因此接下来,我们来讨论的话题是:可以支持读写分离的场景下,有哪些解决过期读的方案,并
分析各个方案的优缺点。
Sleep Sleep 方案方案
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。
这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以有很大概率拿到最新的
数据。
这个方案给你的第一感觉,很可能是不靠谱儿,应该不会有人用吧?并且,你还可能会说,直接
在发起查询时先执行一条sleep语句,用户体验很不友好啊。
但,这个思路确实可以在一定程度上解决问题。为了看起来更靠谱儿,我们可以换一种方式。
以卖家发布商品为例,商品发布后,用Ajax(Asynchronous JavaScript + XML,异步JavaScript
和XML)直接把客户端输入的内容作为“新的商品”显示在页面上,而不是真正地去数据库做查
询。
这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商
品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题。
也就是说,这个sleep方案确实解决了类似场景下的过期读问题。但,从严格意义上来说,这个
方案存在的问题就是不精确。这个不精确包含了两层意思:
1. 如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒;
2. 如果延迟超过1秒,还是会出现过期读。
看到这里,你是不是有一种“你是不是在逗我”的感觉,这个改进方案虽然可以解决类似Ajax场景
下的过期读问题,但还是怎么看都不靠谱儿。别着急,接下来我就和你介绍一些更准确的方案。
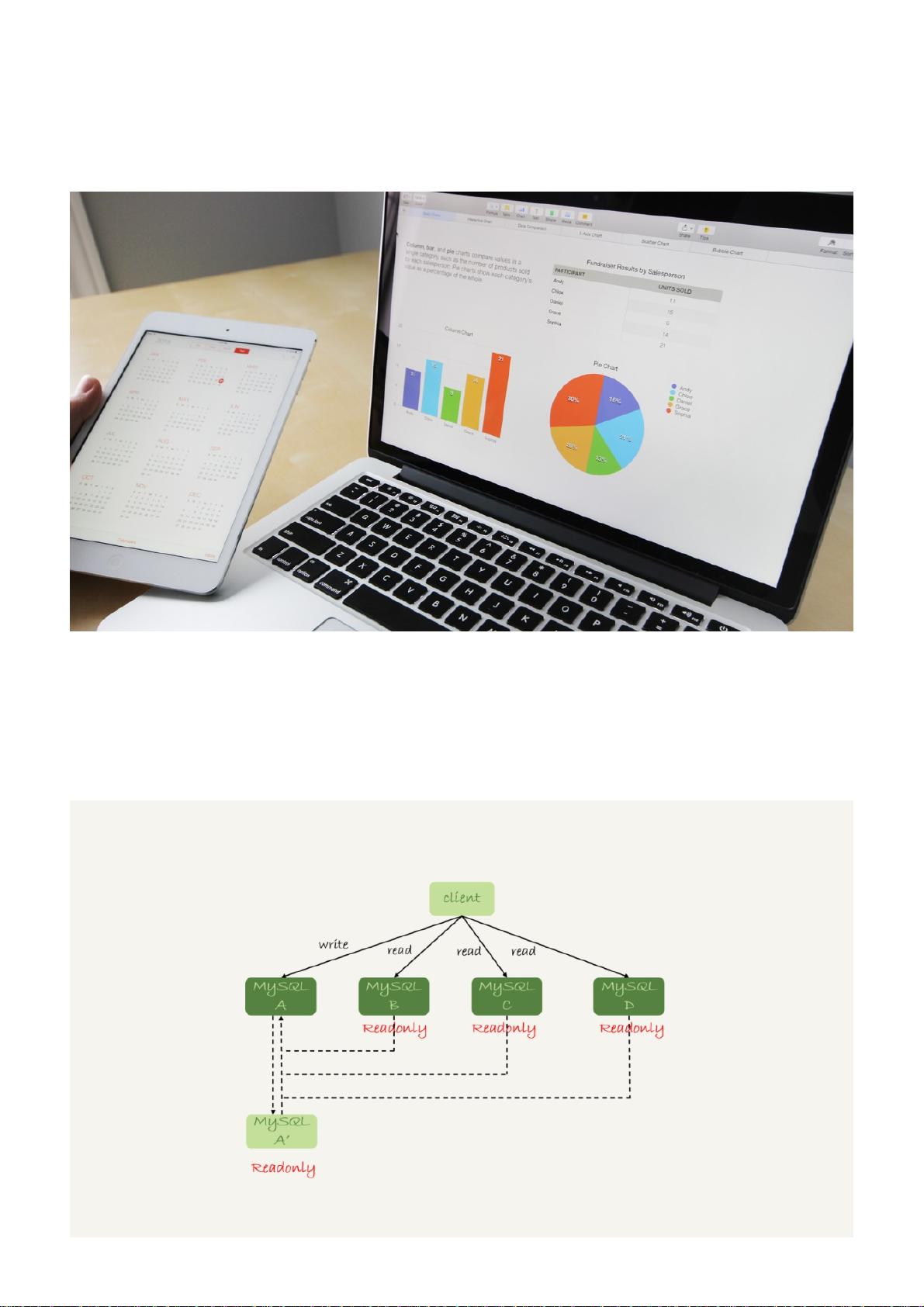
判断主备无延迟方案判断主备无延迟方案
要确保备库无延迟,通常有三种做法。
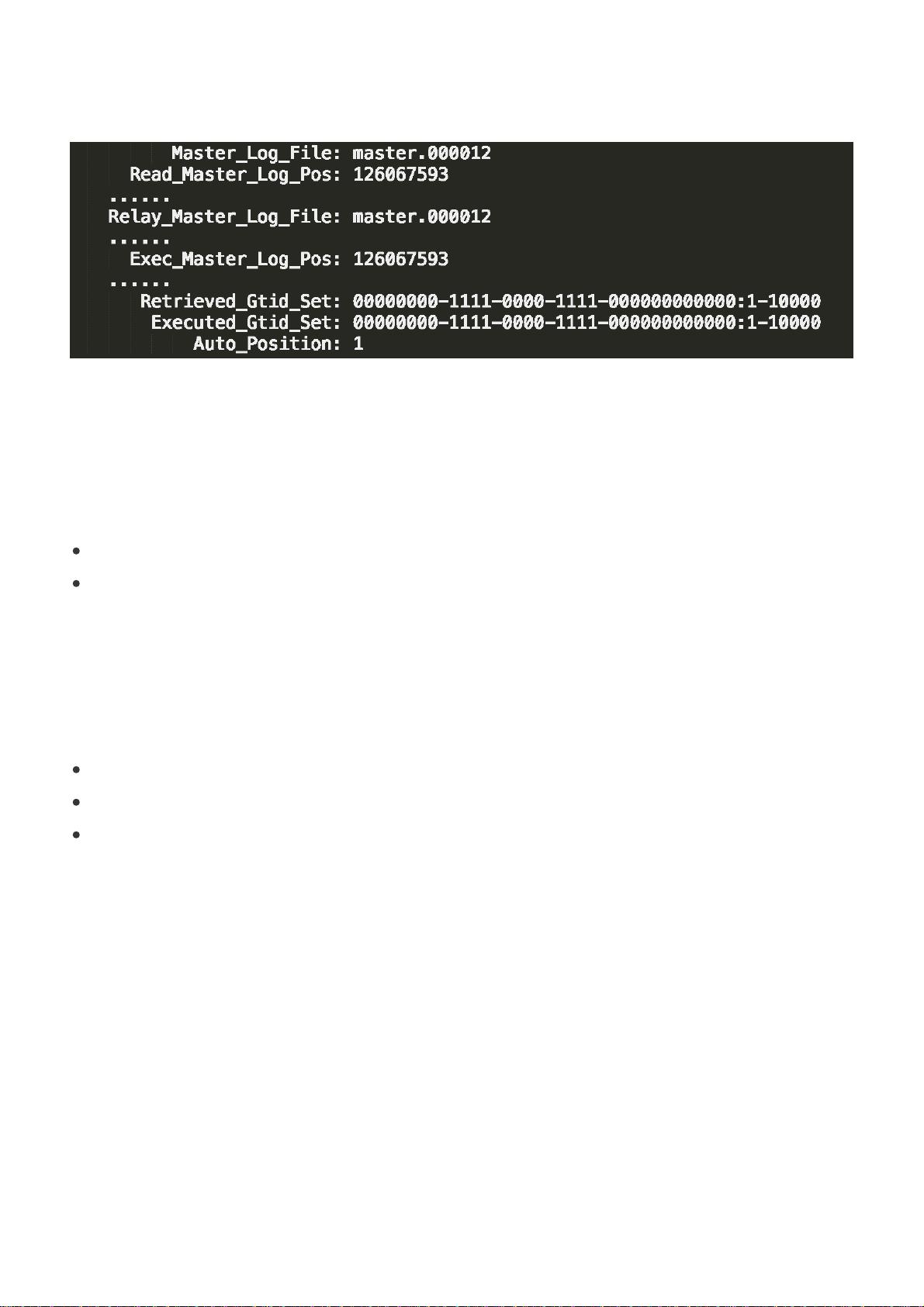
通过前面的第25篇文章,我们知道show slave status结果里的seconds_behind_master参数的
值,可以用来衡量主备延迟时间的长短。
所以第一种确保主备无延迟的方法是,第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断
seconds_behind_master是否已经等于0。如果还不等于0 ,那就必须等到这个参数变为0才能执
行查询请求。
seconds_behind_master的单位是秒,如果你觉得精度不够的话,还可以采用对比位点和GTID

















评论0