

详解 Hadoop 核心架构 HDFS+MapReduce+Hbase+Hive
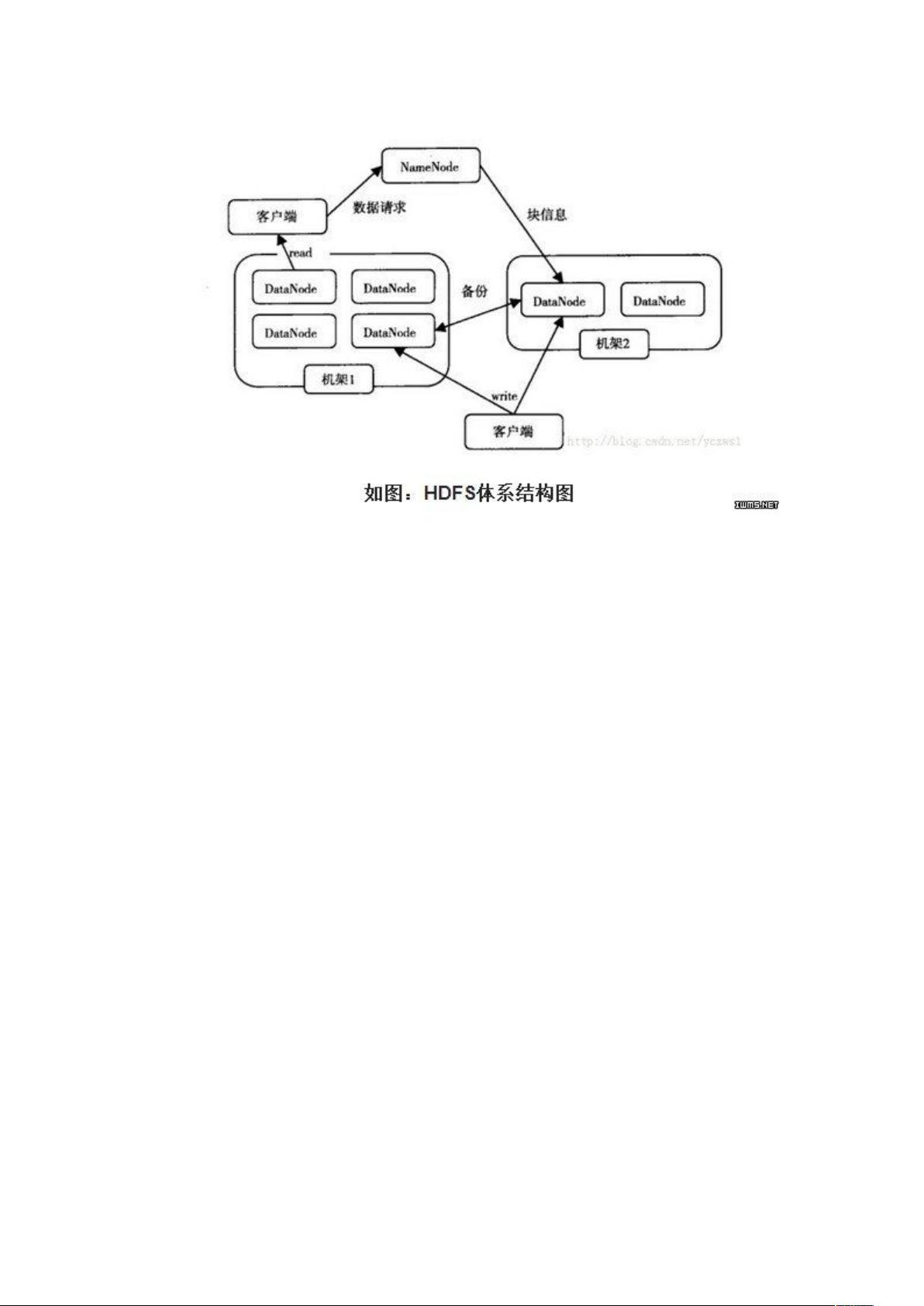
HDFS 的体系架构
整个 Hadoop 的体系结构主要是通过 HDFS 来实现对分布式存储的底层支持,并通过
MR 来实现对分布式并行任务处理的程序支持。
HDFS 采用主从(Master/Slave)结构模型,一个 HDFS 集群是由一个 NameNode
和若干个 DataNode 组成的(在最新的 Hadoop2.2 版本已经实现多个 NameNode 的配
置-这也是一些大公司通过修改 hadoop 源代码实现的功能,在最新的版本中就已经实现
了)。NameNode 作为主服务器,管理文件系统命名空间和客户端对文件的访问操作 。
DataNode 管理存储的数据。HDFS 支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组 DataNode 上。
NameNode 执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数
据块到具体 DataNode 的映射。DataNode 负责处理文件系统客户端的文件读写,并在
NameNode 的统一调度下进行数据库的创建、删除和复制工作。 NameNode 是所有
HDFS 元数据的管理者,用户数据永远不会经过 NameNode。
剩余8页未读,继续阅读
资源评论













