
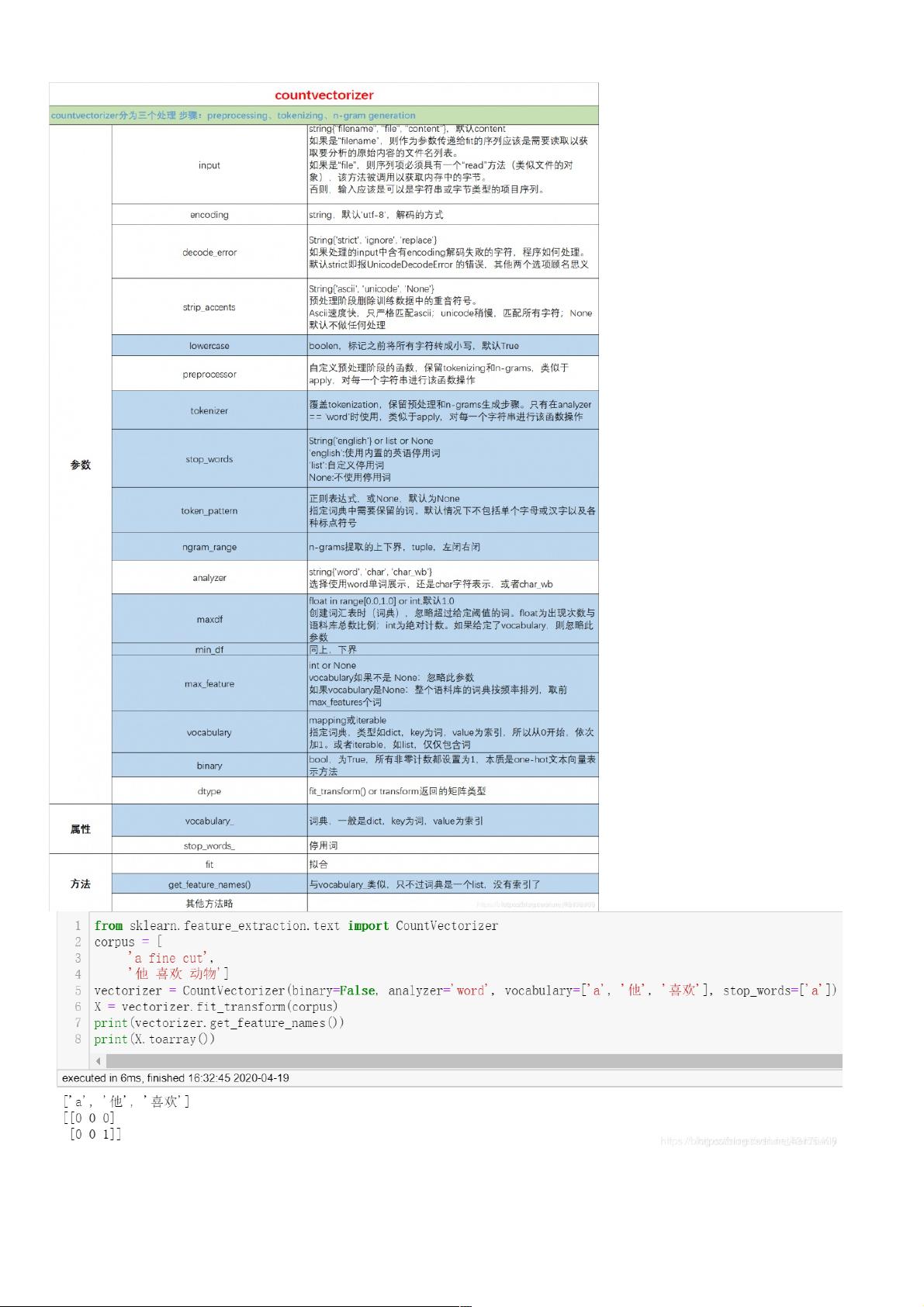
CountVectorizer参数学习参数学习
指定vocabulary,此时tokenizer/token_pattern/stop_words/max_df等都无效,即和分词有关的参数都无效。可以看到最终生成的词典只有我们参数中指定的a/他/喜欢
为什么会这样呢?我们去研究一下源代码(sklearn/feature_extraction/text.py):
其中CountVectorizer中的fit_transform的源代码如下所示,需要重点关注的是 self._validate_vocabulary()和self.count_vocab(raw_documents,self.fixed_vocabulary)
def fit_transform(self, raw_documents, y=None):
if isinstance(raw_documents, six.string_types):
raise ValueError(
资源评论


weixin_38515270
- 粉丝: 3
- 资源: 945









最新资源
- 资料阅读器(先下载解压) 5.0.zip
- 人、垃圾、非垃圾检测18-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 440379878861684smart-parking.zip
- 金智维RPA server安装包
- 二维码图形检测6-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord数据集合集.rar
- Matlab绘制绚丽烟花动画迎新年
- 厚壁圆筒弹性应力计算,过盈干涉量计算
- 实验八:实验程序202210409116武若豪.zip
- 网络实践11111111111111
- GO编写图片上传代码.txt
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


