10年大数据架构师:日访问百亿级,如何架构并优化日志系统?
28 浏览量
2021-01-27
13:48:50
上传
评论
收藏 706KB PDF 举报

10年大数据架构师:日访问百亿级,如何架构并优化日志系年大数据架构师:日访问百亿级,如何架构并优化日志系
统?统?
日志数据是最常见的一种海量数据,以拥有大量用户群体的电商平台为例,双 11 大促活动期间,它们可能每小时的日志数量
达到百亿规模,海量的日志数据暴增,随之给技术团队带来严峻的挑战。
本文将从海量日志系统在优化、部署、监控方向如何更适应业务的需求入手,重点从多种日志系统的架构设计对比;后续调优
过程:横向扩展与纵向扩展,分集群,数据分治,重写数据链路等实际现象与问题展开。
日志系统架构基准
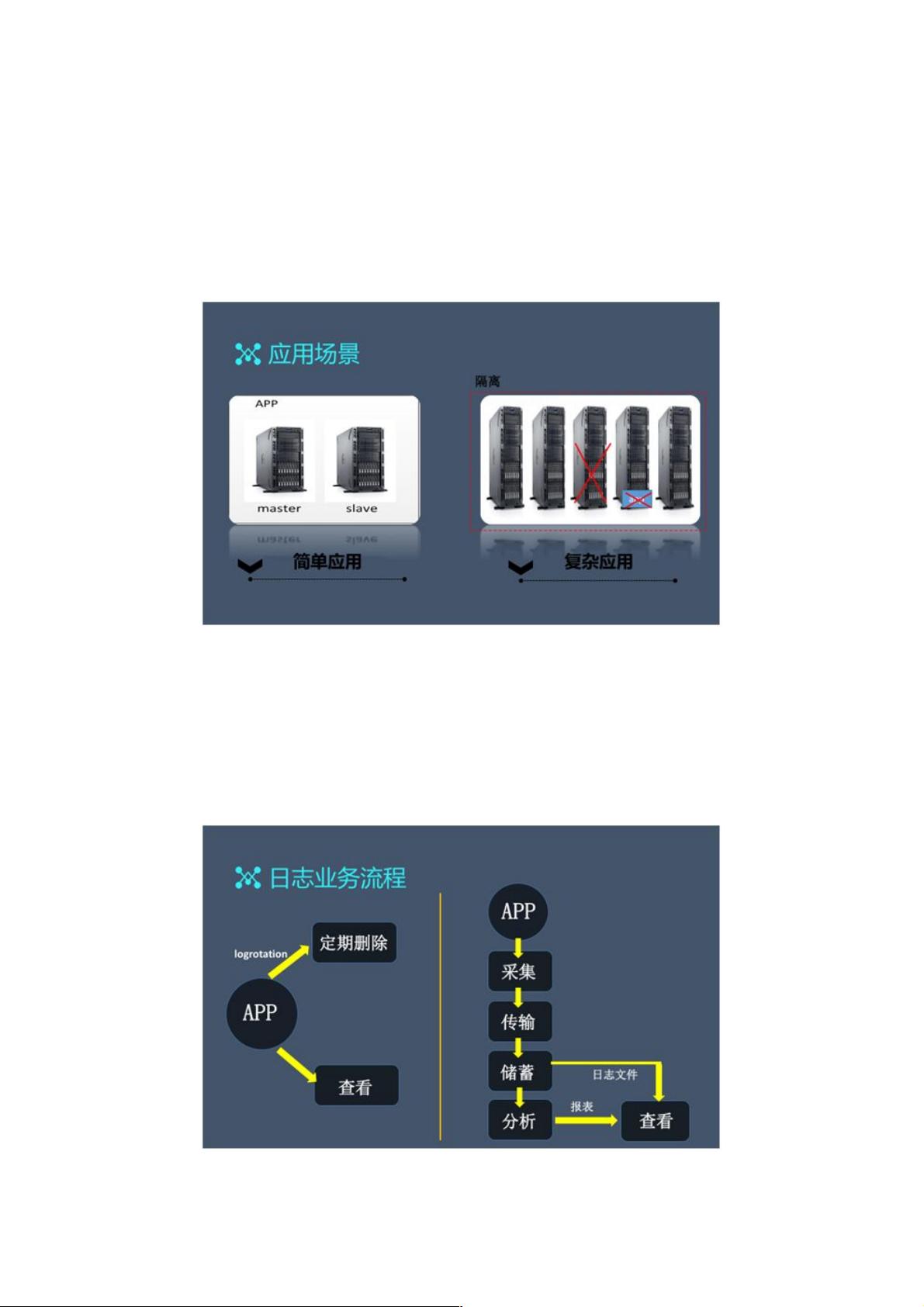
有过项目开发经验的朋友都知道:从平台的最初搭建到实现核心业务,都需要有日志平台为各种业务保驾护航。
如上图所示,对于一个简单的日志应用场景,通常会准备 master/slave 两个应用。我们只需运行一个 Shell 脚本,便可查看是
否存在错误信息。
随着业务复杂度的增加,应用场景也会变得复杂。虽然监控系统能够显示某台机器或者某个应用的错误。
然而在实际的生产环境中,由于实施了隔离,一旦在上图下侧的红框内某个应用出现了 Bug,则无法访问到其对应的日志,
也就谈不上将日志取出了。
另外,有些深度依赖日志平台的应用,也可能在日志产生的时候就直接采集走,进而删除掉原始的日志文件。这些场景给我们
日志系统的维护都带来了难度。
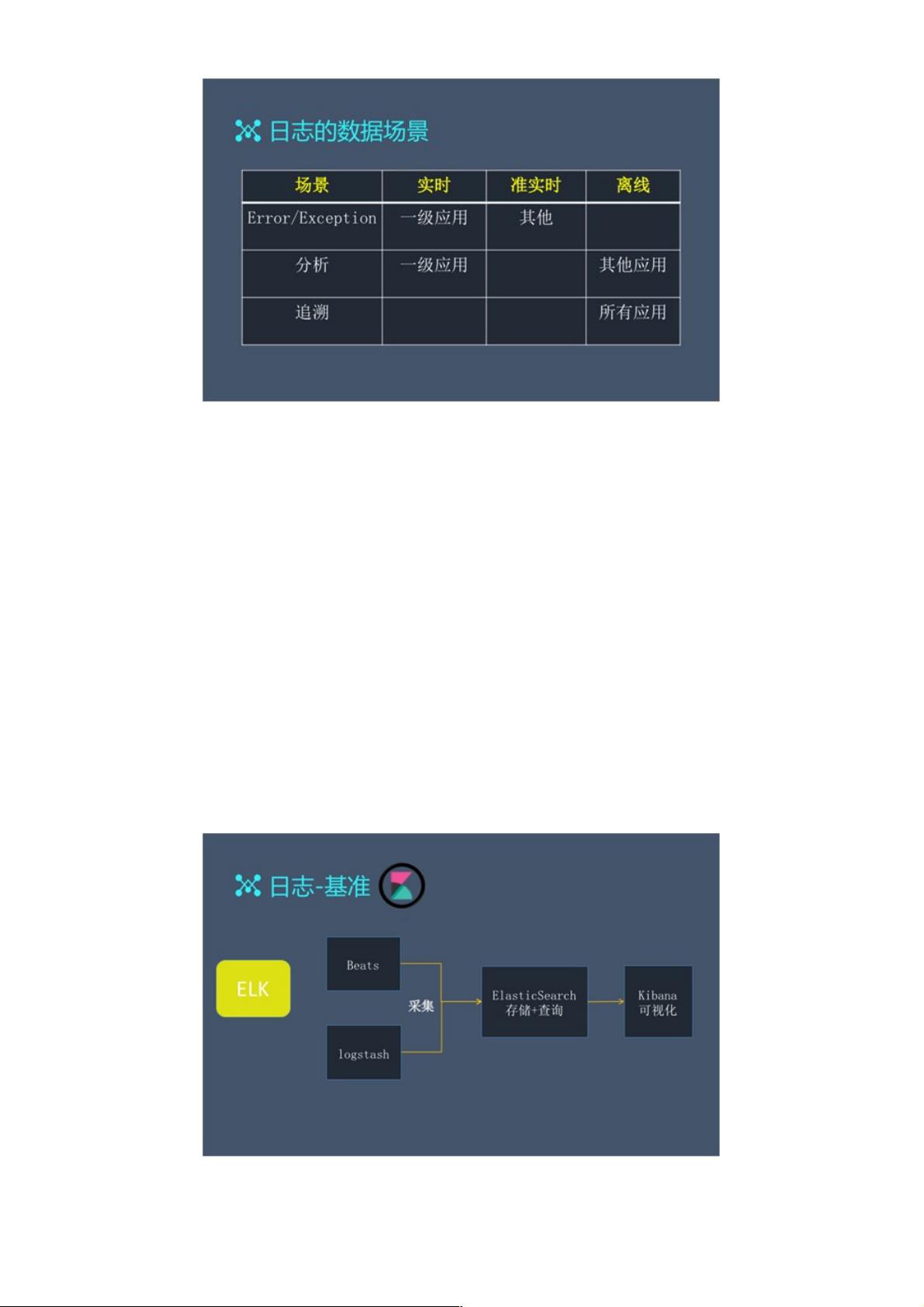
参考 Logstash,一般会有两种日志业务流程:
正常情况下的简单流程为:应用产生日志→根据预定义的日志文件大小或时间间隔,通过执行 Logrotation,不断刷新出新的
文件→定期查看→定期删除。
剩余12页未读,继续阅读













评论0