
用用Python下载一个网页保存为本地的下载一个网页保存为本地的HTML文件实例文件实例
今天小编就为大家分享一篇用Python下载一个网页保存为本地的HTML文件实例,具有很好的参考价值,希望对
大家有所帮助。一起跟随小编过来看看吧
我们可以用Python来将一个网页保存为本地的HTML文件,这需要用到urllib库。
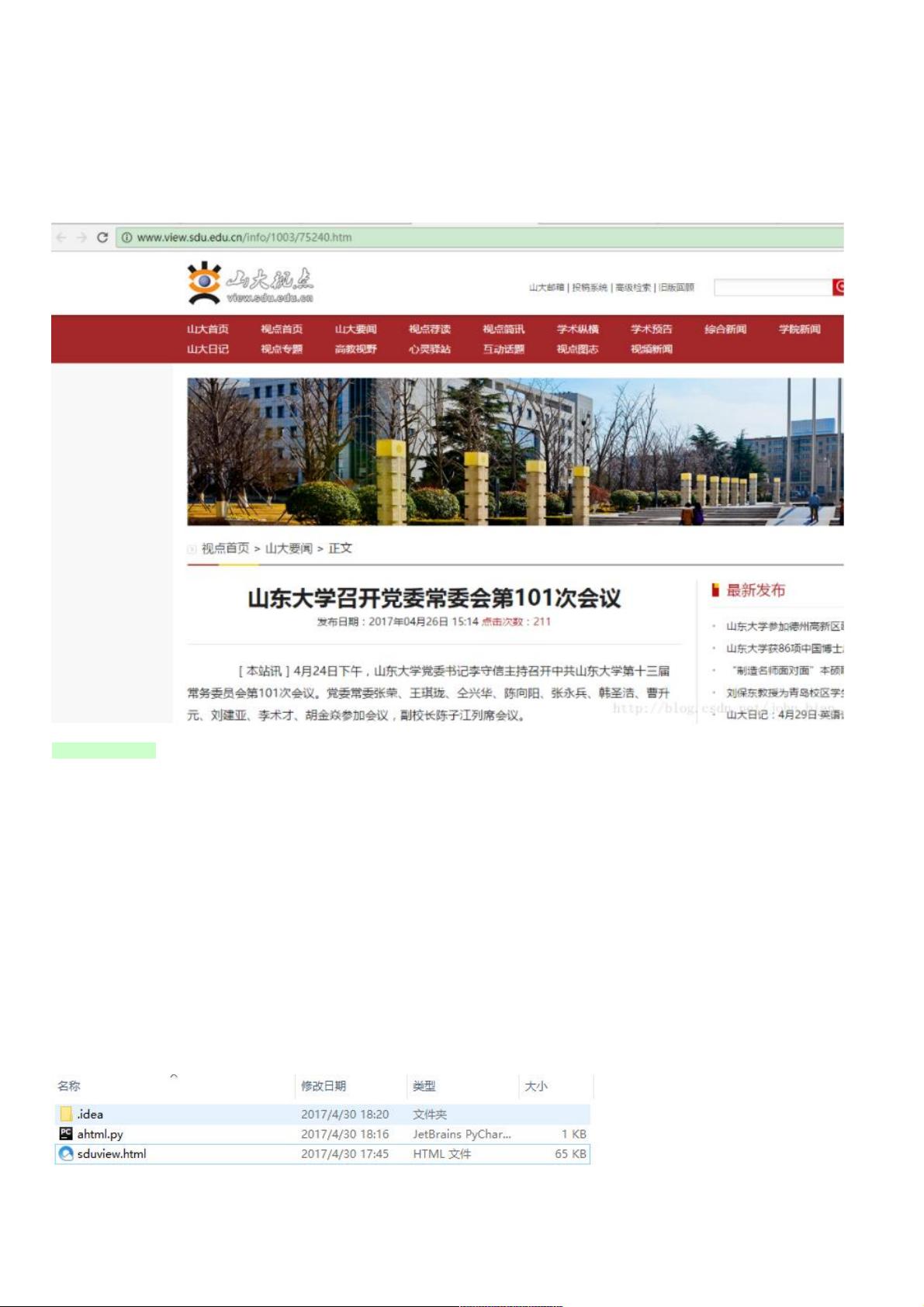
比如我们要下载山东大学新闻网的一个页面,该网页如下:比如我们要下载山东大学新闻网的一个页面,该网页如下:
实现代码如下:实现代码如下:
import urllib.request
def getHtml(url):
html = urllib.request.urlopen(url).read()
return html
def saveHtml(file_name, file_content):
# 注意windows文件命名的禁用符,比如 /
with open(file_name.replace('/', '_') + ".html", "wb") as f:
# 写文件用bytes而不是str,所以要转码
f.write(file_content)
aurl = "http://www.view.sdu.edu.cn/info/1003/75240.htm"
html = getHtml(aurl)
saveHtml("sduview", html)
print("下载成功")
打开相应的目录可以看到这个网页已经被下载保存成功了打开相应的目录可以看到这个网页已经被下载保存成功了
我们用浏览器打开这个网页文件如下我们用浏览器打开这个网页文件如下
资源评论

 a804629992021-02-03太坑了,,直接保存文字我用你??????
a804629992021-02-03太坑了,,直接保存文字我用你??????
weixin_38621250
- 粉丝: 2
- 资源: 908









最新资源
- ORACLE数据库管理系统体系结构中文WORD版最新版本
- Sybase数据库安装以及新建数据库中文WORD版最新版本
- tomcat6.0配置oracle数据库连接池中文WORD版最新版本
- hibernate连接oracle数据库中文WORD版最新版本
- MyEclipse连接MySQL的方法中文WORD版最新版本
- MyEclipse中配置Hibernate连接Oracle中文WORD版最新版本
- MyEclipseTomcatMySQL的环境搭建中文WORD版3.37MB最新版本
- hggm - 国密算法 SM2 SM3 SM4 SM9 ZUC Python实现完整代码-算法实现资源
- SQLITE操作入门中文WORD版最新版本
- Sqlite操作实例中文WORD版最新版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


