
斗地主 RL 模型
任务介绍
斗地主是一种扑克游戏。游戏最少由 3 个玩家进行,用一副 54 张牌(连鬼牌),其中一
方为地主,其余两家为另一方,双方对战,先出完牌的一方获胜。
潜在问题与解决思路
潜在问题
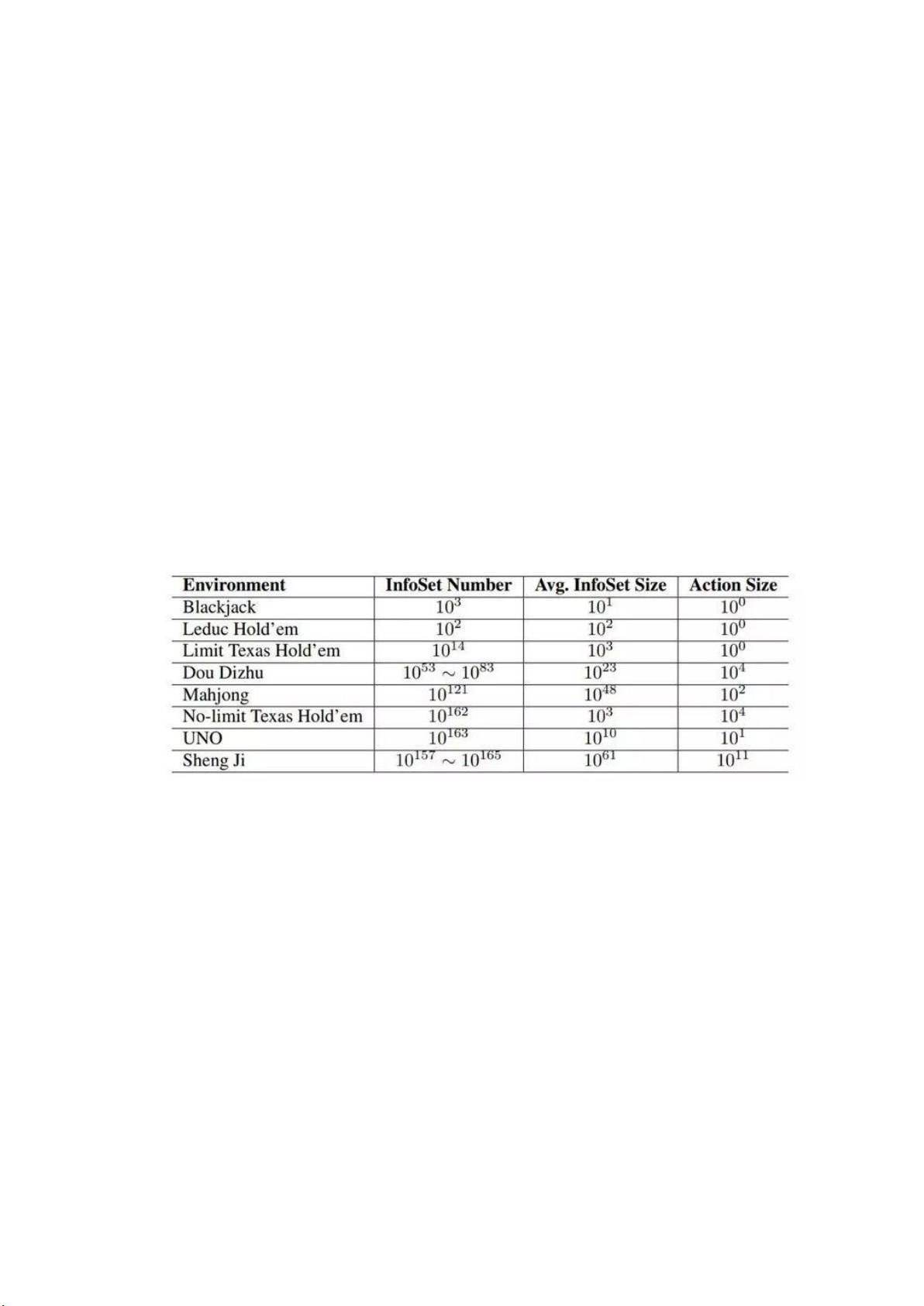
1.行动空间庞大,举个例子飞机带几个单张,有超多种可能。需要进行动作空间的搜索和
简化、采样。
表 1:RLCard 中牌类复杂度估计
2.动作的价值估计。首先,在不同对局、不同时段中,同样的牌组(合理的牌组合,如单
张、对子、三带一等)表现的信息是不同的。其次,每一次行动并不只是比较可选动作集
而已,还要考虑每次出牌后的牌组集合价值,与对家的关系、与队友的关系(农民)等整
体状态、策略。
3.不完全信息博弈。手上的牌有时非常好,但是不可见的是,已被对手完全的克制,实际
上这一局完全没有胜利的希望,这样模型学习起来往往是无益的。
4.不同阶段不同身份,存在不同的分析决策方式。我的牌很好,但是叫地主?也许会破坏
牌!牌很差,但是差几张就会顺?搏一搏,也许胜率更高!地主独自战斗,农民之间又讲
究协作。
5.人格揣测。根据每一位选手的出牌规律、习惯,猜测 ta 手上的余牌—>虚张声势?or 确
有其事?or 声东击西...从对家的出牌中学习知识,也要结合自身的牌,理性思考。
6.试验环境与数据。不同的玩家思维/策略不同,模型的分析能力未必适用。
剩余8页未读,继续阅读

生活教会我们
- 粉丝: 33
- 资源: 315












评论0