
一看就明白的爬虫入门讲解:基础理论篇一看就明白的爬虫入门讲解:基础理论篇
摘要:摘要:本文作者诸葛IO创始人/CEO孔淼从基础理论入手,详细讲解了爬虫内容,分为六个部分:我们的目的是什么;
内容从何而来;了解网络请求;一些常见的限制方式;尝试解决问题的思路;效率问题的取舍。
关于爬虫内容的分享,我会分成两篇,六个部分来分享,分别是:
1. 我们的目的是什么
2. 内容从何而来
3. 了解网络请求
4. 一些常见的限制方式
5. 尝试解决问题的思路
6. 效率问题的取舍
一、我们的目的是什么
一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值,内容一般分为两部分,非结构
化的文本,或结构化的文本。
1. 关于非结构化的数据
1.1 HTML文本(包含JavaScript代码)
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时候会遇到的情况,例如抓取一个网页,得到的是
HTML,然后需要解析一些常见的元素,提取一些关键的信息。HTML其实理应属于结构化的文本组织,但是又因为一
般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归
类于非结构化的数据处理中。
常见解析方式如下:
CSS选择器
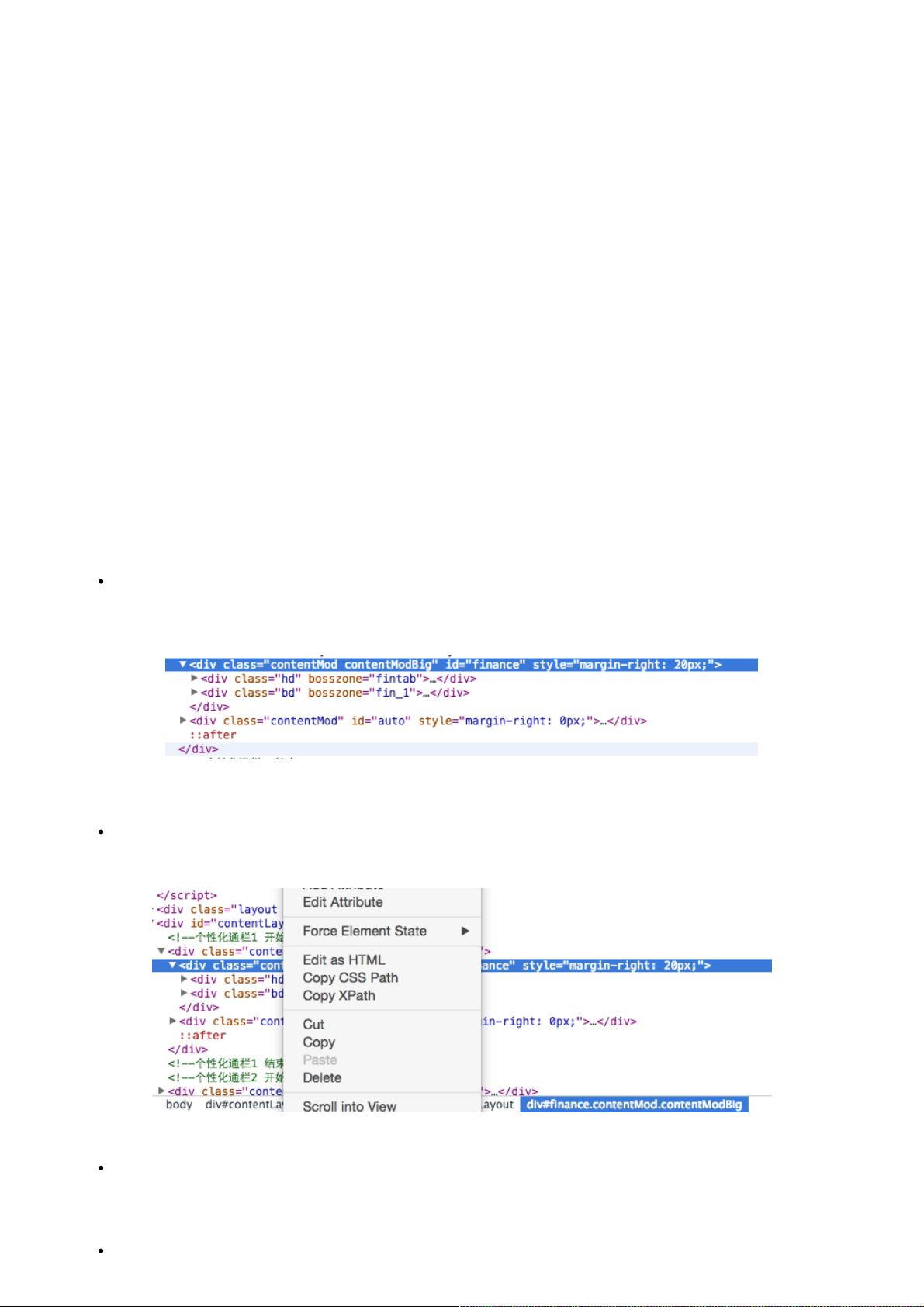
现在的网页样式比较多,所以一般的网页都会有一些CSS的定位,例如class,id等等,或者我们根据常见的节点路径
进行定位,例如腾讯首页的财经部分。
这里id就为finance,我们用css选择器,就是"#finance"就得到了财经这一块区域的html,同理,可以根据特定的css选
择器可以获取其他的内容。
XPATH
XPATH是一种页面元素的路径选择方法,利用Chrome可以快速得到,如:
copy XPATH 就能得到——//*[@id="finance"]
正则表达式
正则表达式,用标准正则解析,一般会把HTML当做普通文本,用指定格式匹配当相关文本,适合小片段文本,或者某
一串字符,或者HTML包含javascript的代码,无法用CSS选择器或者XPATH。
字符串分隔

剩余8页未读,继续阅读
资源评论













