基于双向邻居修正的局部异常因子算法
199 浏览量
2021-01-13
19:18:51
上传
评论
收藏 1.12MB PDF 举报


2020 年 8 月 Journal on Communications August 2020
第 41 卷第 8 期 通 信 学 报 Vol.41
No.8
基于双向邻居修正的局部异常因子算法
杨晓晖,刘晓明
(河北大学网络空间安全与计算机学院,河北 保定 071002)
摘 要:针对现有离群点检测算法存在参数选取困难、效率差和精度低等问题,提出了基于双向邻居修正的局部
异常因子算法。为了解决所提问题,首先提出了基于双向邻居的搜索算法,降低邻居搜索占用时间,然后使用双
向邻居的修剪算法减少参数输入以及不必要的异常值计算。同时提出了基于双向邻居的修正因子,并利用反向邻
居进一步提高计算精度。实验结果表明,所提算法减少了参数选取,提高了时间效率,同时基于双向邻居的修正
因子使算法在合成数据集和 UCI 数据集上的准确率更高。
关键词:异常值检测;局部异常因子;双向邻居;修正因子
中图分类号:TP181
文献标识码:A
doi: 10.11959/j.issn.1000−436x.2020119
Local outlier factor algorithm based on correction of
bidirectional neighbor
YANG Xiaohui, LIU Xiaoming
School of Cyber Security and Computer, Hebei University, Baoding 071002, China
Abstract: A local outlier factor algorithm based on bidirectional neighbor correction was proposed to solve the problems
of existing outlier detection algorithms such as difficulty in parameter selection, poor efficiency and low accuracy. The
bidirectional neighbor searching algorithm was used to reduce the neighbor search time. Then the bidirectional neighbor
pruning algorithm was used to reduce the number of parameters and unnecessary calculations. And the correction factor
based on bidirectional neighbors was used to improve the calculation accuracy. Experimental results show that the pro-
posed algorithm has better performance in parameter selection and time efficiency than other outlier detection methods.
The correction factor improves the accuracy of the algorithm, in the synthetic data set and UCI data set.
Key words: outlier detection, local outlier factor, bidirectional neighbor, correction factor
1 引言
离群值检测是数据挖掘领域的热门话题,其任
务是识别与大多数对象明显不同的数据对象,这类
数据与其他现有数据表现形式不一致,通常包含部
分关键信息,且信息不易被发现,但是具有很高的
研究和应用价值。离群挖掘是数据挖掘和数据分析
的重要分支,已广泛应用于欺诈检测
[1]
、垃圾邮件
检测
[2]
、交通异常
[3]
、网络流量异常检测
[4]
、入侵检
测
[5-6]
和社交网络异常用户发现
[7]
等领域。大多数现
有的解决方案通常从全局角度来识别离群值,这不
适用于高维和海量数据集
[8-9]
。随着获取信息技术的
发展和高维、海量数据的爆炸性增长,采用传统方
法进行全局异常值检测将非常困难。
2 相关工作
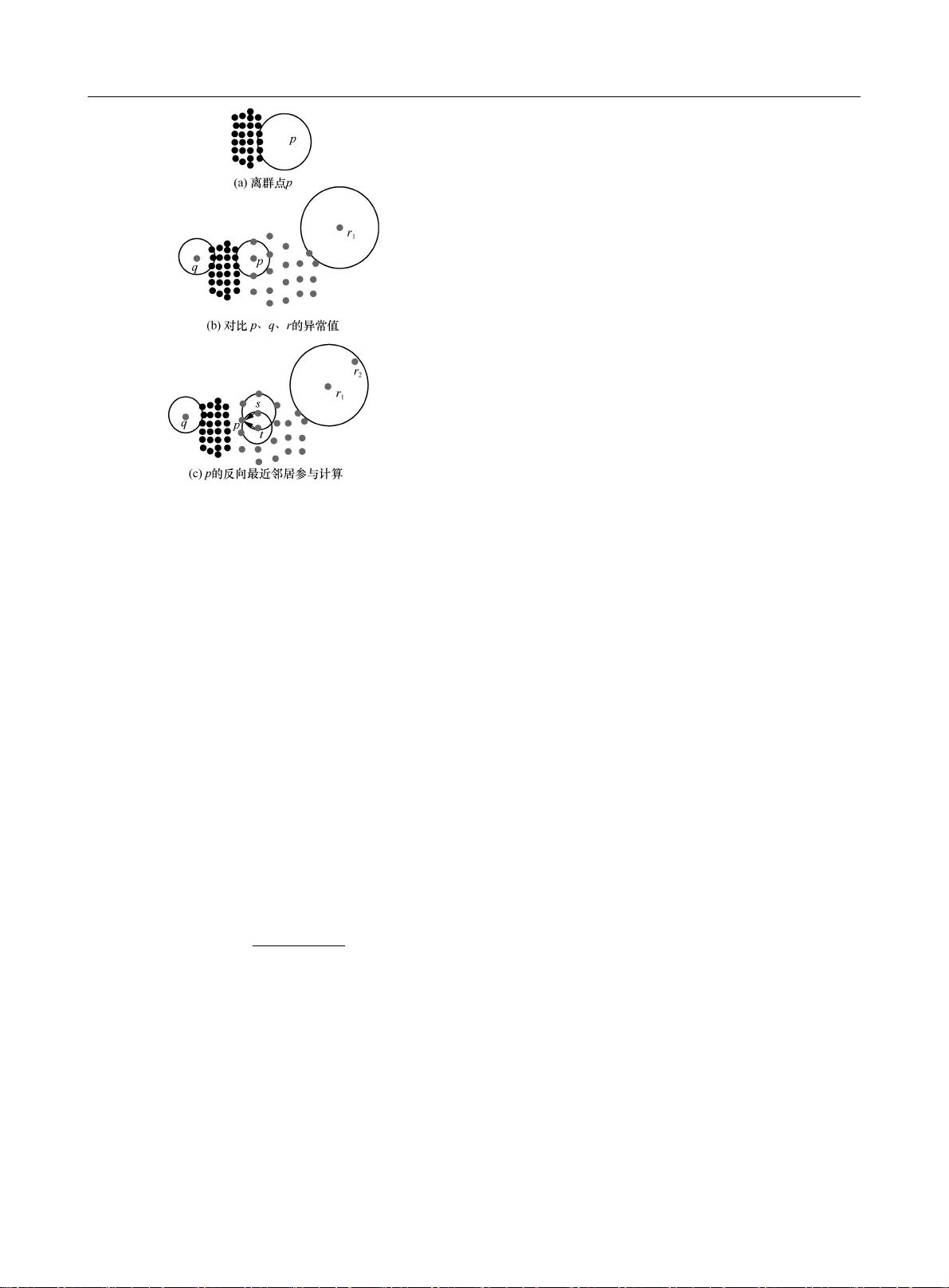
离群值,即数据中的不合理值,可以由不同的
机制产生。现有检测算法主要分为基于统计、基于
深度、基于聚类、基于距离和基于密度的算法。
在基于统计的离群值检测算法中,偏离标准分
收稿日期:2020−01−15;修回日期:2020−04−30
基金项目:国家重点研发计划基金资助项目(No.2017YFB0802300)
Foundation Item: The National Key Research and Development Program of China (No.2017YFB0802300)

剩余10页未读,继续阅读
资源评论













