2022/3/6 4.3 pandas读写文件
In [ ]: # 引入相关模块
import numpy as np # pandas和numpy 常常结合在一起使用,导入numpy库
import pandas as pd # 导入pandas库
print (pd.__version__) # 打印pandas版本信息
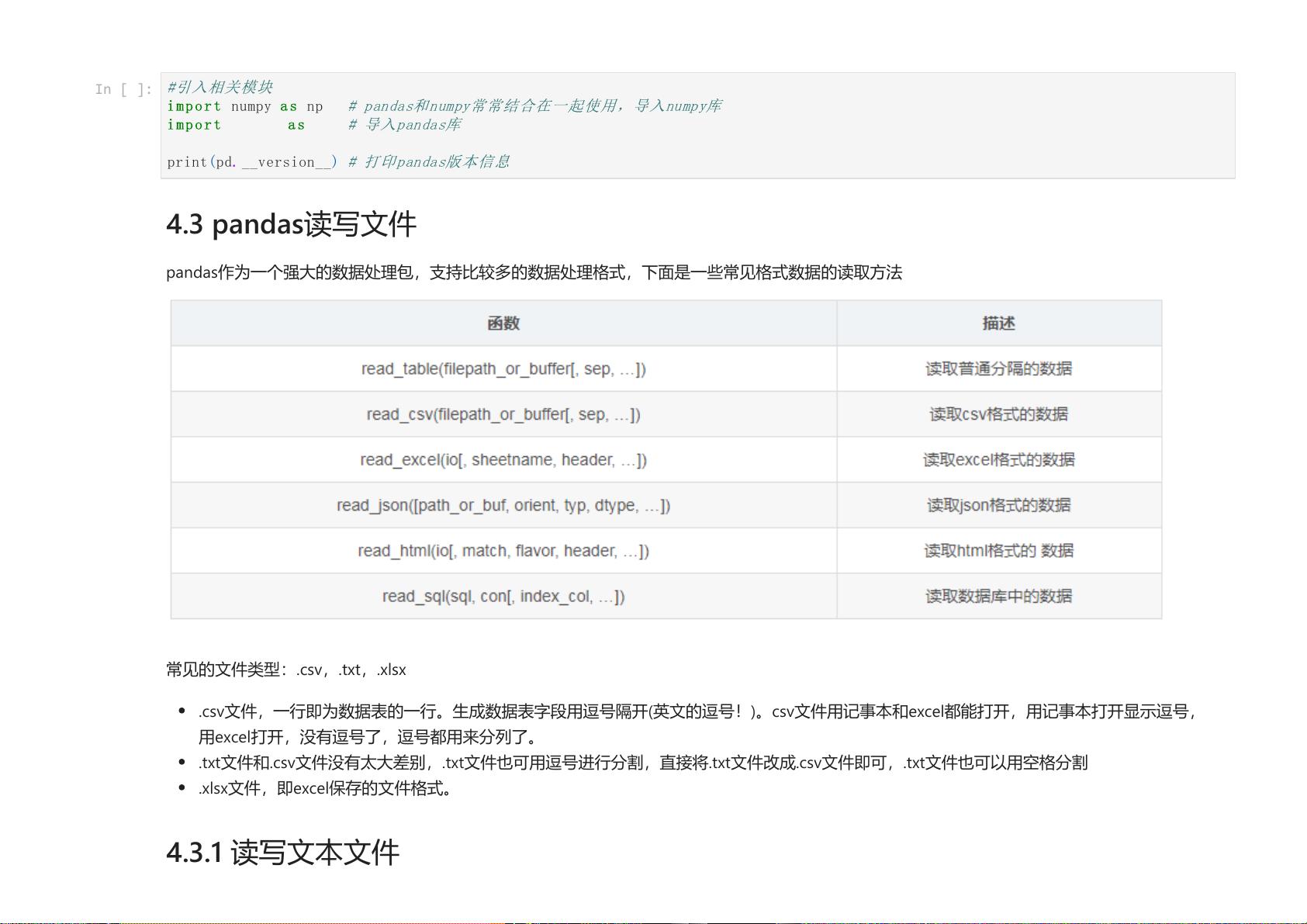
4.3 pandas读写文件
pandas作为一个强大的数据处理包,支持比较多的数据处理格式,下面是一些常见格式数据的读取方法
常见的文件类型:.csv ,.txt ,.xlsx
.csv文件,一行即为数据表的一行。生成数据表字段用逗号隔开(英文的逗号!)。csv文件用记事本和excel都能打开,用记事本打开显示逗号,
用excel打开,没有逗号了,逗号都用来分列了。
.txt文件和.csv文件没有太大差别,.txt文件也可用逗号进行分割,直接将.txt文件改成.csv文件即可,.txt文件也可以用空格分割
.xlsx文件,即excel保存的文件格式。
4.3.1 读写文本文件
file:///D:/Python39/envs/pydata/教材配套代码/模块四
在Python数据分析领域,pandas库是不可或缺的一部分,它提供了丰富的数据操作和分析功能。这篇文档主要探讨了如何使用pandas进行文件的读写操作,尤其是针对.csv、.txt和.xlsx等常见格式的数据。
要使用pandas进行数据处理,需要先引入必要的库。在示例中,我们看到`import numpy as np`和`import pandas as pd`这两行代码,它们分别导入了numpy和pandas库。numpy是科学计算的基础库,常与pandas一起用于处理数值型数据;pandas则是一个强大的数据处理和分析工具,它的版本可以通过`pd.__version__`来查看。
pandas支持多种文件格式的读写。其中,`.csv`文件是最常见的,它以逗号分隔每一列的数据,可以使用记事本或Excel打开。`.txt`文件与.csv文件类似,也可以用逗号分隔,或者使用空格。`.xlsx`文件是Excel的标准格式,包含了更复杂的数据结构和样式。
读取.csv文件,可以使用`pandas.read_csv()`函数,例如:
```python
df = pd.read_csv('file_path.csv')
```
同样,写入.csv文件可以使用`DataFrame.to_csv()`方法,如下所示:
```python
df.to_csv('output_file.csv', index=False)
```
这里的`index=False`表示不将索引写入文件,如果省略,则会将行索引一并保存。
对于.txt文件,读取和写入的操作与.csv文件类似,只是使用的函数分别是`read_table()`和`to_csv()`,不过通常可以直接将.txt文件当作.csv文件处理。
对于.xlsx文件,pandas提供了`read_excel()`和`to_excel()`函数。例如:
```python
df_excel = pd.read_excel('file_path.xlsx')
df_excel.to_excel('output_file.xlsx', index=False)
```
在存储时,如果需要指定编码(如GBK),可以在`to_csv()`或`to_excel()`方法中设置`encoding`参数。
在文档给出的例子中,创建了一个包含学生信息的DataFrame `dftest`,然后使用`to_csv()`将其保存为.csv文件。通过设置不同的参数,我们可以控制是否保存列名(header)、索引(index)以及编码方式。
此外,`numpy.loadtxt()`函数也被用到,它可以读取.csv文件,并将其内容转换为numpy数组。数组可以快速地进行数值计算,但失去了pandas DataFrame的列名和索引等结构信息。
总结来说,pandas库在Python数据分析中扮演着重要角色,它的读写文件功能强大且灵活,能够方便地处理各种类型的数据文件。无论是日常的数据整理还是复杂的分析任务,pandas都是一个非常实用的工具。理解并熟练掌握这些基本操作,对于提高数据分析效率至关重要。







评论11
最新资源