zookeeper第四节课 1

需积分: 0 124 浏览量
更新于2022-08-08
收藏 379KB DOCX 举报
Apache ZooKeeper 是一个分布式协调服务,它为分布式应用程序提供了一个高度可用、一致性的命名服务、配置管理、组服务和分布式锁等。在本节中,我们将深入探讨Zookeeper的源码原理,特别是服务端的QuorumPeerMain类,以及Zookeeper的选举机制。
**QuorumPeerMain类的启动流程**
Zookeeper服务的启动主要由`org.apache.zookeeper.server.quorum.QuorumPeerMain`类的`start`方法控制。这个方法分为单机模式和集群模式。在单机模式下,Zookeeper作为一个独立的服务运行;而在集群模式下,多个Zookeeper服务器相互协作,通过Quorum机制确保数据的一致性。
`QuorumPeerMain`启动时会创建一个`QuorumPeer`实例,该实例负责处理Zookeeper服务器的核心逻辑,包括处理网络请求、参与选举等。在`start`方法中,会创建一个线程并运行`run`方法,该方法包含了服务器的生命周期管理,如启动选举、监听网络连接等。
**线程与RunableZnode**
`run`方法内部,`QuorumPeer`会启动一系列线程来处理不同的任务。例如,`startLeaderElection`方法用于启动领导者的选举过程。在这个过程中,每个服务器都会发送自己的投票,包含MyID(服务器标识)和ZXID(事务ID),ZXID反映了服务器处理的最新事务。服务器会根据这些信息进行比较,选择ZXID最大的服务器作为领导者。
**ZAB协议与数据传输**
Zookeeper采用ZAB(Zookeeper Atomic Broadcast)协议来保证数据的一致性。ZAB协议的核心是原子广播,它确保每个服务器都收到并处理相同的事务。在数据传输中,`OutputArchive`和`InputArchive`是Jute库提供的序列化和反序列化工具,它们负责将Zookeeper的数据结构转换成字节流,以便在网络间传输。
**选举流程**
Zookeeper的选举分为五个步骤:
1. **初始化选举**:所有服务器开始投票,给自己投票,携带自己的MyID和ZXID。
2. **接受投票**:服务器接收其他服务器的投票,比较ZXID。
3. **处理投票**:服务器进行投票比较,确定当前的投票结果。
4. **统计投票**:计算得票数,超过半数的服务器才能成为领导者。
5. **状态变更**:当选为领导者后,服务器状态变更为LEADING,其他服务器变为FOLLOWING或OBSERVING。
**服务器状态**
Zookeeper服务器有四种状态:LOOKING(寻找领导者)、FOLLOWING(跟随者)、LEADING(领导者)和OBSERVING(观察者)。服务器根据其角色和集群状态自动切换这些状态。
**运维工具与四字命令**
Zookeeper提供了丰富的运维工具,通过四字命令可以获取和监控服务器的状态:
- `conf`:显示服务器配置详情。
- `cons`:列出所有客户端连接信息。
- `crst`:重置连接和会话统计。
- `dump`:仅在领导者节点上列出重要会话和临时节点。
- `envi`:打印服务器环境信息。
- `reqs`:列出未处理的请求。
- `ruok`:检查服务器是否正常,返回"imok"表示正常。
- `stat`:输出性能和客户端连接信息。
- `srst`:重置服务器统计。
- `srvr`:显示服务器连接详情。
- `wchs`、`wchc`、`wchp`:列出不同维度的watch详细信息。
- `mntr`:输出监控集群健康状态的变量。
**容灾与选举策略**
在选举过程中,Zookeeper遵循N/2+1的原则,即超过半数的服务器同意,才能确认一个新的领导者。这种策略确保了即使在集群部分节点故障的情况下,仍能正常选举出领导者,从而保证服务的高可用性。
总结来说,Zookeeper的源码原理涉及到服务器启动、选举机制、数据一致性协议以及运维工具等多个方面,理解这些知识点对于有效管理和优化Zookeeper集群至关重要。
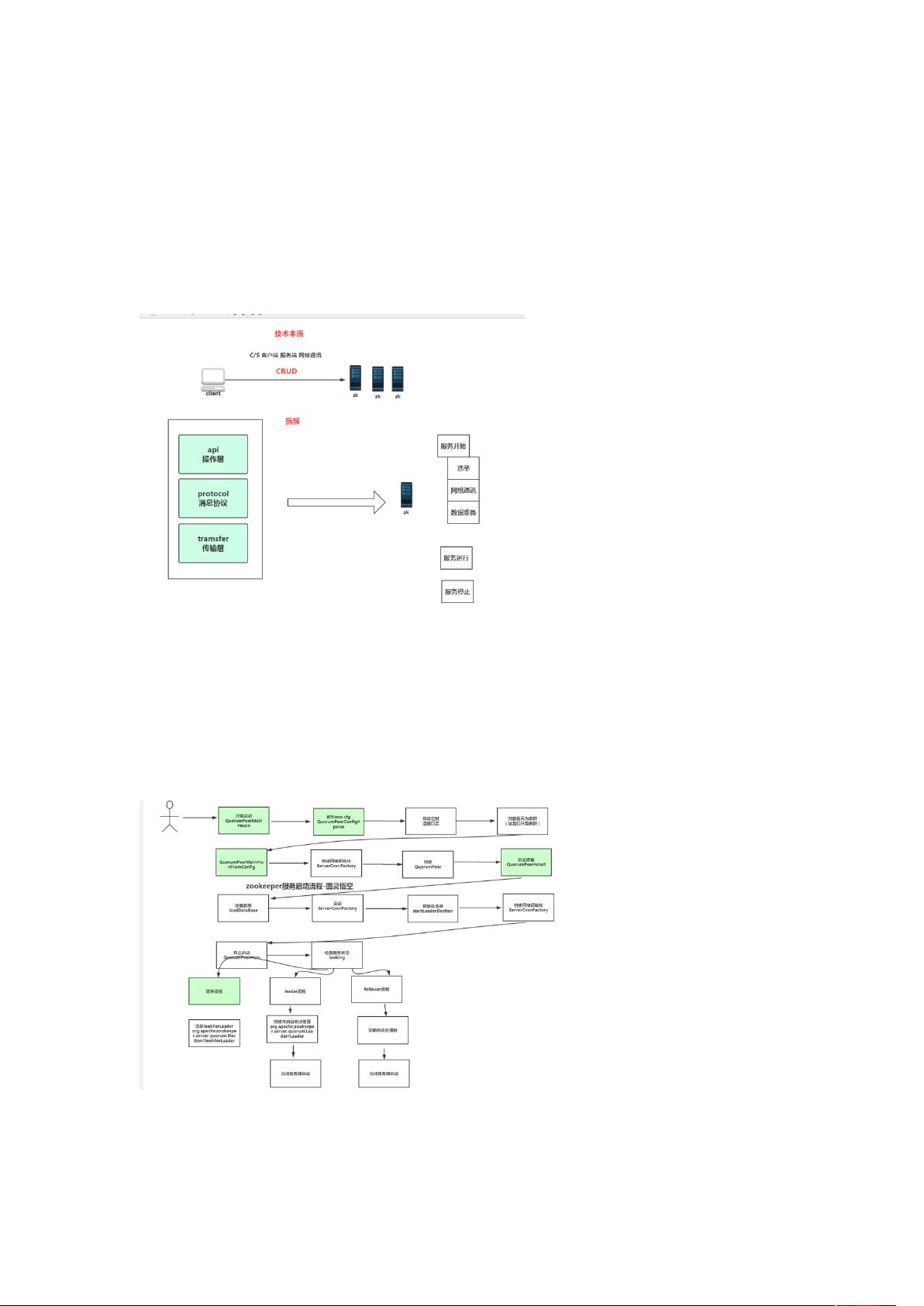
源码原理分析:
本质:
服务端:
org.apache.zookeeper.server.quorum.QuorumPeerMain
下载后可阅读完整内容,剩余5页未读,立即下载
2022-08-08 上传
184 浏览量
2023-11-15 上传
2022-08-08 上传
110 浏览量
2022-08-08 上传
2020-08-19 上传
149 浏览量
142 浏览量
2022-08-08 上传
157 浏览量
2021-07-13 上传
197 浏览量
2023-07-27 上传
154 浏览量
2022-08-04 上传
资源评论


王者丶君临天下
- 粉丝: 20
- 资源: 265









最新资源
- springboot279基于javaweb的影院订票系统的设计与实现.zip
- springboot279基于javaweb的影院订票系统的设计与实现_0303174040.zip
- springboot280基于WEB的旅游推荐系统设计与实现.zip
- springboot280基于WEB的旅游推荐系统设计与实现_0303174040.zip
- 基于C语言罗斯方块游戏实现示例与解析
- springboot281旅游网站.zip
- springboot281旅游网站_0303174040.zip
- springboot282基于web的机动车号牌管理系统_0303173844.zip
- springboot282基于web的机动车号牌管理系统.zip
- springboot282基于web的机动车号牌管理系统_0303174040.zip
- springboot059课程答疑系统.zip
- springboot283图书商城管理系统.zip
- springboot059课程答疑系统_0303152757.zip
- springboot256基于springboot+vue的游戏交易系统_0303174040.zip
- springboot256基于springboot+vue的游戏交易系统.zip
- springboot061基于B2B平台的医疗病历交互系统.zip
