
Python爬虫库爬虫库BeautifulSoup的介绍与简单使用实例的介绍与简单使用实例
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,本文为大家介绍下Python爬虫库BeautifulSoup的介绍
与简单使用实例其中包括了,BeautifulSoup解析HTML,BeautifulSoup获取内容,BeautifulSoup节点操作,BeautifulSoup获
取CSS属性等实例
一、介绍
BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实现网页
信息的提取。
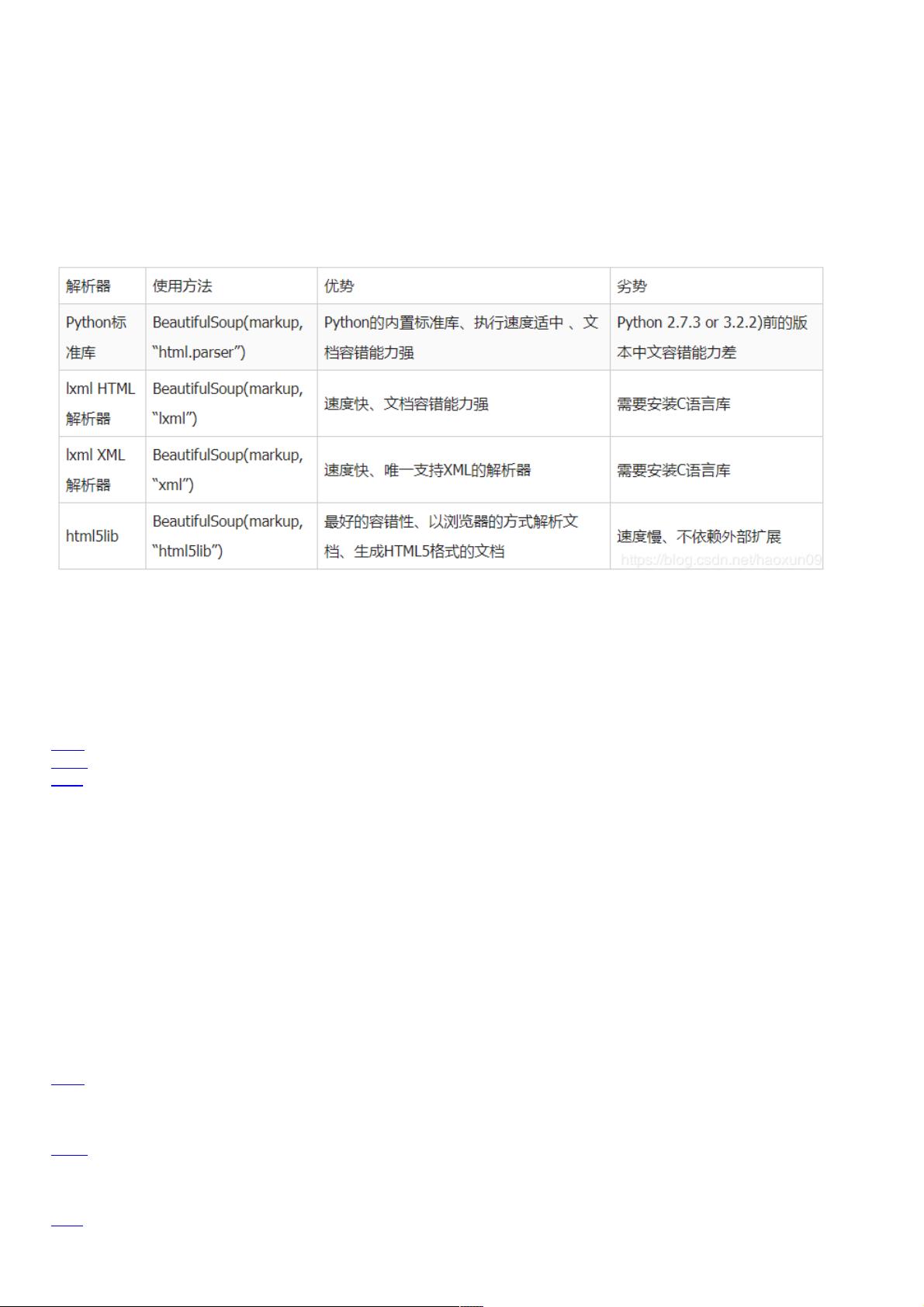
Python常用解析库
二、快速开始
给定html文档,产生BeautifulSoup对象
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc,'lxml')
输出完整文本
print(soup.prettify())
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
资源评论


weixin_38626179
- 粉丝: 4
- 资源: 959









最新资源
- 新瑞能源(储能系统解决方案提供商,东莞市新瑞能源技术有限公司)创投信息
- 《Cocos 游戏开发从入门到精通全攻略》,为你开启游戏开发的大门
- 调制信号的连续小波变换CWT时频谱图分析:二次线性Chirp调频信号、蝙蝠回声定位信号及神户地震数据的时频定位能力展示(MATLAB r2021b),调制信号的连续小波变 CWT时频谱图 程序运行环境
- 行者AI(游戏全产业链AI赋能平台,成都潜在人工智能科技有限公司)创投信息
- Java毕业设计-springboot-vue-大学生创新创业项目管理系统(源码+sql脚本+29页零基础部署图文详解+30页论文+环境工具+教程+视频+模板).zip
- Java毕业设计-springboot-vue-船运物流管理系统(源码+sql脚本+29页零基础部署图文详解+23页论文+环境工具+教程+视频+模板).zip
- Java毕业设计-springboot-vue-大学生计算机基础网络教学系统(源码+sql脚本+29页零基础部署图文详解+27页论文+环境工具+教程+视频+模板).zip
- 云骥智行(L4自动驾驶解决方案提供商,上海云骥智行智能科技有限公司)创投信息
- Java毕业设计-springboot-vue-大学生平时成绩量化管理系统(源码+sql脚本+29页零基础部署图文详解+33页论文+环境工具+教程+视频+模板).zip
- Java毕业设计-springboot-vue-大学生在线租房平台(源码+sql脚本+29页零基础部署图文详解+33页论文+环境工具+教程+视频+模板).zip
- Java毕业设计-springboot-vue-大学生就业服务平台(源码+sql脚本+29页零基础部署图文详解+40页论文+环境工具+教程+视频+模板).zip
- STM32 F103系列芯片OTA远程升级:WiFi连接下的可靠固件更新流程 升级过程包括HTTP GET指令获取服务器固件信息、版本对比、下载地址写入flash及重启更新等步骤 升级文件需进行CRC
- Java毕业设计-springboot-vue-当代中国获奖知名作家信息管理系统(源码+sql脚本+29页零基础部署图文详解+30页论文+环境工具+教程+视频+模板).zip
- Java毕业设计-springboot-vue-房屋租赁管理系统(源码+sql脚本+29页零基础部署图文详解+32页论文+环境工具+教程+视频+模板).zip
- Java毕业设计-springboot-vue-扶贫助农系统(源码+sql脚本+29页零基础部署图文详解+32页论文+环境工具+教程+视频+模板).zip
- H桥驱动circuitjs1软件仿真
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


