python scrapy爬虫代码及填坑
116 浏览量
2021-01-01
05:46:29
上传
评论
收藏 447KB PDF 举报

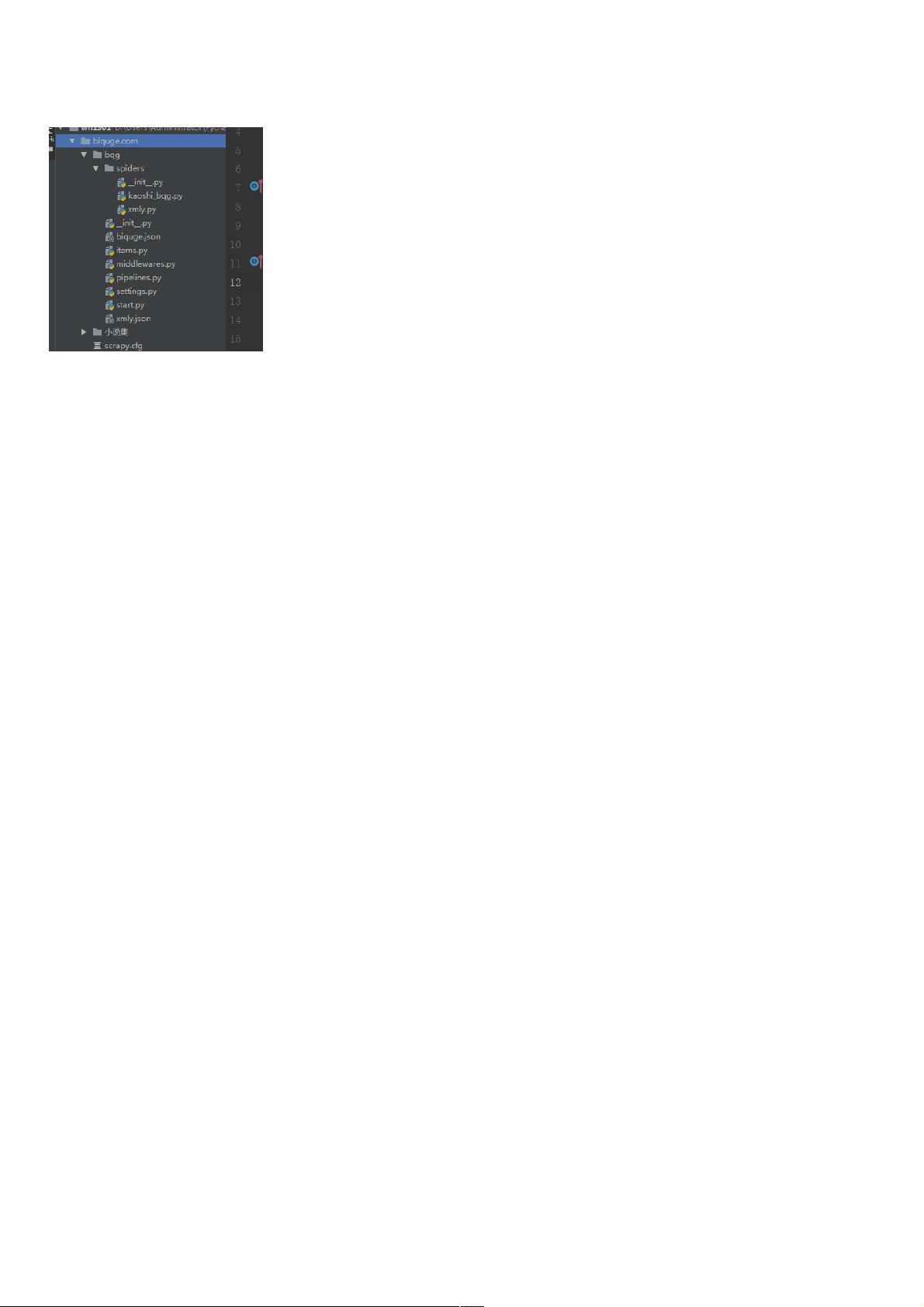
python scrapy爬虫代码及填坑爬虫代码及填坑
涉及到详情页爬取
目录结构目录结构:
kaoshi_bqg.py
import scrapy
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from ..items import BookBQGItem
class KaoshiBqgSpider(scrapy.Spider):
name = 'kaoshi_bqg'
allowed_domains = ['biquge5200.cc'] start_urls = ['https://www.biquge5200.cc/xuanhuanxiaoshuo/'] rules = (
# 编写匹配文章列表的规则
Rule(LinkExtractor(allow=r'https://www.biquge5200.cc/xuanhuanxiaoshuo/'), follow=True),
# 匹配文章详情
Rule(LinkExtractor(allow=r'.+/[0-9]{1-3}_[0-9]{2-6}/'), callback='parse_item', follow=False),
)
# 小书书名
def parse(self, response):
a_list = response.xpath('//*[@id="newscontent"]/div[1]/ul//li//span[1]/a')
for li in a_list:
name = li.xpath(".//text()").get()
detail_url = li.xpath(".//@href").get()
yield scrapy.Request(url=detail_url, callback=self.parse_book, meta={'info': name})
# 单本书所有的章节名
def parse_book(self, response):
name = response.meta.get('info')
list_a = response.xpath('//*[@id="list"]/dl/dd[position()>20]//a')
for li in list_a:
chapter = li.xpath(".//text()").get()
url = li.xpath(".//@href").get()
yield scrapy.Request(url=url, callback=self.parse_content, meta={'info': (name, chapter)})
# 每章节内容
def parse_content(self, response):
name, chapter = response.meta.get('info')
content = response.xpath('//*[@id="content"]//p/text()').getall()
item = BookBQGItem(name=name, chapter=chapter, content=content)
yield item
xmly.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import BookXMLYItem, BookChapterItem
class XmlySpider(scrapy.Spider):
name = 'xmly'
allowed_domains = ['ximalaya.com'] start_urls = ['https://www.ximalaya.com/youshengshu/wenxue/']
def parse(self, response):
div_details = response.xpath('//*[@id="root"]/main/section/div/div/div[3]/div[1]/div/div[2]/ul/li/div')
# details = div_details[::3] for details in div_details:
book_id = details.xpath('./div/a/@href').get().split('/')[-2] book_name = details.xpath('./a[1]/@title').get()
book_author = details.xpath('./a[2]/text()').get() # 作者
book_url = details.xpath('./div/a/@href').get()
url = 'https://www.ximalaya.com' + book_url
# print(book_id, book_name, book_author, url)
item = BookXMLYItem(book_id=book_id, book_name=book_name, book_author=book_author, book_url=url)
yield item
yield scrapy.Request(url=url, callback=self.parse_details, meta={'info': book_id})
def parse_details(self, response):
book_id = response.meta.get('info')
div_details = response.xpath('//*[@id="anchor_sound_list"]/div[2]/ul/li/div[2]')
for details in div_details:
chapter_id = details.xpath('./a/@href').get().split('/')[-1] chapter_name = details.xpath('./a/text()').get()
chapter_url = details.xpath('./a/@href').get()
url = 'https://www.ximalaya.com' + chapter_url
item = BookChapterItem(book_id=book_id, chapter_id=chapter_id, chapter_name=chapter_name, chapter_url=url)
yield item
item.py
import scrapy
# 笔趣阁字段
class BookBQGItem(scrapy.Item):
name = scrapy.Field()
chapter = scrapy.Field()
content = scrapy.Field()
# 喜马拉雅 字段
class BookXMLYItem(scrapy.Item):
book_name = scrapy.Field()
book_id = scrapy.Field()
book_url = scrapy.Field()
book_author = scrapy.Field()
# 喜马拉雅详情字段
class BookChapterItem(scrapy.Item):






评论0
最新资源