中文命名体识别2
需积分: 0 130 浏览量
2022-08-03
12:05:20
上传
评论
收藏 536KB PDF 举报


Chinese NER Using Lattice LSTM
Yue Zhang
∗
and Jie Yang
∗
Singapore University of Technology and Design
yue zhang@sutd.edu.sg
jie yang@mymail.sutd.edu.sg
Abstract
We investigate a lattice-structured LSTM
model for Chinese NER, which encodes
a sequence of input characters as well as
all potential words that match a lexicon.
Compared with character-based methods,
our model explicitly leverages word and
word sequence information. Compared
with word-based methods, lattice LSTM
does not suffer from segmentation errors.
Gated recurrent cells allow our model to
choose the most relevant characters and
words from a sentence for better NER re-
sults. Experiments on various datasets
show that lattice LSTM outperforms both
word-based and character-based LSTM
baselines, achieving the best results.
1 Introduction
As a fundamental task in information extraction,
named entity recognition (NER) has received con-
stant research attention over the recent years. The
task has traditionally been solved as a sequence
labeling problem, where entity boundary and cate-
gory labels are jointly predicted. The current state-
of-the-art for English NER has been achieved by
using LSTM-CRF models (Lample et al., 2016;
Ma and Hovy, 2016; Chiu and Nichols, 2016; Liu
et al., 2018) with character information being in-
tegrated into word representations.
Chinese NER is correlated with word segmen-
tation. In particular, named entity boundaries are
also word boundaries. One intuitive way of per-
forming Chinese NER is to perform word segmen-
tation first, before applying word sequence label-
ing. The segmentation → NER pipeline, how-
ever, can suffer the potential issue of error propa-
gation, since NEs are an important source of OOV
∗
Equal contribution.
南
South
京
Capital
市
City
长
Long
江
River
大
Big
桥
Bridge
长江
Yangtze River
市长
mayor
南京
Nanji ng
大桥
Bridge
长江大桥
Yangtze River Bridge
Person?
南京市
Nanjing City
Figure 1: Word character lattice.
in segmentation, and incorrectly segmented en-
tity boundaries lead to NER errors. This prob-
lem can be severe in the open domain since cross-
domain word segmentation remains an unsolved
problem (Liu and Zhang, 2012; Jiang et al., 2013;
Liu et al., 2014; Qiu and Zhang, 2015; Chen et al.,
2017; Huang et al., 2017). It has been shown that
character-based methods outperform word-based
methods for Chinese NER (He and Wang, 2008;
Liu et al., 2010; Li et al., 2014).
One drawback of character-based NER, how-
ever, is that explicit word and word sequence in-
formation is not fully exploited, which can be
potentially useful. To address this issue, we in-
tegrate latent word information into character-
based LSTM-CRF by representing lexicon words
from the sentence using a lattice structure LSTM.
As shown in Figure 1, we construct a word-
character lattice by matching a sentence with a
large automatically-obtained lexicon. As a re-
sult, word sequences such as “长江大桥 (Yangtze
River Bridge)”, “长江 (Yangtze River)” and “大
桥 (Bridge)” can be used to disambiguate poten-
tial relevant named entities in a context, such as
the person name “江大桥 (Daqiao Jiang)”.
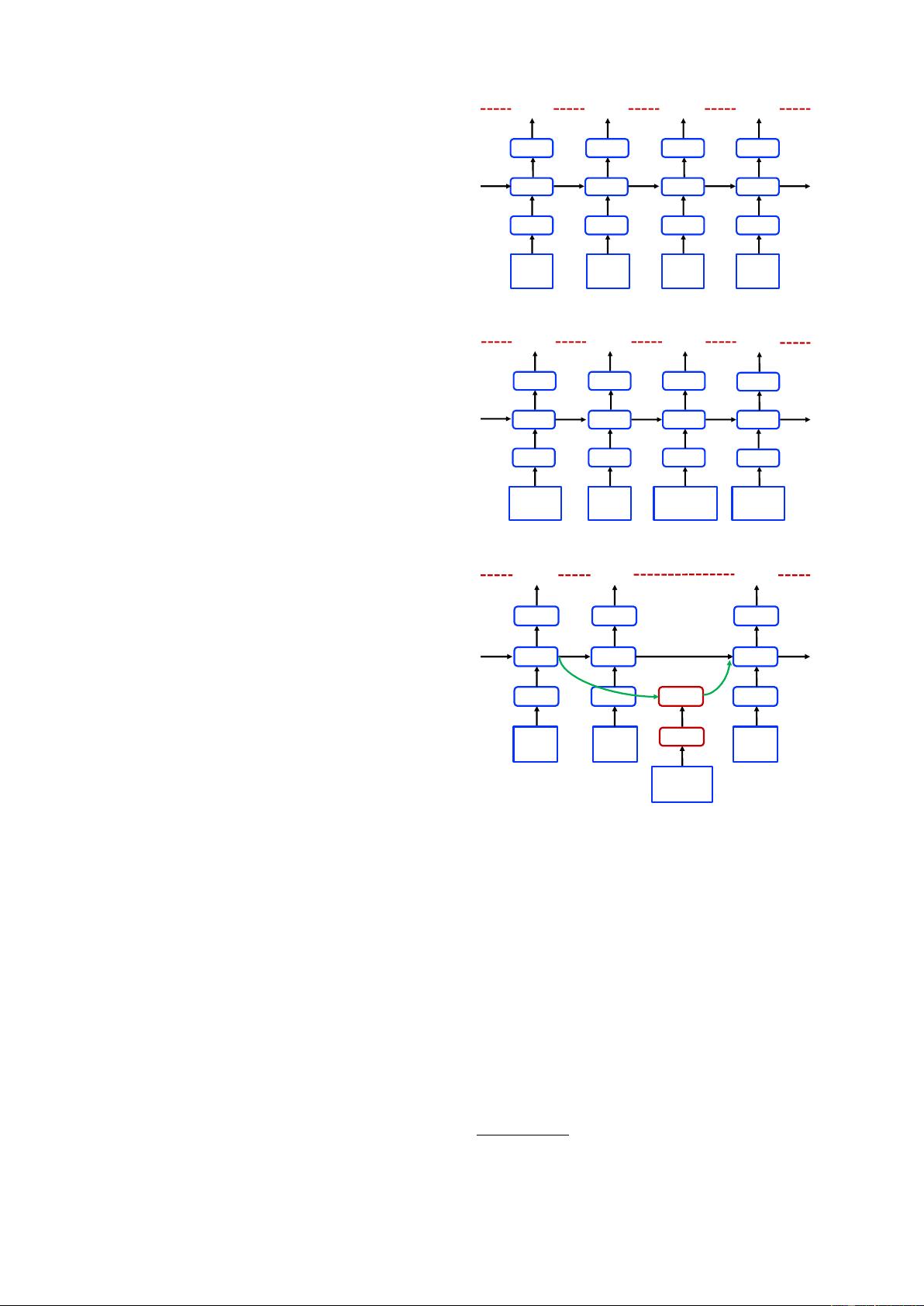
Since there are an exponential number of word-
character paths in a lattice, we leverage a lattice
LSTM structure for automatically controlling in-
formation flow from the beginning of the sentence
to the end. As shown in Figure 2, gated cells
are used to dynamically route information from
arXiv:1805.02023v4 [cs.CL] 5 Jul 2018

剩余10页未读,继续阅读

天使的梦魇
- 粉丝: 32
- 资源: 321









最新资源
- SM4-CFB代码实现及基本补位示例代码
- 基于asp的搜索引擎开发(源代码)
- Java课设相关材料.zip
- JSP搜索引擎的研究与实现(源代码)
- delphi 12 控件之delphipi.0.85.setup.exe
- 数据库管理工具:dbeaver-ce-23.0.2-amd64.deb
- 搜索链接淘特搜索引擎共享版-tot-search-engine
- 数据库管理工具:dbeaver-ce-24.0.3-macos-x86-64.dmg
- 数据库管理工具:dbeaver-ce-24.0.1-x86-64-setup.exe
- GoogleCloud2024年数据和AI趋势报告+生成式AI+数据治理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0