览量
2020-09-17
16:07:57
上传
评论 1
收藏 720KB PDF 举报

使用卷积神经网络(使用卷积神经网络(CNN)做人脸识别的示例代码)做人脸识别的示例代码
主要介绍了使用卷积神经网络(CNN)做人脸识别的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的
参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
上回书说到了对人脸的检测,这回就开始正式进入人脸识别的阶段。
关于人脸识别,目前有很多经典的算法,当我大学时代,我的老师给我推荐的第一个算法是特征脸法,原理是先将图像灰度化,然后将图像每行首尾相接
拉成一个列向量,接下来为了降低运算量要用PCA降维, 最后进分类器分类,可以使用KNN、SVM、神经网络等等,甚至可以用最简单的欧氏距离来度
量每个列向量之间的相似度。OpenCV中也提供了相应的EigenFaceRecognizer库来实现该算法,除此之外还有FisherFaceRecognizer、
LBPHFaceRecognizer以及最近几年兴起的卷积神经网络等。
卷积神经网络(CNN)的前级包含了卷积和池化操作,可以实现图片的特征提取和降维,最近几年由于计算机算力的提升,很多人都开始转向这个方
向,所以我这次打算使用它来试试效果。
老规矩,先配置下编程的环境:
系统:windows / linux
解释器:python 3.6
依赖库:numpy、opencv-python 3、tensorflow、keras、scikit-learn
pip3 install numpy
pip3 install opencv-python
pip3 install keras
pip3 install scikit-learn
pip3 install tensorflow
如果手中有一块支持Cuda加速的GPU建议安装GPU版本:
pip3 install tensorflow-gpu
上次文章有位读者评论说:
所以,为了照顾初学者,这里简单介绍下Anaconda的安装方法,Anaconda是一个开源的Python发行版本,其包含了Conda、Python等180多个科学包及
其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大,所以有python包安装基础的人还是建议通过pip来安装所需的依赖。
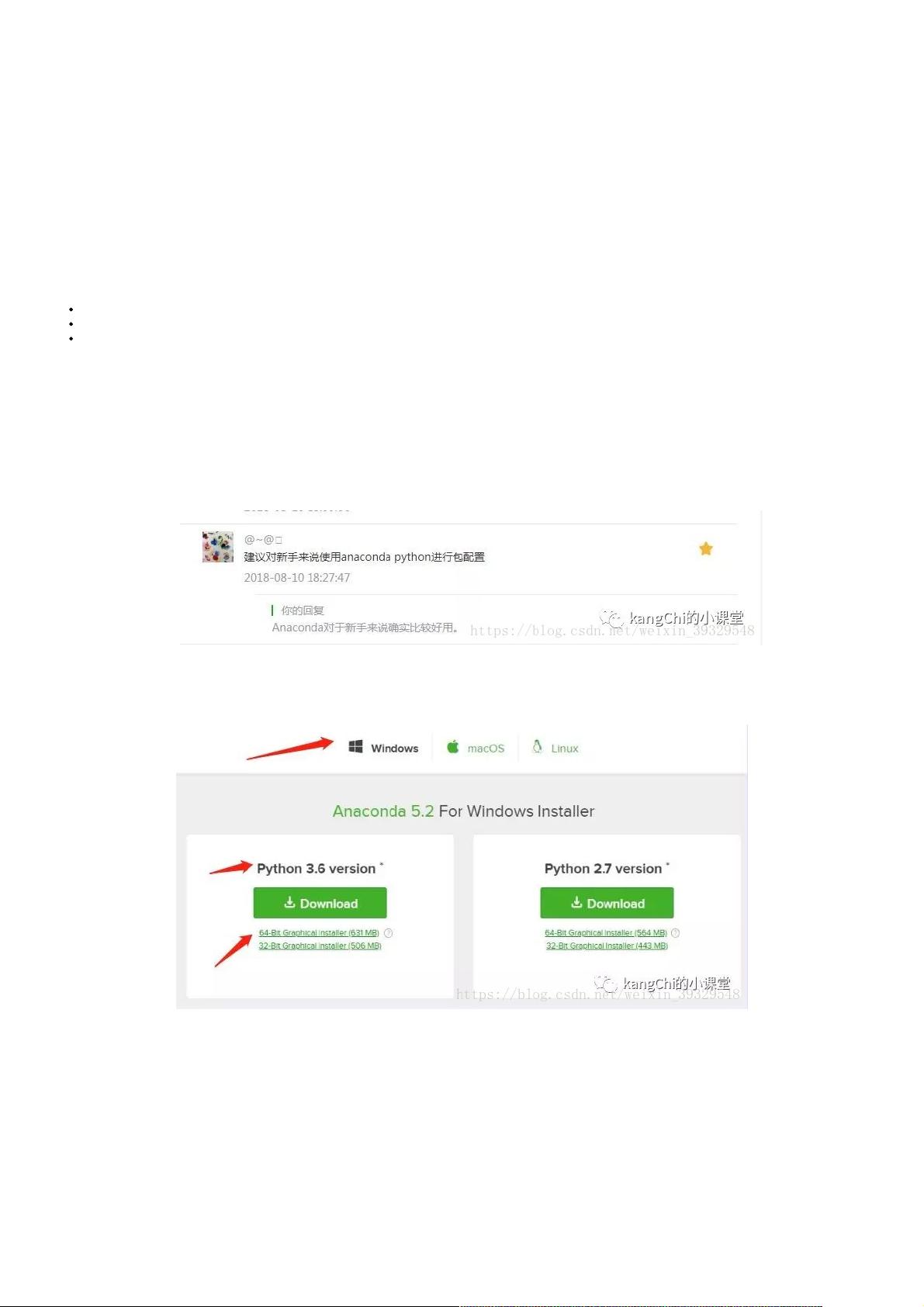
首先进入Anaconda下载页(https://www.anaconda.com/download/):
这里根据自己的电脑系统来选择相应的系统选项,至于是64位还是32位要根据自己电脑的内存大小和系统位数来选择,python版本选择3.6。
下载完成安装,打开程序,切换左侧菜单到Environment,选择all,输入想要安装的模块并搜索,选中后点击右下角的Apply就开始安装了。
资源评论


weixin_38661466
- 粉丝: 7
- 资源: 930









最新资源
- 实现了7种排序算法.三种复杂度排序.三种nlogn复杂度排序(堆排序,归并排序,快速排序)一种线性复杂度的排序.zip
- 冒泡排序 直接选择排序 直接插入排序 随机快速排序 归并排序 堆排序.zip
- 课设-内部排序算法比较 包括冒泡排序、直接插入排序、简单选择排序、快速排序、希尔排序、归并排序和堆排序.zip
- Python排序算法.zip
- C语言实现直接插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序、归并排序、计数排序,并带图详解.zip
- 常用工具集参考用于图像等数据处理
- 音乐展示网页、基于Stenography的图像数字水印添加与提取,以及基于颜色矩和Tamura算法的图像相似度评估算法py源码
- 基于EmguCV(OpenCV .net封装),图像数字水印加解密算法的实现,其中包含最低有效位算法,离散傅里叶变换算法+文档书
- 基于matlab+DWT的图像水印项目,数字水印+源代码+文档说明+图片+报告pdf
- (优秀毕业设计)基于python实现的数字图像可视化水印系统的设计与实现,多种数字算法实现+源代码+文档说明+理论演示pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


