05.EM算法1

需积分: 0 130 浏览量
更新于2022-08-03
收藏 1004KB PDF 举报
EM算法,全称为Expectation Maximization(期望最大化)算法,是一种在处理含有隐变量的数据集时,用于估计概率模型参数的迭代方法。该算法源于极大似然估计,但解决了最大似然估计在处理不完全数据时的困难。在EM算法中,数据被分为观测数据和隐藏数据两部分,通过E步骤(期望)和M步骤(最大化)交替进行,逐步逼近最优参数。
回顾极大似然估计的基本步骤:
1. 书写似然函数𝐿(𝜃) = 𝑃(𝑋|𝜃),其中𝜃是待估计的参数。
2. 将似然函数取对数,简化为 Hv(𝜃) = log𝐿(𝜃) = log(𝑃(𝑋; 𝜃))。
3. 对对数似然函数求导,并令其等于0,得到似然方程。
4. 解这个方程,获得参数估计。
在EM算法中,由于存在隐变量𝑍,我们无法直接写出似然函数𝐿(𝜃)。因此,我们需引入隐变量条件下的似然函数𝑃(𝑍|𝑋, 𝜃)和联合分布𝑃(𝑋, 𝑍|𝜃)。目标是最大化对所有可能的隐变量状态求和后的似然函数,即希尔伯特函数𝐻(𝜃) = ln𝑃(𝑋|𝜃)。
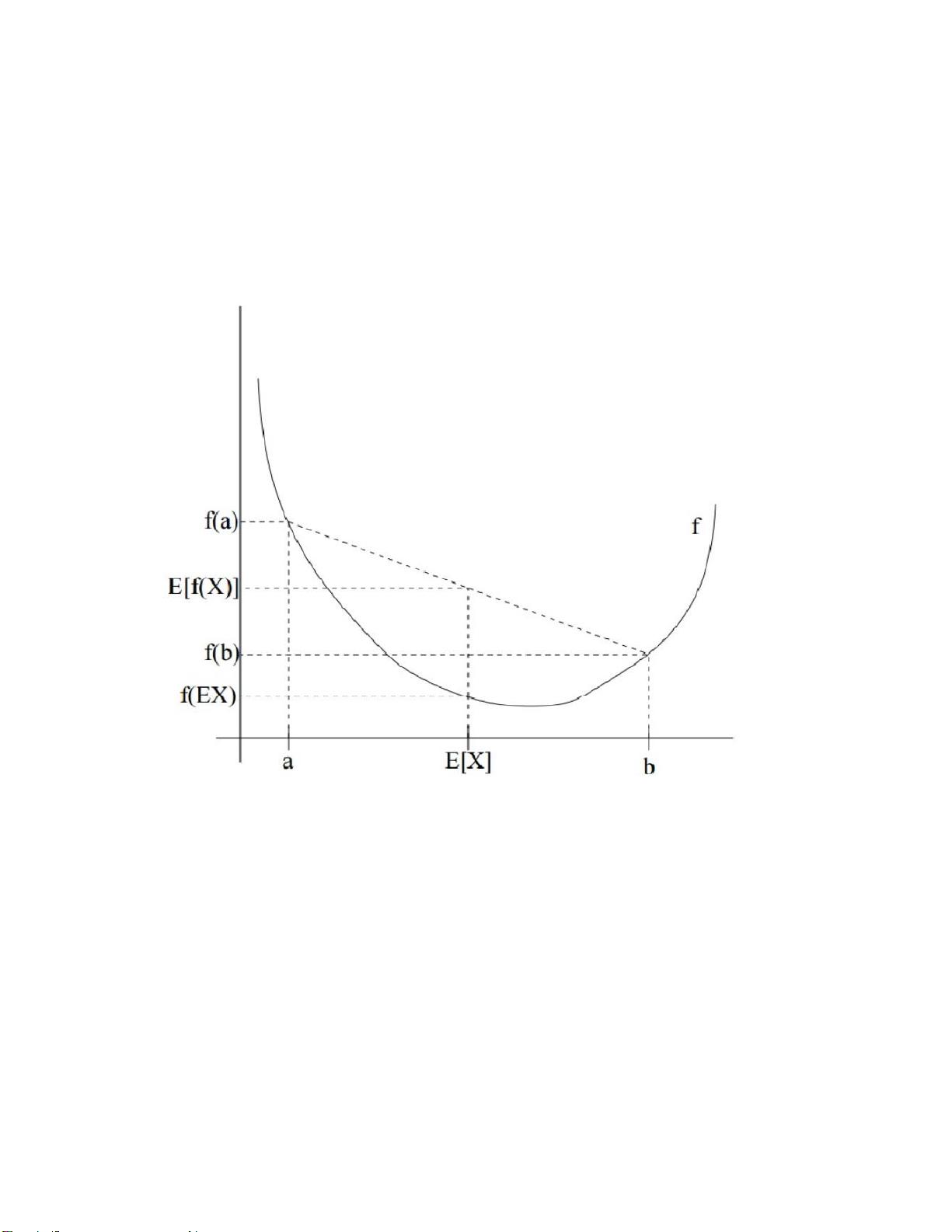
Jensen不等式在此处起关键作用。对于一个凸函数𝑓(𝑥),期望Ef[𝑓(𝑥)]总是大于等于f[E[𝑥]]。这为EM算法的推导提供了理论基础。
EM算法的具体步骤如下:
1. E步骤(期望):给定当前参数估计𝜃',计算每个观测数据点对隐变量状态的后验概率𝑞(𝑍|𝑋, 𝜃') = 𝑝(𝑍|𝑋, 𝜃')。这一步相当于估计隐变量的期望值。
2. M步骤(最大化):保持E步骤得到的分布不变,最大化Q函数𝑄(𝜃, 𝜃') = ∑𝑞(𝑍)ln 𝑝(𝑋, 𝑍|𝜃),更新参数𝜃为新的估计值,使Q函数达到最大。
这两个步骤交替进行,直到参数的改进趋近于零或者达到预设的迭代次数,从而完成参数估计。
在数学推导中,引入了Kullback-Leibler散度𝐾𝐿(𝑞||𝑝)来衡量分布𝑞(𝑍)和𝑝(𝑍|𝑋, 𝜃)的差异。当𝑞(𝑍) = 𝑝(𝑍|𝑋, 𝜃')时,KL散度最小,此时Q函数成为希尔伯特函数 Hv(𝜃) 的下界。
EM算法广泛应用于机器学习和统计建模中,例如混合高斯模型、隐马尔科夫模型等。它的优势在于能处理缺失数据和复杂的模型结构,通过迭代优化逐步逼近最优参数估计。然而,EM算法并不保证全局最优解,而是寻找局部最优,因此在实际应用中需要注意初始化和收敛条件的设置。

Expectation Maximization Algorithm
EM 算法是一种从不完全数据或者含有隐含变量(hidden variable)的数据集中求
解概率模型参数的极大似然估计方法,采用迭代的方式,每次迭代分为两步:E 步:
求期望(expectation);M 步:求极大似然(maximization)。
1.从极大似然估计到 EM 算法
1.1 引出
在之前的学习过程中,我们知道在已知数据的分布而不知具体分布参数的时候,我
们会使用极大似然估计来估计出该分布的参数 ,具体过程为:
1 写出似然函数
2.对似然函数取对数,得到 log 形式
3.对对数似然函数求导,令其为 0,得到似然方程
4.求解似然方程,得到所求参数
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。假设
已知某个随机样本满足某种概率分布,但其中具体参数不清楚,参数估计就是通过
若干次试验,观察其结果,利用结果推出参数的估计值。最大似然估计是建立在这
样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择
其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
与最大似然估计不同的是,EM 所处理的是不完备的数据,其中含有隐含变量,也
就是说很难直接写出似然函数,我们需要通过隐含变量的介入,得到隐变量条件下
的似然函数,再进一步进行求解。
形式化描述:假设我们有一个观测样本集
(
)
,这些样本属于
不同的类别
,即模型中的隐变量数据,联合分布,条件
分布但任务是求模型的参数 ,此时因为隐变量的存在,使得观
测样本不是完全数据,最大似然很难直接用于求解,自然地想法是如果我们知道隐
变量,那么问题便会变得简单。此时问题变成
对于(1)式,即为似然函数,我们的目标是去最大化(1)式,所以我们根据联合
概率密度下求边缘概率密度的公式,于是我们得到了(2)式,显然去对一个和的
log 函数求导并不是一件容易的事情,于是我们引入隐含变量 Z 的分布,下面
我们会对其进行具体的分析和推导.
剩余9页未读,继续阅读
2022-08-03 上传
2022-08-04 上传
2024-07-18 上传
2010-06-24 上传
118 浏览量
157 浏览量
2022-03-11 上传
126 浏览量
2022-07-15 上传
155 浏览量
2012-06-01 上传
160 浏览量
2013-01-07 上传
174 浏览量
2012-02-12 上传
185 浏览量
157 浏览量
2009-10-26 上传
128 浏览量
127 浏览量
186 浏览量
2011-09-05 上传
资源评论


宝贝的麻麻
- 粉丝: 42
- 资源: 294









最新资源
- 仙岭小学结构建模revit
- 第6章习题参考答案.zip
- BeautifyAPP的产品设计(论文+源码)_kaic.zip
- 俄罗斯方块游戏系统的设计与实现(源码+论文)_kaic.zip
- 仓库管理系统的设计与实现(论文+源码)_kaic.zip
- 基于BC模式的电商平台的设计与实现(论文+源码)_kaic.zip
- 基于C#的超市收银管理系统设计与实现(论文+源码)_kaic.zip
- 妇幼保健信息管理系统设计(论文+源码)_kaic.zip
- 基于Java技术的养生知识管理系统设计与实现(论文+源码)_kaic.zip
- 基于springboot框架的高校就业管理系统设计与实现(论文+源码)_kaic.zip
- 基于web的电影购票管理系统的设计与实现(论文+源码)_kaic.zip
- ssm149学生成绩管理系统+vue.rar
- 深度报告:CPU研究框架.pdf
- Freertos-freertos
- BootstrapAdmin-c#
- XTools-idea
