
《动手学深度学习《动手学深度学习——机器翻译及相关技术,注意力机制与机器翻译及相关技术,注意力机制与seq2seq模模
型,型,Transformer》笔记》笔记
动手学深度学习:机器翻译及相关技术,注意力机制与动手学深度学习:机器翻译及相关技术,注意力机制与seq2seq模型,模型,Transformer
初次学习机器翻译相关,把课程的概念题都记录一下。
目录:目录:
1、机器翻译及相关技术、机器翻译及相关技术
2、注意力机制与、注意力机制与seq2seq模型模型
3、、Transformer
1、机器翻译以及相关技术、机器翻译以及相关技术
1、机器翻译以及相关技术
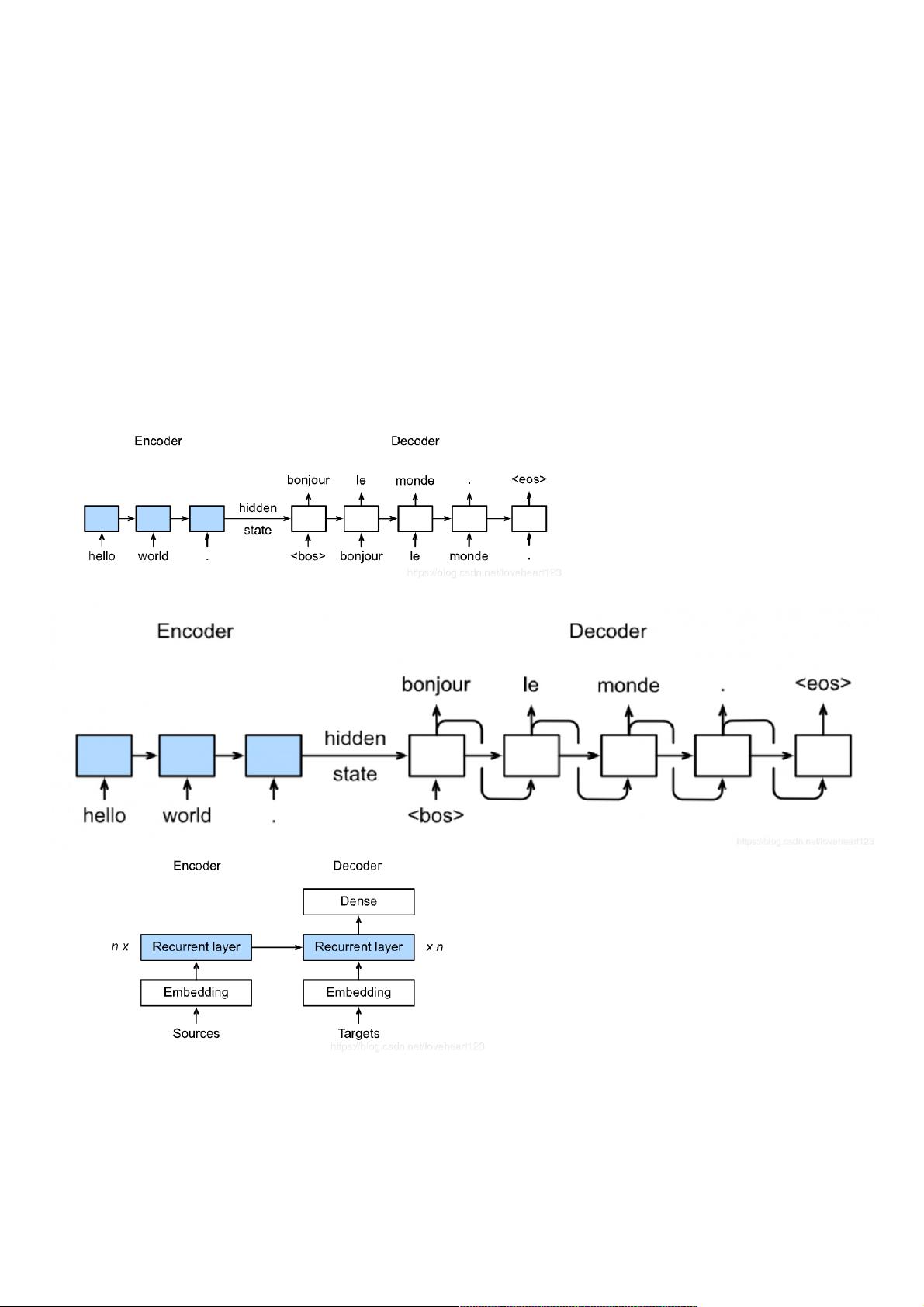
1、关于Sequence to Sequence模型说法错误的是:
A 训练时decoder每个单元输出得到的单词作为下一个单元的输入单词。
B 预测时decoder每个单元输出得到的单词作为下一个单元的输入单词。
C 预测时decoder单元输出为句子结束符时跳出循环。
D 每个batch训练时encoder和decoder都有固定长度的输入。
选项一:错误,参考Sequence to Sequence训练图示。
选项二:正确,参考Sequence to Sequence预测图示。
选项三:正确,参考Sequence to Sequence预测图示。
选项四:正确,每个batch的输入需要形状一致。
Sequence to Sequence模型模型
模型:模型:
**
训练
预测
具体结构:
不属于Encoder-Decoder应用的是
A 机器翻译
B 对话机器人
C 文本分类任务
D 语音识别任务
注:
Encoder-Decoder常应用于输入序列和输出序列的长度是可变的,如选项一二四,而分类问题的输出是固定的类别,不需要使用Encoder-Decoder
2、关于集束搜索(Beam Search)说法错误的是:
A 集束搜索结合了greedy search和维特比算法。
B 集束搜索使用beam size参数来限制在每一步保留下来的可能性词的数量。
C 集束搜索是一种贪心算法。
D 集束搜索得到的是全局最优解。
选项一:正确,参考视频末尾Beam Search。
选项二:正确,参考视频末尾Beam Search。

weixin_38659789
- 粉丝: 4
- 资源: 923












评论0