
分布式数据库的存储设计改进分布式数据库的存储设计改进
背景
在一次游泳的时候,想起一个问题,为什么 hdfs 的 namenode 没有存储块的对应节点信息,导致启动 hdfs 的时
候,datanode 需要扫描所有的数据块,再将该 datanode 上的块信息发送给 namenode,namenode 才能构建完整的元数据
信息。根据文件和数据块的多少,启动 hdfs 的时候需要几分钟到几个小时。
对比下分布式数据库,如果把记录对应的节点信息发送给 Master,那就不可想象了。所以在分布式数据库中 hdfs 的存储策略
不可取。同时最近一直被目前的分布式数据库的存储上有几个问题困扰着:
在节点数固定的时候,Hdfs 的数据是根据机器负载来决定存储在哪个节点上的,这样做的好处是数据平均分布,可以根
据机器的存储大小加权平均,并且依据机器的负载情况动态调整;目前分布式分布式数据库中做的很有限,该如何改进
呢
添加新节点的时候, Hdfs 配置好新节点指向的 namenode,然后启动新节点即可,存储过一段时间会收敛到平均,如
果想加入后马上使得数据平均分布,可以执行 rebalance 操作;而分布式数据库添加节点的时候,配置好新节点指向的
Master,然后启动新节点之后,通常还需要根据分布的规则进行数据重新分布,甚至规则也可能需要进行拆分合并扩展
等修改,分布式数据库能做到什么程度,如何做 当然如果能做到数据重新分布,rebalance 的操作也就可以加入到分布
式数据库中,两者是共通的,都是做数据的移动,数据重新分布关注过程,rebalance 关注结果。
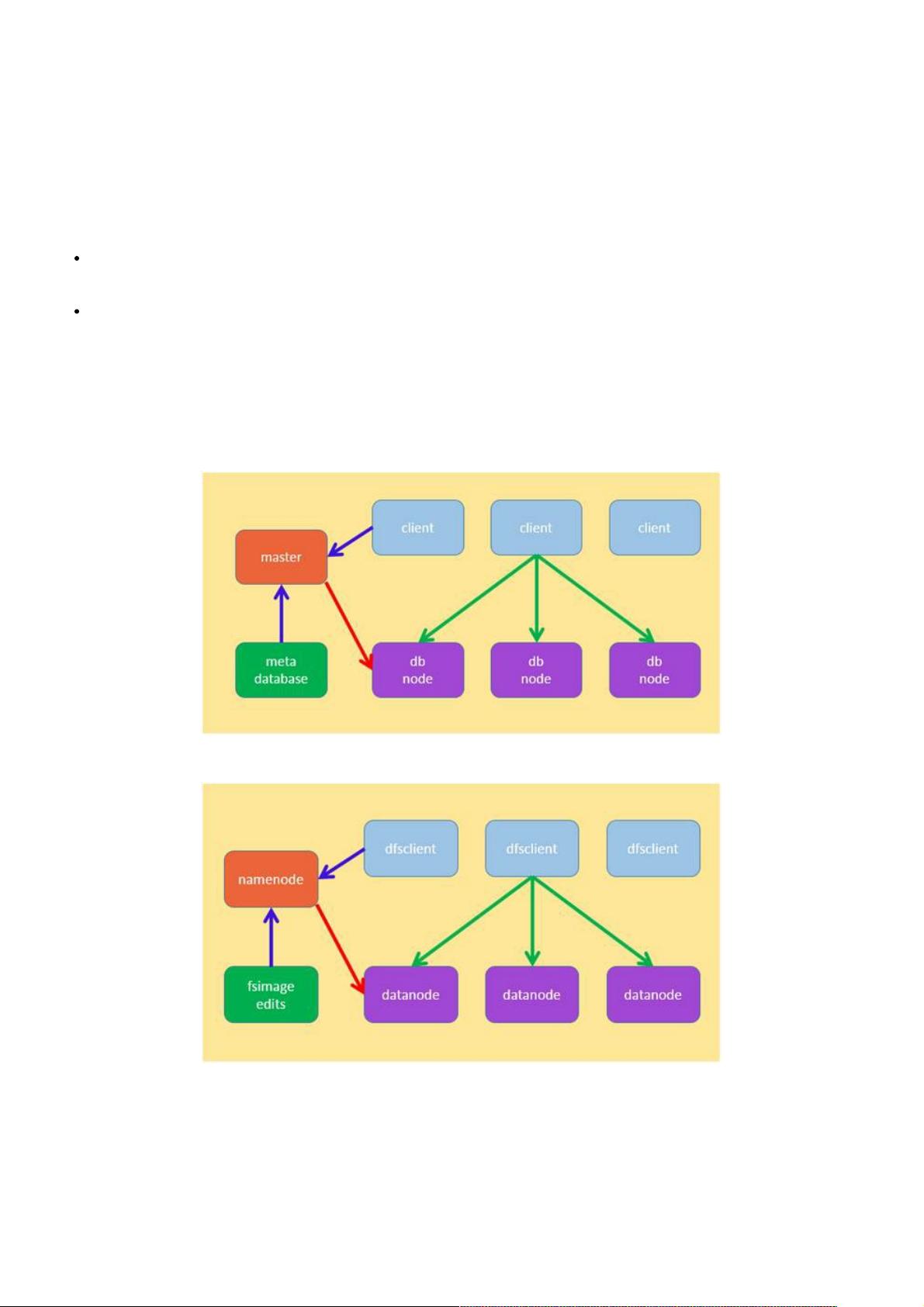
Hadoop 中的 hdfs 和分布式数据库的对比
在进一步的讨论如何改进分布式数据库的存储之前,先看看分布式数据库和 hadoop 中 hdfs 的对比。
Figure 1: 分布式数据库的架构
Figure 2:hadoop 中 hdfs 的架构
前面提到分布式数据库中把记录对应的节点信息上报给 master 是不可行的方案,这里其实是一种夸大的对比,两者中的概念
按照如下的类比更加合适:
剩余9页未读,继续阅读
资源评论













