浅析分布式系统
51 浏览量
2021-01-27
11:47:25
上传
评论
收藏 962KB PDF 举报


浅析分布式系统浅析分布式系统
承载量是分布式系统存在的原因
当一个互联网业务获得大众欢迎的时候,最显著碰到的技术问题,就是服务器非常繁忙。当每天有1000万个用户访问你的网
站时,无论你使用什么样的服务器硬件,都不可能只用一台机器就承载的了。因此,在互联网程序员解决服务器端问题的时
候,必须要考虑如何使用多台服务器,为同一种互联网应用提供服务,这就是所谓“分布式系统”的来源。
然而,大量用户访问同一个互联网业务,所造成的问题并不简单。从表面上看,要能满足很多用户来自互联网的请求,最基本
的需求就是所谓性能需求:用户反应网页打开很慢,或者网游中的动作很卡等等。而这些对于“服务速度”的要求,实际上包含
的部分却是以下几个:高吞吐、高并发、低延迟和负载均衡。
高吞吐,意味着你的系统,可以同时承载大量的用户使用。这里关注的整个系统能同时服务的用户数。这个吞吐量肯定是不可
能用单台服务器解决的,因此需要多台服务器协作,才能达到所需要的吞吐量。而在多台服务器的协作中,如何才能有效的利
用这些服务器,不致于其中某一部分服务器成为瓶颈,从而影响整个系统的处理能力,这就是一个分布式系统,在架构上需要
仔细权衡的问题。
高并发是高吞吐的一个延伸需求。当我们在承载海量用户的时候,我们当然希望每个服务器都能尽其所能的工作,而不要出现
无谓的消耗和等待的情况。然而,软件系统并不是简单的设计,就能对同时处理多个任务,做到“尽量多”的处理。很多时候,
我们的程序会因为要选择处理哪个任务,而导致额外的消耗。这也是分布式系统解决的问题。
低延迟对于人数稀少的服务来说不算什么问题。然而,如果我们需要在大量用户访问的时候,也能很快的返回计算结果,这就
要困难的多。因为除了大量用户访问可能造成请求在排队外,还有可能因为排队的长度太长,导致内存耗尽、带宽占满等空间
性的问题。如果因为排队失败而采取重试的策略,则整个延迟会变的更高。所以分布式系统会采用很多请求分拣和分发的做
法,尽快的让更多的服务器来出来用户的请求。但是,由于一个数量庞大的分布式系统,必然需要把用户的请求经过多次的分
发,整个延迟可能会因为这些分发和转交的操作,变得更高,所以分布式系统除了分发请求外,还要尽量想办法减少分发的层
次数,以便让请求能尽快的得到处理。
由于互联网业务的用户来自全世界,因此在物理空间上可能来自各种不同延迟的网络和线路,在时间上也可能来自不同的时
区,所以要有效的应对这种用户来源的复杂性,就需要把多个服务器部署在不同的空间来提供服务。同时,我们也需要让同时
发生的请求,有效的让多个不同服务器承载。所谓的负载均衡,就是分布式系统与生俱来需要完成的功课。
由于分布式系统,几乎是解决互联网业务承载量问题,的最基本方法,所以作为一个服务器端程序员,掌握分布式系统技术就
变得异常重要了。然而,分布式系统的问题,并非是学会用几个框架和使用几个库,就能轻易解决的,因为当一个程序在一个
电脑上运行,变成了又无数个电脑上同时协同运行,在开发、运维上都会带来很大的差别。
分布式系统提高承载量的基本手段
分层模型(路由、代理)
使用多态服务器来协同完成计算任务,最简单的思路就是,让每个服务器都能完成全部的请求,然后把请求随机的发给任何一
个服务器处理。最早期的互联网应用中,DNS轮询就是这样的做法:当用户输入一个域名试图访问某个网站,这个域名会被
解释成多个IP地址中的一个,随后这个网站的访问请求,就被发往对应IP的服务器了,这样多个服务器(多个IP地址)就能一
起解决处理大量的用户请求。
然而,单纯的请求随机转发,并不能解决一切问题。比如我们很多互联网业务,都是需要用户登录的。在登录某一个服务器
后,用户会发起多个请求,如果我们把这些请求随机的转发到不同的服务器上,那么用户登录的状态就会丢失,造成一些请求
处理失败。简单的依靠一层服务转发是不够的,所以我们会增加一批服务器,这些服务器会根据用户的Cookie,或者用户的
登录凭据,来再次转发给后面具体处理业务的服务器。
除了登录的需求外,我们还发现,很多数据是需要数据库来处理的,而我们的这些数据往往都只能集中到一个数据库中,否则
在查询的时候就会丢失其他服务器上存放的数据结果。所以往往我们还会把数据库单独出来成为一批专用的服务器。
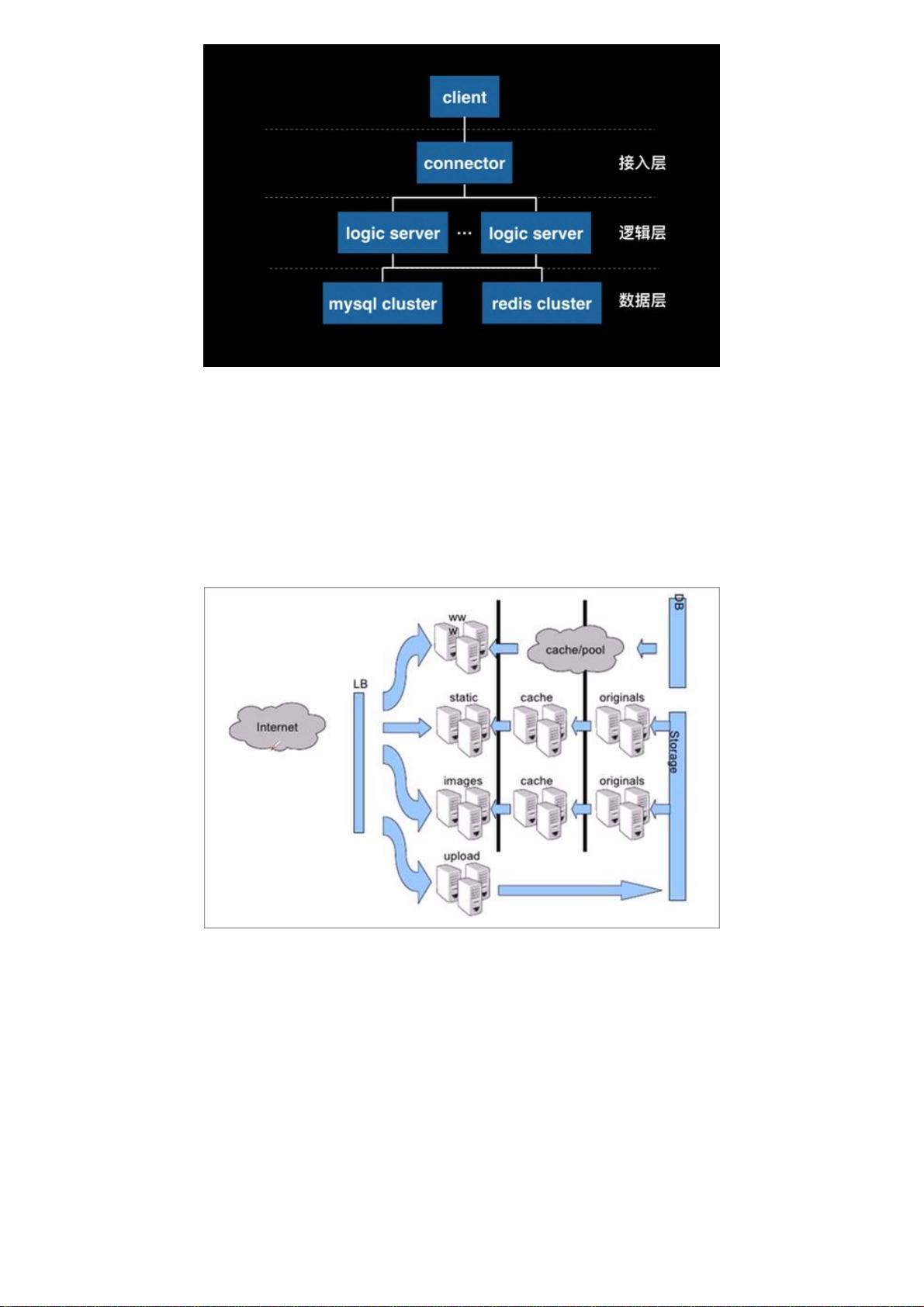
至此,我们就会发现,一个典型的三层结构出现了:接入、逻辑、存储。然而,这种三层结果,并不就能包医百病。例如,当
我们需要让用户在线互动(网游就是典型) ,那么分割在不同逻辑服务器上的在线状态数据,是无法知道对方的,这样我们
就需要专门做一个类似互动服务器的专门系统,让用户登录的时候,也同时记录一份数据到它那里,表明某个用户登录在某个
服务器上,而所有的互动操作,要先经过这个互动服务器,才能正确的把消息转发到目标用户的服务器上。
剩余14页未读,继续阅读













评论0