
Hadoop大数据平台架构与实践大数据平台架构与实践|HDFS
HDFS作为Hadoop的核心部分,是Hadoop中MapReduce框架的存储层。
1、为什么需要分布式文件系统
当文件的大小超过了单台计算机的存储能力时,就需要将其分区存储在不同单独的计算机上。
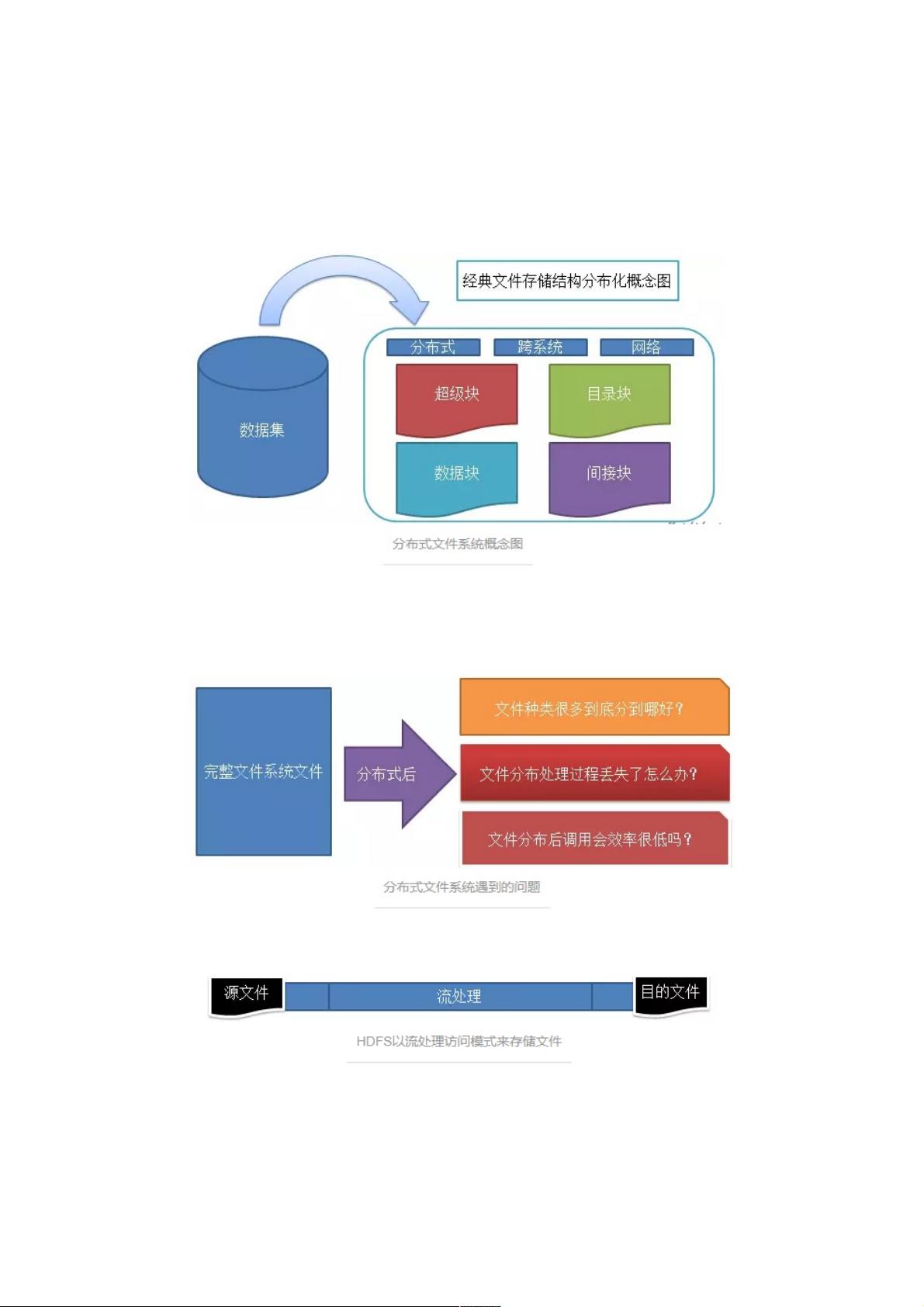
分布式文件系统概念图文件系统的三个主要组成部分:被管理的文件、文件管理相关软件、实施文件管理所需要的数据结构
将文件分布式存储后带来的问题:文件不完整,系统复杂度加大,引入网络编程
2、HDFS对文件的读取方式:流处理访问模式
HDFS以流处理访问模式来存储文件什么是流处理访问模式呢?为什么分布式文件系统场景下这种文件访问模式更合适?
操作系统中文件访问方式有好几种,常见的是随机数据访问方式,这种方式要求文件定位、查询或者修改数据的延迟比较小,
比较适合常见数据后多次查询、读写的场景,传统关系型数据库非常符合这一点。
大数据场景与关系系数据库的场景有非常大的不同。大数据的数据源通常由源生成或从数据源直接复制而来,接着长时间在此
数据集上进行各类分析,不需要搬来搬去;这种数据访问场景是典型的一次写入,多次读取的场景(写入数据只需要生成数据
的那一次,基本没有修改数据的要求,后面就是多次读取以分析),所以这种场景下的数据访问方式更适合采用流处理方式。
流处理数据访问方式试磁盘寻址开销最小化:只需要一次寻址(起始地址),然后就是连续的流式读取。硬盘的物理构造导致

剩余6页未读,继续阅读
资源评论













