20180509_深度学习损失函数的创新设计(稀疏与正交)1
需积分: 0 14 浏览量
2022-08-08
19:45:59
上传
评论
收藏 38KB DOCX 举报

深度学习损失函数的创新设计
我们的方法属于非参数判别方法,它倾向于由所提供样本数据直接求出在某一准则函数下的
最优参数,这种方法必须由分类器设计者首先确定准则函数,并根据样本数据和该函数最优
的原理求出函数的参数,因此关键是准则函数(损失函数 Loss 的设计)
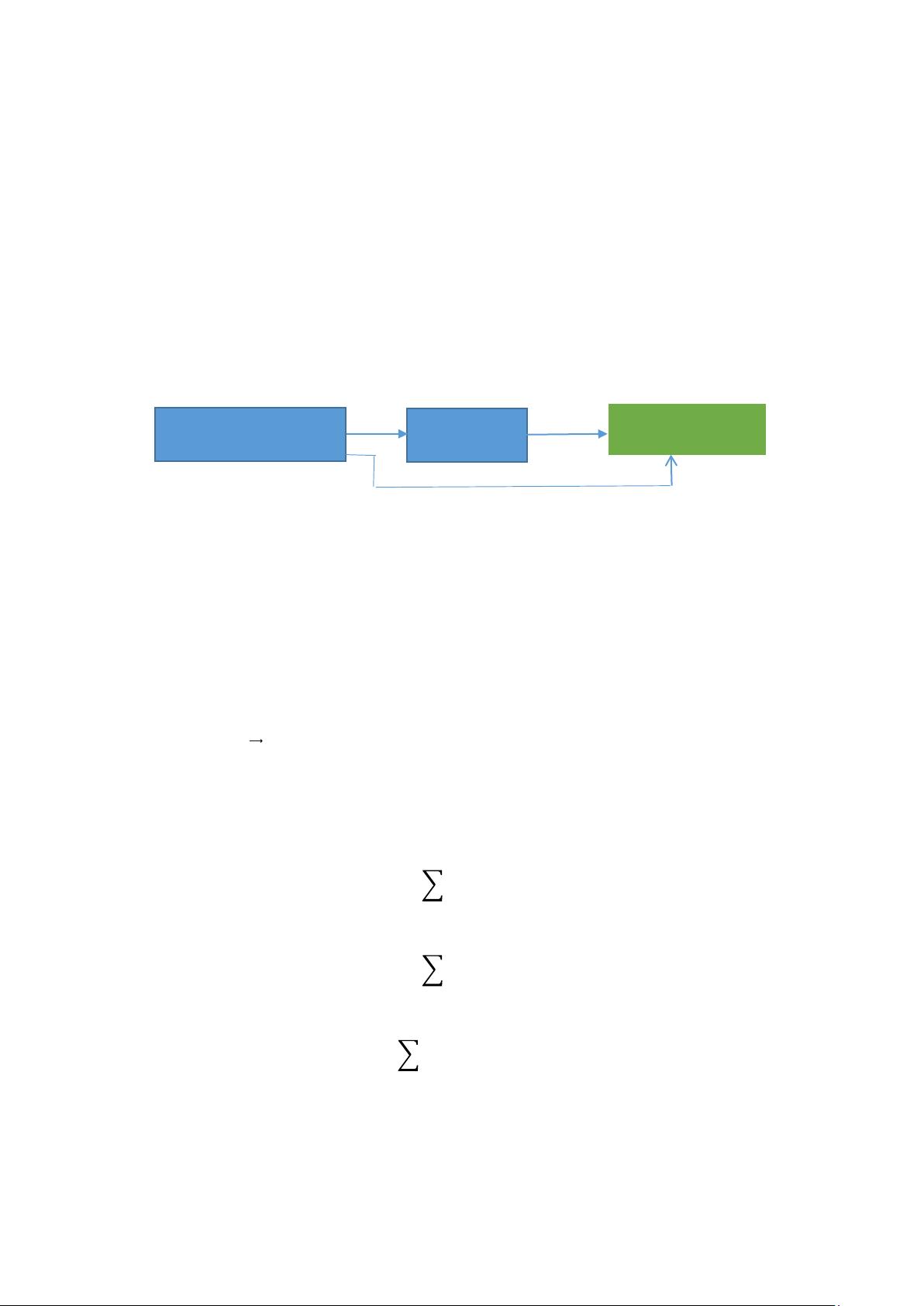
新的损失函数的基本结构
深度学习网络如 CNN
分类器
损失函数 Loss
增加特征空间的稀疏性的损失函数
抽取的特征空间可能是高维的,但越稀疏越好。稀疏性(公式(1))可以用来度量样本的多
样性,越稀疏,样本的多样性越好。其次,可以用少量的特征来表述,与简单性原则一致。
𝐽
1
=
∑
‖
𝑥
𝑖
‖
1
(1)
𝐽
2
=
∑
𝑥
𝑖
∙
𝑥
𝑗
(2)
公式(2)表达样本之间的正交性,越小越好,表明样本之间的区分性越好。
𝐿𝑜𝑠𝑠
=
min
𝑊
𝑁
𝑖
=
1
‖
𝑦
𝑖
―
𝑓(
𝑥
𝑖
)
‖
+
𝛾
1
𝐽
1
𝐿𝑜𝑠𝑠
=
min
𝑊
𝑁
𝑖
=
1
‖
𝑦
𝑖
―
𝑓(
𝑥
𝑖
)
‖
+
𝛾
1
𝐽
2
𝐿𝑜𝑠𝑠
=
min
𝑊
𝑁
𝑖
=
1
‖
𝑦
𝑖
―
𝑓(
𝑥
𝑖
)
‖
+
𝛾
1
𝐽
1
+
𝛾
2
𝐽
2
这个规则也可以用来做选择性集成,选择集成的分类器。
资源评论













