BERT模型实战1
需积分: 0 165 浏览量
2022-08-03
21:13:44
上传
评论 1
收藏 838KB PDF 举报

视频:https://edu.csdn.net/course/play/26498/334600
BERT
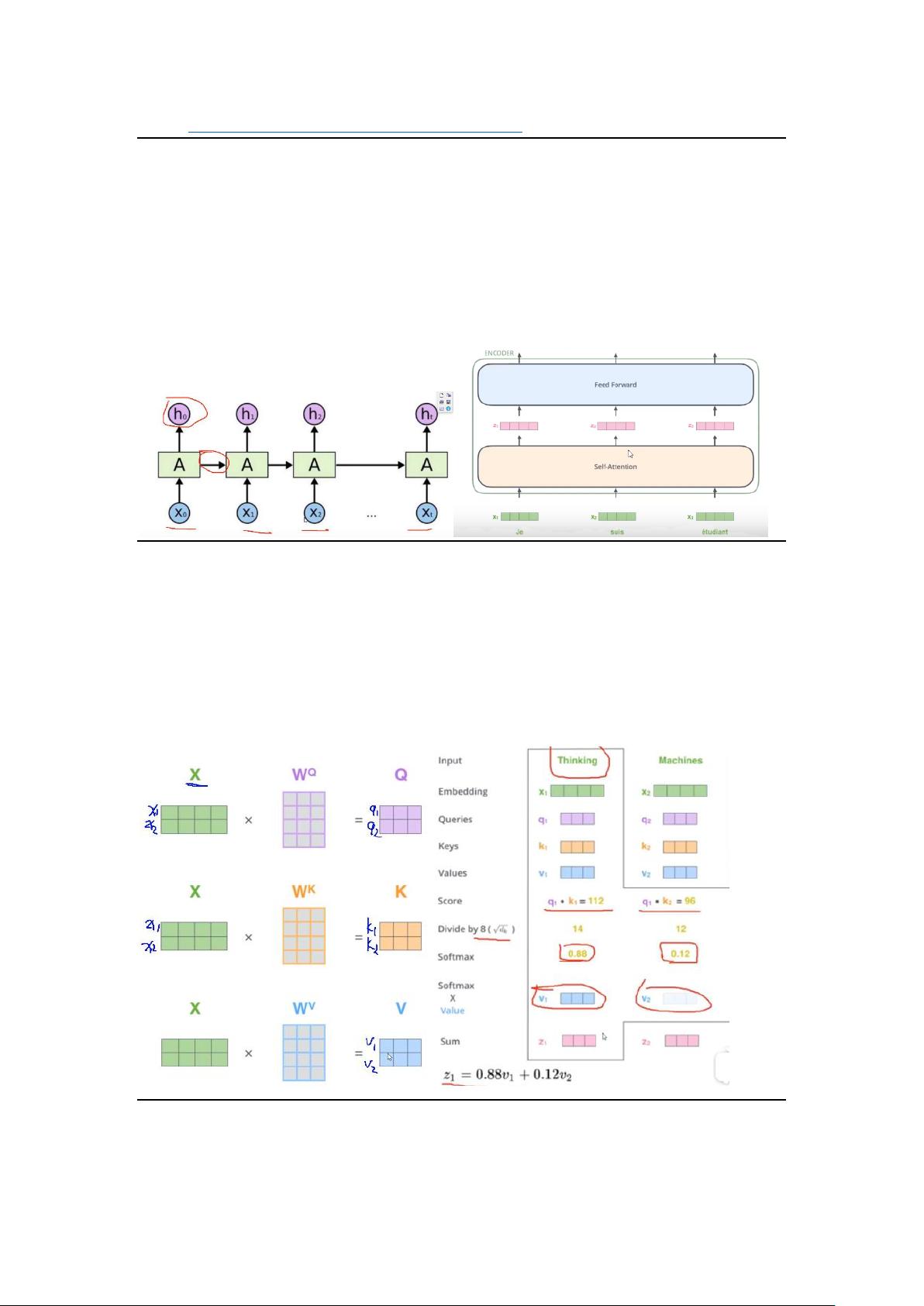
BERT 基本组成为 Seq2Seq 网络:输入和输出都为序列的网络,中间为 Transformer
为什么要 Transformer?因为传统 RNN 网络每个循环体都需要上一个循环体的中间结果,
无法并行运算(不独立);采用 Self-Attention 机制并行计算,取代 RNN
为什么不用 word2vec?相同的词表达含义一样,实际上不是这样的
Self-Attention 机制:在不同的语境下不同的词有不同的权重。
方法:词->向量编码 x1->权重向量编码 z1
预先定义三个矩阵(权重)Wq、Wk、Wv,分别表示要被查询的、等待被查的和实际的特征
信息,使输入词向量分别与三个矩阵进行运算。然后用 softmax 来进行归一化,求得每个词
在当前句子中占有的权重(影响程度)
若要查询第一个词与每个词的关系,则用 Wq1*Wk1(内积:若无关系则内积为 0)表示与
第一个词的关系,Wq1*Wk2 表示与第二个词的关系,以此类推
Multi-headed 机制:提取多种词向量特征(上述只是提取一种特征)
通过多个头机制(一般 8 个)得到多个特征表达,然后将所有特征拼接起来,再加一层全连













评论0