Zookeeper 学习1

需积分: 0 23 浏览量
更新于2022-08-08
收藏 171KB DOCX 举报
【Zookeeper 学习1】
Zookeeper 是一个分布式协调服务,广泛应用于分布式系统中的命名服务、配置管理、集群管理等领域。它提供了高可用、高性能的数据一致性保障,是Apache Hadoop项目的一部分。
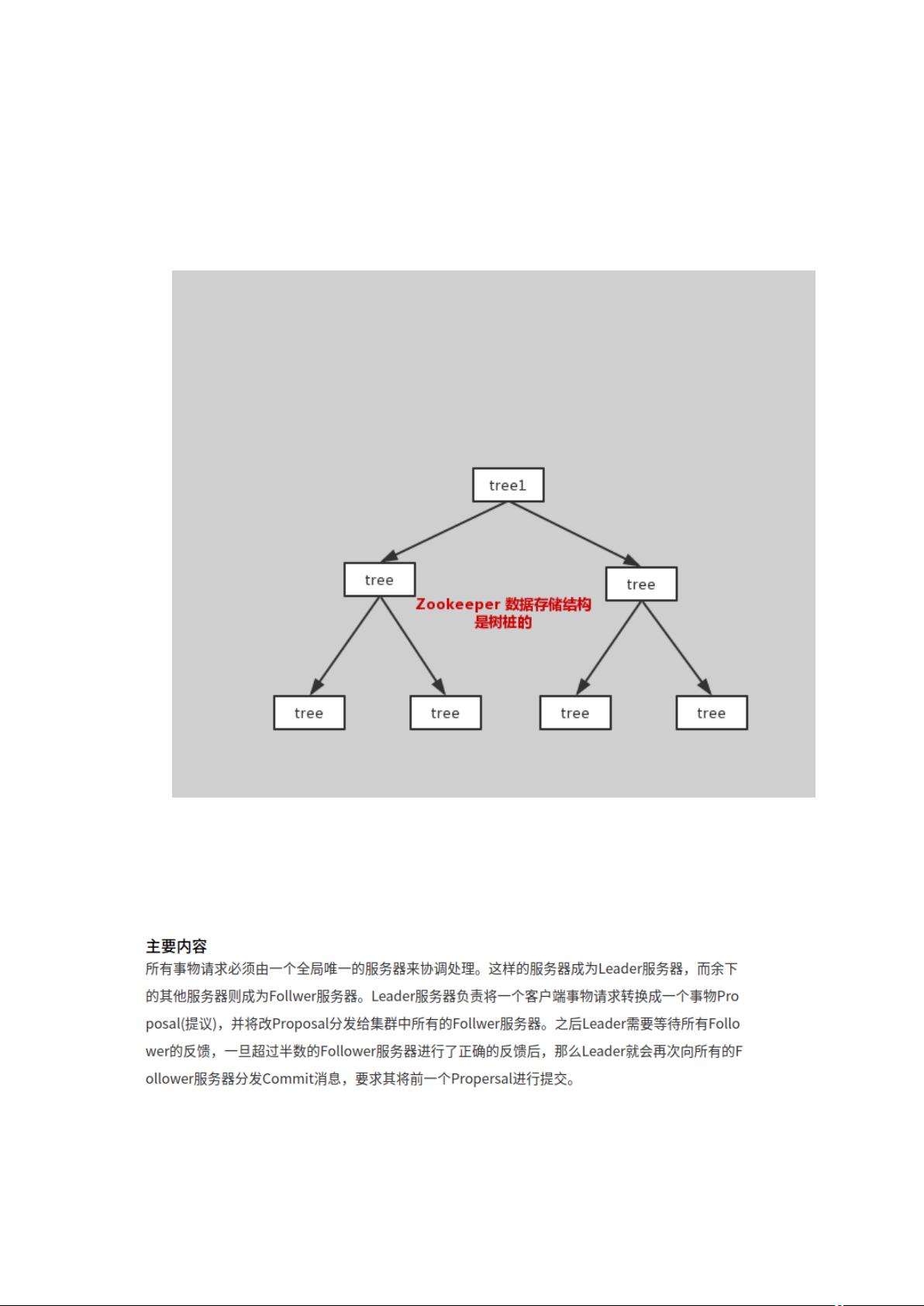
1、Zookeeper 数据结构
Zookeeper 的数据结构类似于文件系统,采用树形结构,由节点(Znode)组成。每个节点可以存储数据,也可以拥有子节点。Znodes分为四种类型:持久化节点(PERSISTENT)、持久化顺序节点(PERSISTENT_SEQUENTIAL)、临时节点(EPHEMERAL)和临时顺序节点(EPHEMERAL_SEQUENTIAL)。临时节点在创建它的客户端断开连接后会被自动删除,而持久节点则一直存在,直到被显式删除。
2、Zookeeper 协议 - ZAB(原子广播)协议
ZAB协议是Zookeeper实现数据一致性的关键,包含两个基本模式:崩溃恢复和消息广播。
- 崩溃恢复:当Leader节点故障时,Follower节点会通过选举选出新的Leader。选举过程遵循“选票数要大于集群总机器数的一半”的规则,确保新Leader的多数派支持,从而保证后续操作的一致性。
- 消息广播:所有写操作必须由Leader节点处理,Leader接收到写请求后,生成全局唯一的ZXID,并将请求广播给Follower。待所有Follower完成操作并回滚commit后,才确认事务完成。
3、Zookeeper 部署设备为什么是奇数
Zookeeper 集群通常部署奇数台服务器,这是为了确保在至少半数节点存活的情况下,集群仍能正常工作。例如,如果有3台服务器,即使挂掉1台,剩下的2台还能满足“选票数>集群总机器数/2”的条件,保持服务可用。若部署偶数台,一旦出现平票,将无法确定新Leader,导致集群瘫痪。
4、Zookeeper 的选举策略和投票策略
- 选举策略:当Leader节点故障,Follower会发起选举,发送包含myid(节点ID)和ZXID(事务ID)的投票给其他节点。Leader会比较接收到的投票,选择myid最大且ZXID最新的节点作为新Leader。
- 投票策略:Follower们会互相比较myid和ZXID,选取ZXID最大的节点进行投票。达到多数派共识的节点将成为新Leader。
5、Zookeeper 实现分布式事务 id 的唯一性
Zookeeper通过ZXID确保分布式事务ID的唯一性。所有的写操作都在Leader节点上执行,生成全局唯一的递增序列号ZXID。读操作可以从任何Follower节点获取,因为Follower会与Leader保持数据同步。这样,即使在分布式环境中,每个事务ID也能保持全局唯一和有序。
Zookeeper通过其独特的数据结构、ZAB协议以及选举和投票机制,确保了在分布式环境中的数据一致性、高可用性和事务唯一性,是构建分布式应用的重要组件。
1、Zookeeper 数据结构
2、Zookeeper 协议?
1.0.1 图
1.0.1 图主要讲解了 zookeeper 的两个主要内容点:第一 zookeeper 集群时如何保证数据的
下载后可阅读完整内容,剩余3页未读,立即下载
163 浏览量
2018-07-05 上传
2020-09-10 上传
2023-02-21 上传
2017-01-18 上传
2023-02-21 上传
资源评论


BellWang
- 粉丝: 28
- 资源: 315









最新资源
- dnmp-docker安装
- vue3-element-admin-前端
- srt-data-报告类资源
- rrserv-vmware虚拟机安装教程
- automated_ui-报告类资源
- EasyAi-Java资源
- ANR-WatchDog-ohos-报告类资源
- solon-Java资源
- 电机带动碟片切割机creo 3.0全套技术资料100%好用.zip
- 自动打铆钉系统机(sw18可编辑+工程图)全套技术资料100%好用.zip
- 自动定位锁螺丝机sw18可编辑全套技术资料100%好用.zip
- 自动焊接机器人sw18可编辑全套技术资料100%好用.zip
- 自动入脚打叉机sw20可编辑全套技术资料100%好用.zip
- 自动喷印设备sw20可编辑全套技术资料100%好用.zip
- 钻石点钻机sw18可编辑全套技术资料100%好用.zip
- 自动识别快递分拣系统sw20可编辑全套技术资料100%好用.zip
