用于可穿戴设备上资源受限推理的深度学习层的稀疏化和分离1
需积分: 0 101 浏览量
2022-08-04
15:20:26
上传
评论
收藏 4.35MB PDF 举报


Sparsification and Separation of Deep Learning Layers
for Constrained Resource Inference on Wearables
Sourav Bhattacharya
§
and Nicholas D. Lane
§,†
§
Nokia Bell Labs,
†
University College London
ABSTRACT
Deep learning has revolutionized the way sensor data are
analyzed and interpreted. The accuracy gains these ap-
proaches o↵er make them attractive for the next genera-
tion of mobile, wearable and embedded sensory applica-
tions. However, state-of-the-art deep learning algorithms
typically require a significant amount of device and pro-
cessor resources, even just for the inference stages that are
used to discriminate high-level classes from low-level data.
The limited availability of memory, computation, and en-
ergy on mobile and embedded platforms thus pose a signif-
icant challenge to the adoption of these powerful learning
techniques. In this paper, we propose SparseSep, a new ap-
proach that leverages the sparsification of fully connected
layers and separation of convolutional kernels to reduce the
resource requirements of popular deep learning algorithms.
As a result, SparseSep allows large-scale DNNs and CNNs to
run efficiently on mobile and embedded hardware with only
minimal impact on inference accuracy. We experiment using
SparseSep across a variety of common processors such as the
Qualcomm Snapdragon 400, ARM Cortex M0 and M3, and
Nvidia Tegra K1, and show that it allows inference for vari-
ous deep models to execute more efficiently; for example, on
average requiring 11.3 times less memory and running 13.3
times faster on these representative platforms.
CCS Concepts
•Computing methodologies ! Machine learning; Neu-
ral networks; •Computer systems organization !
Embedded software;
Keywords
Wearable computing; deep learning; sparse coding; weight
factorization
1. INTRODUCTION
Recognizing co ntextual signals and the everyday activity
of users from raw sensor data is a core enabler for mobile
and wearable applications. By monitoring user actions (via
sp eech, ambient audio, motion) and context using a variety
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full cita-
tion on the first page. Copyrights for components of this work owned by others than
ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or re-
publish, to post on servers or to redistribute to lists, requires prior specific permission
and/or a fee. Request permissions from permissions@acm.org.
SenSys ’16, November 14-16, 2016, Stanford, CA, USA
c
2016 ACM. ISBN 978-1-4503-4263-6/16/11. . . $15.00
DOI: http://dx.doi.org/10.1145/2994551.2994564
of sensing modalities, mobile developers are able to provide
b oth enhanced, and brand new, application features. While
sensor-related applications and systems are still maturing,
and are highly diverse, a notable characteristic is their re-
liance on making a wide-variety of sensor inferences.
Accurately extracting context and activity information from
noisy mobile sensor data remains an unsolved problem. Be-
cause the real world is highly complex, unpredictable and
constantly changing, it often causes confusion to the ma-
chine learning and signal processing algorithms used by mo-
bile devices. One of the most promising directions today
in overcoming such challenges is deep learning [1, 2]. De-
velopments in this particular field of machine learning have
caused the approaches and algorithms used in even mature
sensing tasks to be completely changed (e.g., speech [3] and
face [4] recognition). The study of deep learning usage for
mobile applications is in its early stages (e.g., [5, 6, 7, 8]),
but with promising initial results.
While deep learning o↵ers important benefits to robust mod-
eling, its integration into mobiles and wearables is compli-
cated by the sizable system resource requirements these algo-
rithms introduce. Barriers exist in the form of memory, com-
putation and energy; these collectively prevent most deep
mo dels from executing directly on mobile hardware. Conse-
quently, existing examples of deep learning for smartphones
(e.g., speech recognition) remain largely cloud-assisted. A
number of negative side-e↵ects of this: first, inference ex-
ecution becomes coupled to fluctuating and unpredictable
network quality (e.g., latency, throughput); but more im-
p ortantly it exposes users to privacy dangers [9] as sensitive
data (e.g., audio) is processed o↵-device by a third party.
Allowing broader device-centric deep learning classification
and prediction will need the development of brand-new tech-
niques for optimized resource sensitive execution. Up to this
p oint, the machine learning community has made excellent
progress in training-time optimizations and is only now be-
ginning to consider how these ideas transfer to inference-
time. Currently, most knowledge of deep learning algo-
rithm behavior on constrained devices is largely limited to
one-o↵ task-specific experiences (e.g. , [10, 11]). These sys-
tems are limited however is providing examples and evidence
that local execution is feasible, although they do provide
some insights for ways forward. What is required however
is a deeper study of these issues with an aim towards the
development of techniques like o↵-line model optimization
and runtime execution environments to match the resources
(e.g., memory, computation and energy) present on edge de-
vices like wearables and mobile phones.
In this work, we make an significant progress into the de-
velopment of such algorithms and software by developing
a sparse coding- and convolution kernel separation-based
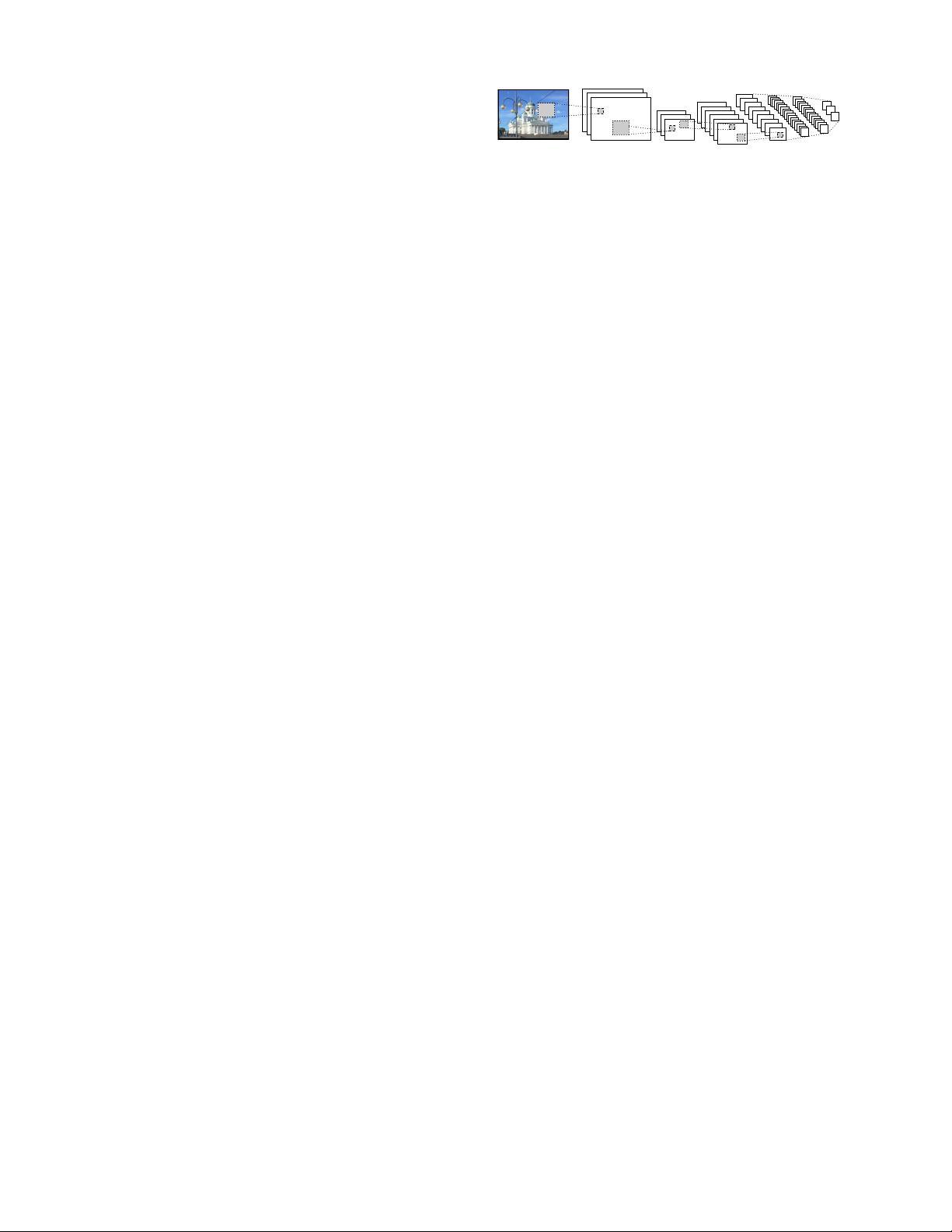

剩余13页未读,继续阅读

马李灵珊
- 粉丝: 34
- 资源: 297












评论0