Project5-goodexamples-2021fall-by廖铭骞1
需积分: 0 134 浏览量
2022-08-03
17:45:39
上传
评论
收藏 2.14MB PDF 举报


CS205 C/ C++ Programming - Project5
name: 廖铭骞
SID: 12012919
CS205 C/ C++ Programming - Project5
name: 廖铭骞
SID: 12012919
Part1 - Analysis
CNN基本组成
张量(tensor)
神经元和神经层(neuron and layer)
核权重以及核偏差(kernel weights and biases)
CNN层次结构
输入层(Input Layer)
卷积层(Convolutional Layers)
激活层(Activative Layer)
池化层(Pooling Layers)
扁平层(Flatten Layer)
图像读入与转换
卷积层分析与实现
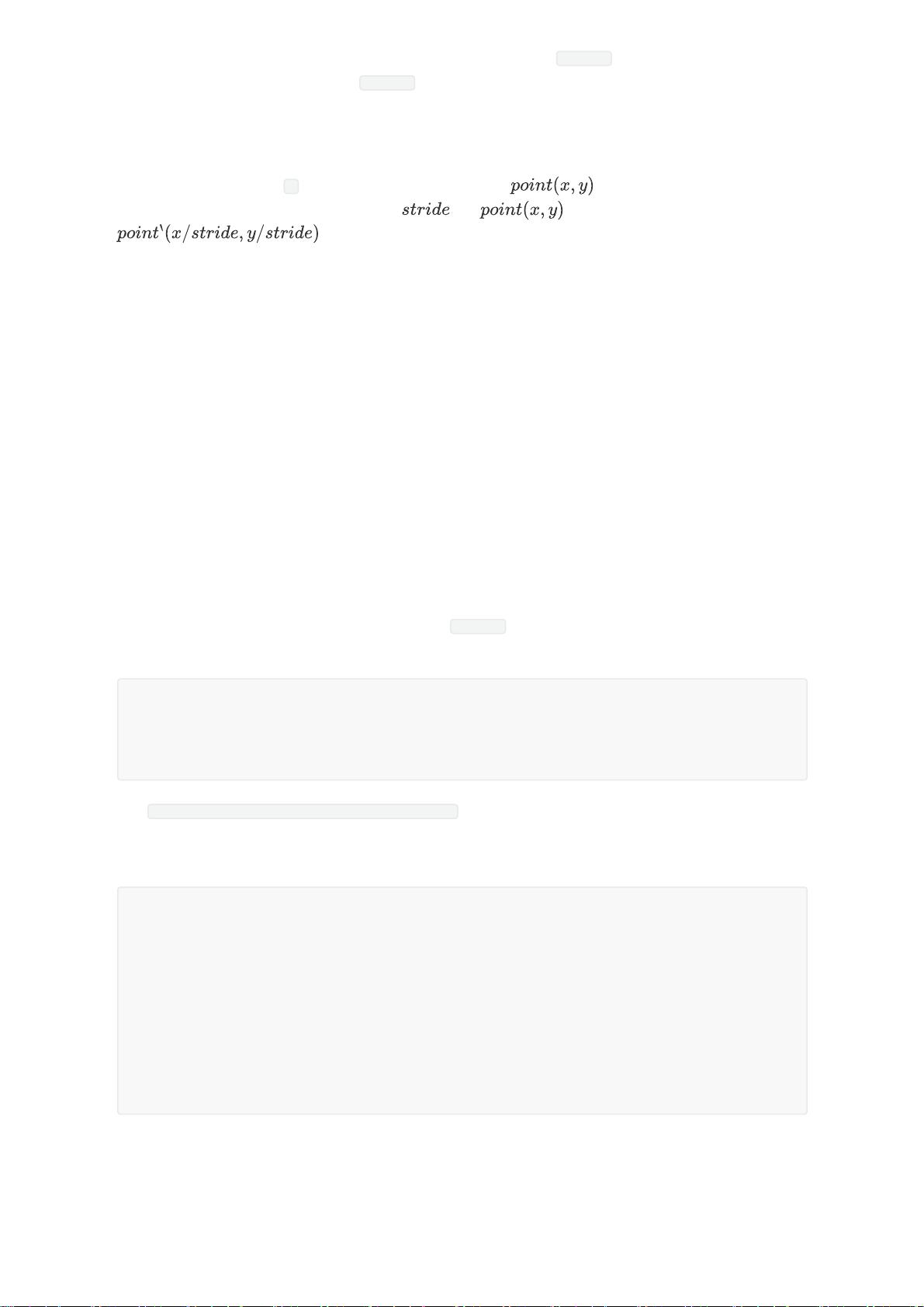
单通道单步长卷积运算分析
单通道多步长卷积运算分析
多通道卷积运算分析
减少循环中计算量的优化分析
传入参数合法性检查
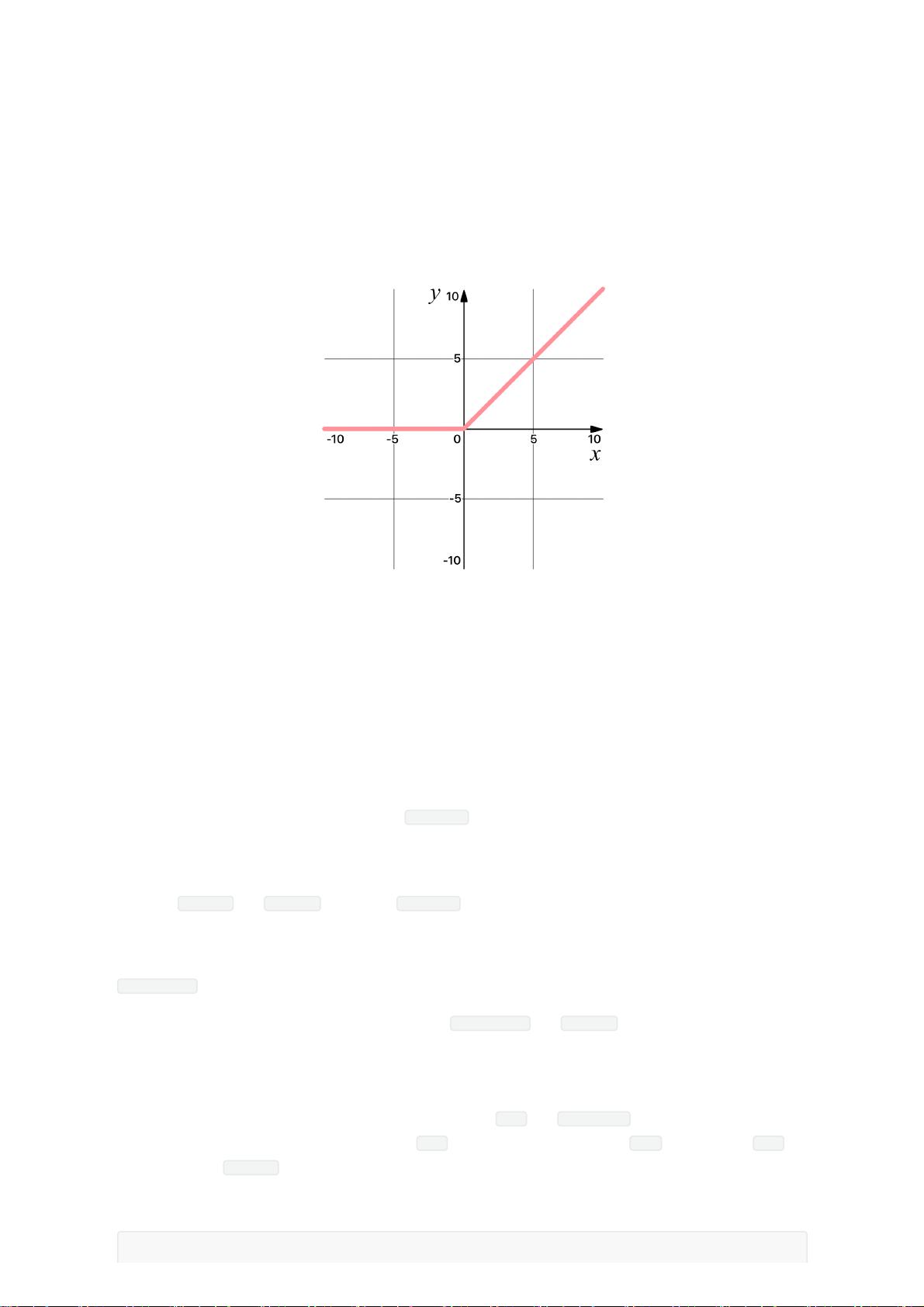
Relu 激活函数分析与实现
池化分析与实现
全连接分析与实现
Softmax 函数分析与实现
CNN层级结构实现
计时的方式分析
比较时间差距使用的方法
矩阵乘法卷积优化
CNN程序通用性与鲁棒性分析
通用性
鲁棒性
CMakeLists.txt 的编写以及分析
Part2 - Code
图片的读取与转换
卷积层次运算与计时
朴素卷积实现
矩阵乘法优化卷积层实现
Relu激活函数
池化函数实现
全连接层实现
Softmax 归一化实现
Matrix.hpp 中对于矩阵乘法的优化实现
Part3 - Result and Verification
在循环内部调用获取像素方法以及将矩阵数组开放程度提高效率的对比与分析
将矩阵类成员的类型从 int 更改为 size_t 的对比分析
使用OpenBLAS对矩阵运算进行加速的效率对比与分析
使用并行计算(openmp)对加速卷积运算的对比与分析


剩余34页未读,继续阅读













评论0