深度学习算法神经网络架构_受限玻尔兹曼机_编程项目案例解析实例详解课程教程.pdf
版权申诉
16 浏览量
2023-04-10
21:49:30
上传
评论
收藏 2.64MB PDF 举报


受限玻尔兹曼机
在本章中,我们将讨论受限玻尔兹曼机网络,这种网络采用能量函数进行定义,对比
散度算法(CD-K)进行训练,广泛应用于深度学习的特征工程中。而且受限玻尔兹曼机还
可以通过堆叠形成深度信念网络,这种网络是深度学习算法兴起的起点,具有广泛的应用
价值,历史意义也非常大。
在本章中,我们会先介绍受限玻尔兹曼机的数学原理,然后会以 Theano 框架为基础,
实现一个简单的受限玻尔兹曼机,并将其用于图像特征获取工作,使我们对受限玻尔兹曼
机有一个感性认识。
10.1 受限玻尔兹曼机原理
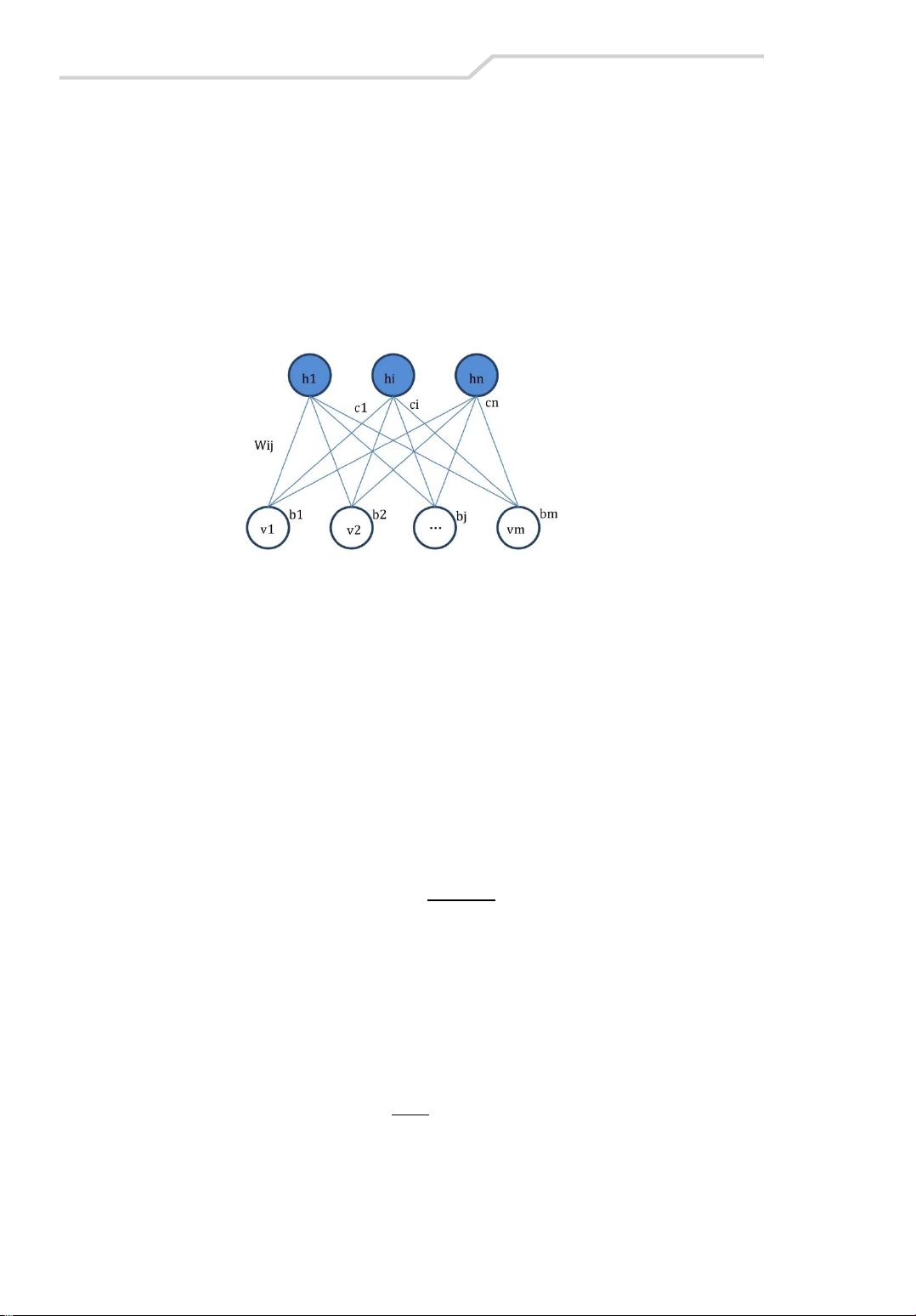
10.1.1 网络架构
我们目前讨论的神经网络,虽然学习算法不同,但架构基本还是相同的,都是分层网
络,即神经元按层进行组织,层内神经元无连接,层间神经元有连接。在本章中,将讨论
一种非常不同的神经网络,这种神经网络由没有层次关系的神经元全连接网络进化而来。
这种网络起源于 Holpfield 网络,我们可以给它定义一个能量函数,神经网络的学习任
务就是使能量函数达到最小值。这种网络典型的应用是担货郞问题,即有 N 个地点,每个
地点间都有道路相通,担货郞必须把货物送到每个地点。通过 Holpfield 网络,可以有效地
找到最佳路径。但是即使是二值(神经元只能处在 0 或 1 状态),全连接网络也有 2
N
个状态,
要从这些状态中找到能量函数的最小值,难度相当大。
与此同时,根植于统计力学模型的玻尔兹曼机也开始流行起来。在这种网络中,神经



剩余36页未读,继续阅读
资源评论


好知识传播者
- 粉丝: 498
- 资源: 4204

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 学生成绩管理系统-C++版本
- 吉林大学离散数学2笔记.pdf
- 通道处理过程的模拟通常涉及对通道处理机制的理解与实现.txt
- Flume进阶-自定义拦截器jar包
- Dubins曲线算法讲解和在运动规划中的使用.pdf
- 上市公司-股票性质数据-工具变量(民企、国企、央企)2003-2022年.dta
- 上市公司-股票性质数据-工具变量(民企、国企、央企)2003-2022年.xlsx
- Reeds+Shepp曲线算法讲解和实现.pdf
- 毕业设计基于SpringBoot+MyBatisPlus+MySQL+Vue的外卖配送信息系统源代码+数据库
- 词向量(Word Embeddings)是自然语言处理(NLP)领域的一种重要技术.txt
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


