DataWhale——Task01:Pandas基础
118 浏览量
2020-12-21
09:00:18
上传
评论
收藏 566KB PDF 举报

DataWhale——Task01::Pandas基础基础
DataWhale::Task01 Pandas基础基础
学习内容分为以下两个部分:
理论部分
掌握常见文件格式的读写操作
理解并熟悉 Series 和 DataFrame 的重要属性和重要方法
掌握各类排序(索引排序和值排序、单级排序和多级排序)
练习部分
《权利的游戏》剧本数据集分析
科比投篮数据集分析
—————————————–进入正题—————————————–
(一)两个库(一)两个库
NumPy
NumPy是一个科学计算基础库其中提供了许多向量和矩阵操作,能让用户轻松完成最优化、线性代数、积分、插值、特殊函数、傅里叶变换、信号处理和图像处理、常微分方程求解
以及其他科学与工程中常用的计算,不仅方便易用而且效率更高。
pandas
它是基于 Numpy 库的,主要包含两种数据结构:Series和DataFrame。
导入库的指令:
import pandas as pd
import numpy as np
(二)文件读取和写入(二)文件读取和写入
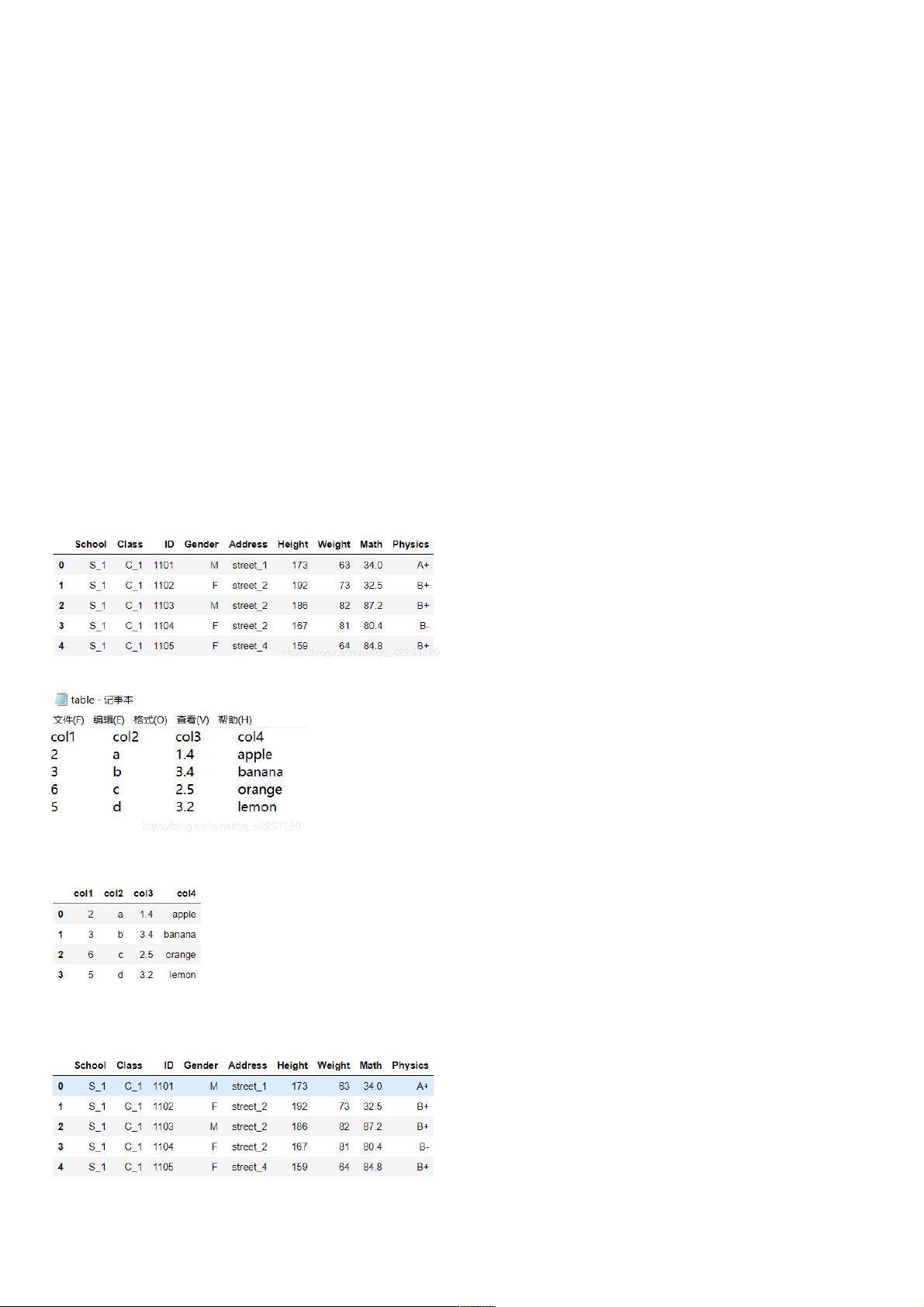
1. 读取读取
((a))csv格式格式
调用Pandas库的read_csv()函数读取csv文件:
df = pd.read_csv('data/table.csv')
df.head()
((b))txt格式格式
调用pandas库的read_table()函数读取txt文件:
df_txt = pd.read_table('data/table.txt') #可设置sep分隔符参数
df_txt
((c))xls或或xlsx格式格式
调用pandas库的read_excel()函数(如果没有安装xlrd包需要先安装包):
df_excel = pd.read_excel('data/table.xlsx')
df_excel.head()
2. 写入写入
((a))csv格式格式
将一个DataFrame的数据写入csv文件:
df.to_csv('meal_order.csv',encoding='utf_8')


剩余11页未读,继续阅读













评论0