机器学习-分类算法1

需积分: 0 64 浏览量
更新于2022-08-03
1
收藏 2.22MB PDF 举报
【机器学习-分类算法1】
分类算法是机器学习领域中的一种重要技术,它主要用于将数据集中的观测值分配到预定义的类别中。本篇主要介绍几种常见的分类算法及其特点。
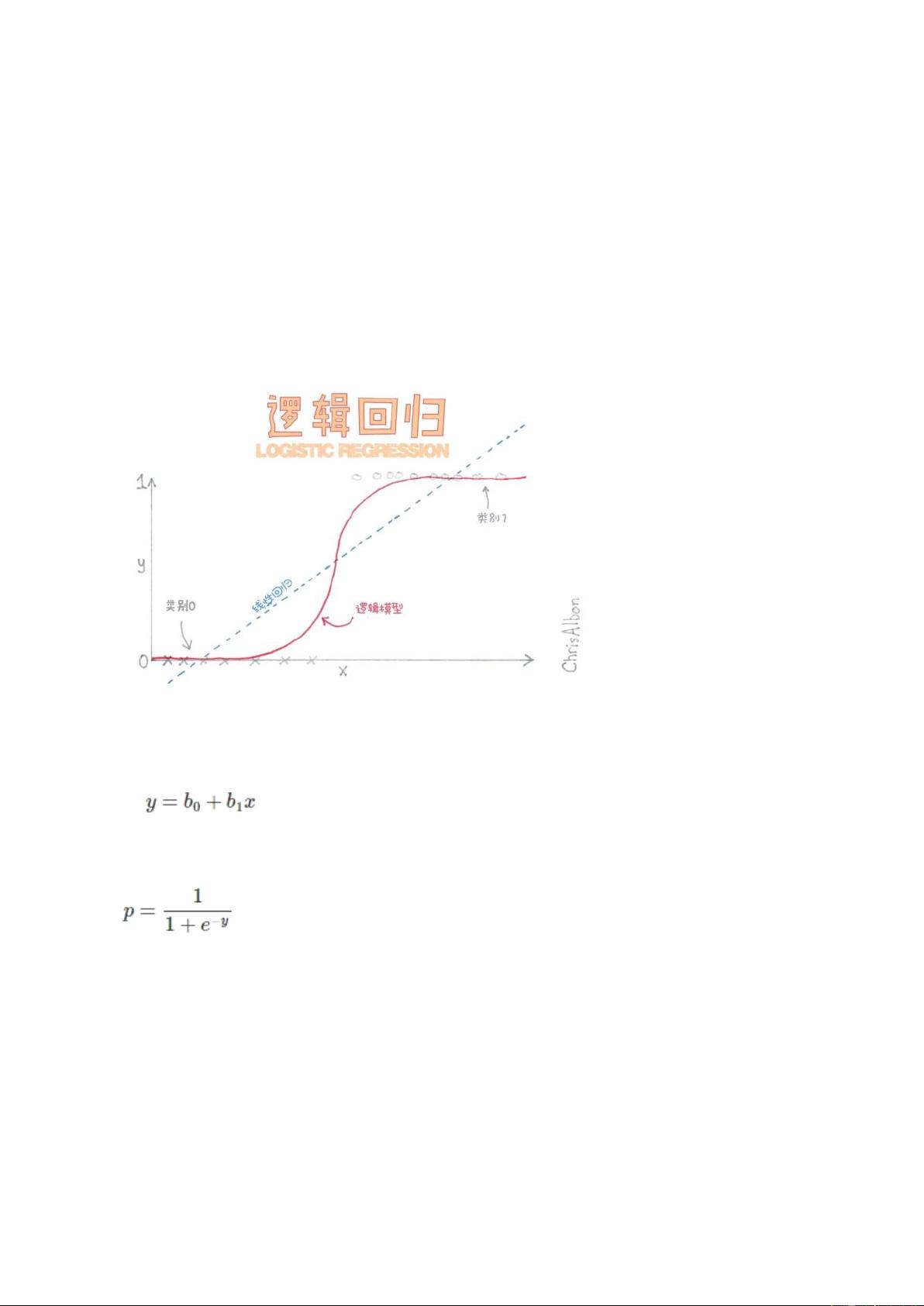
1. **逻辑回归(LR)**
- LR是一种广义线性模型,常用于估计事件发生的概率。它与多元线性回归类似,但处理的是分类问题。在LR中,通过应用逻辑函数(sigmoid函数)将线性组合转换为0到1之间的概率值,从而进行二分类。LR对数据中的小噪声具有较好的鲁棒性,并且可以处理多重共线性问题,通过正则化来避免过拟合。然而,LR对非线性特征的处理需要进行特征转换,且在高维特征空间中性能可能下降。
2. **K-最近邻(KNN)**
- KNN是一种基于实例的学习方法,它根据最近邻的类别来预测新样本的类别。KNN是非参数的,属于懒惰学习类别,不需要构建模型,而是等到预测时才进行计算。KNN在处理小输入变量数量时表现良好,特别适合类域交叉或重叠的情况。但是,KNN的缺点在于计算量大,需要预先确定K值,且对样本容量较小的类别易产生误分,输出的可解释性相对较弱。
3. **支持向量机(SVM)**
- SVM是一种基于结构风险最小化的分类模型,通过构造最大间隔超平面来划分类别。SVM通过找到最优超平面最大化类别间的间隔,使得类别边界尽可能远离数据点,从而达到良好的泛化能力。SVM尤其适合于高维空间的小样本数据集,但在大数据集上可能计算复杂度较高。
4. **朴素贝叶斯分类(NBC)**
- NBC基于贝叶斯定理,假设特征之间相互独立,简化了计算。尽管这种假设在实际问题中可能过于简化,但在许多情况下仍然表现出色,特别是在文本分类等任务中。
5. **决策树(DT)**
- 决策树包括ID3、C4.5、C5.0和CART等不同版本,它们通过创建一棵树形结构来表示数据的决策规则。决策树易于理解和解释,但可能会过拟合,可通过剪枝或正则化来控制。
6. **集成方法**
- 集成方法如随机森林(RF)和梯度增强决策树(GBDT)通过组合多个弱分类器形成强分类器。随机森林通过随机选取特征和子样本生成多个决策树,而GBDT则是连续迭代地添加弱分类器,每个新分类器专注于前一轮分类错误的样本。
7. **评估指标**
- 对分类器性能的评估通常涉及混淆矩阵、接收者操作曲线(ROC)和曲线下面积(AUC)。混淆矩阵提供了真阳性、真阴性、假阳性、假阴性的计数,而ROC和AUC可以帮助理解模型在不同阈值下的性能。
以上就是对几种常见分类算法的简要介绍。在实际应用中,选择合适的算法需要考虑数据的特性、问题的复杂性以及计算资源的限制。通常,可以通过交叉验证和调参来优化模型性能。

参考:
《数据挖掘算法——常用分类算法总结》
https://blog.csdn.net/songguangfan/article/details/92581643
《一文读懂机器学习分类算法(附图文详解)》
https://zhuanlan.zhihu.com/p/82114104
常用的分类算法包括:
LR(Logistic Regress,逻辑回归)
•
KNN(K-Nearest Neighbor,K 最近邻近)
•
SVM(Support Vector Machine,支持向量机)
•
NBC(Naive Bayesian Classifier,朴素贝叶斯分类)
•
决策树(Decision Tree)
https://www.cnblogs.com/molieren/articles/10664954.html
•
ID3(Iterative Dichotomiser 3 迭代二叉树3 代)决策树
C4.5 决策树
C5.0 决策树
CART 分类回归树 https://www.cnblogs.com/keye/p/10564914.html
https://www.cnblogs.com/keye/p/10601501.html
集成方法
随机森林(Random Forest)
https://blog.csdn.net/yangyin007/article/details/82385967
•
GBDT:gradient boosting decision tree 梯度增强决策树
https://www.cnblogs.com/bnuvincent/p/9693190.html
•
ANN(Artificial Neural Network,人工神经网络)
•
分类器性能评价
混淆矩阵
•
接受者操作曲线(ROC)和曲线下的面积(AUC)
•
LR
1.
机器学习-分类算法
2021年4月5日
21:11
分区 计算机专业课 的第 1 页


剩余25页未读,继续阅读
180 浏览量
2018-06-20 上传
117 浏览量
2024-05-12 上传
109 浏览量
131 浏览量
107 浏览量
2024-04-08 上传
181 浏览量
118 浏览量
2021-09-24 上传
2014-03-01 上传
201 浏览量
2024-10-17 上传
127 浏览量
104 浏览量
138 浏览量
2021-02-25 上传
2019-03-29 上传
170 浏览量
145 浏览量
140 浏览量
190 浏览量
资源评论


袁大岛
- 粉丝: 40
- 资源: 305









最新资源
- 基于SpringBoot+vue的社区医院管理系统.zip
- 锂电池SOC估计基于二阶RC模型的扩展卡尔曼滤波估算SOC 验证工况:HPPC 和 1C放电
- c#轻量级高并发物联网服务器接收程序源码(仅仅是接收硬件数据程序,没有web端,不是java,协议自己写,如果问及这些问题统统不回复 ),对接几万个设备没问题,数据库采用ef6+sqlite,可改e
- CityGPT: Empowering Urban Spatial Cognition of Large Language Models
- 平安夜祝福代码html 代码实现示例.docx
- java(二叉树的基本操作和部分二叉树相关的题)
- Spring Boot 整合 RabbitMQ(在Spring项目中使用RabbitMQ)
- 三菱Fx3U三轴定位控制程序,其中两轴为脉冲输出同步运行360度转盘,3轴为工作台丝杆 1.本程序结构清晰,有公共程序,原点回归,手动点动运行,手动微动运行 报警程序,参数初始化程序等 2.自动
- armv7l的树莓派可以用的onnxruntime版本
- 纸袋检测15-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- Yealink VC Desktop1.28.0.72, 免费,局域网,IP电话, SIP, VOIP, 视频通话,可与手机互通,手机上也安装 yealink
- 全自动棒料加工自动设备sw17全套技术开发资料100%好用.zip
- 用Jenkins 跑gitte仓库中的postman脚本 请求
- Instruction Pre-Training: Language Models are Supervised Multitask Learners
- 图片转PDF_QQ浏览器_20241226.pdf
- STM8驱动的MPU6050陀螺仪源程序
