
1. 如何确定两个 story 的 topic 是否相同?
分别建立与原模型,计算
𝑃
𝑆
𝑖
│
𝑀
𝑇
𝑗
,选取一个阈值,超过这个阈值则认为“相同”。
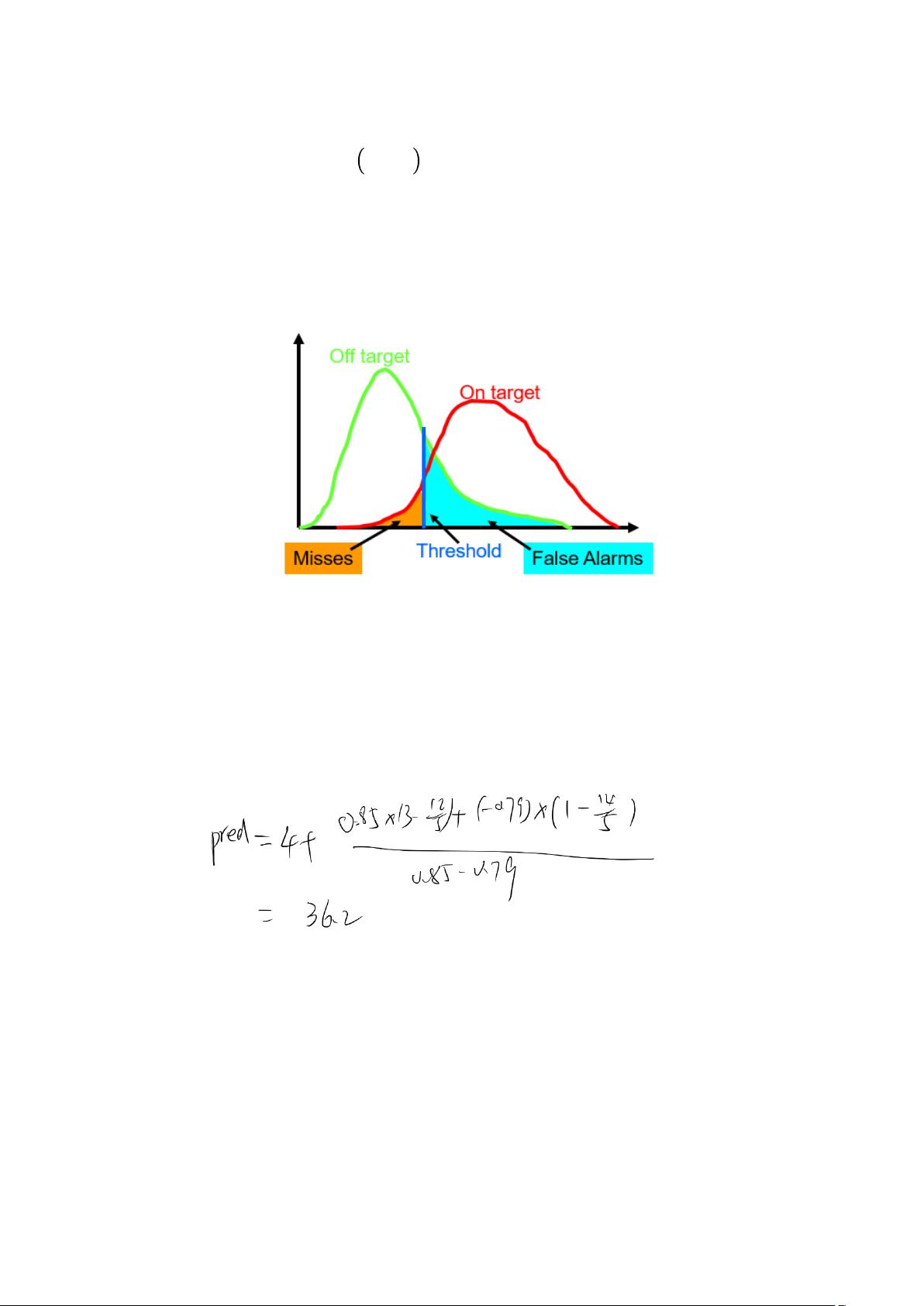
2. 设定一个相似度阈值,判定会有什么错误?
设定相似度阈值之后,on-topic 的 story 在比阈值低时会判为 off-story(False Alarm),
错误的概率是从 0 到阈值对 on-topic 曲线的积分;off-topic 的 story 比阈值高会被判为
on-story(MISS),错误的概率是从阈值到 1 对 off-topic 曲线的积分。总的误差是两个
错误之和。
3. 设计一个“打分函数”:
考察 Alice 的与某一用户的先验评分之间的“距离”的倒数(保证距离不为 0)作为权重,
对多个用户分别计算后,求取进行加权平均。
4. 计算分数:













评论0