
正则化输入
一、过拟合问题
1.欠拟合与过拟合
泛化能力:在先前为观测到的输入数据上表现良好的能力
过拟合:将训练样本的一些特有的特点也当作潜在样本的一般性质,进而导致泛化能
力下降。
欠拟合:训练样本性质没有学习完全,进而导致泛化能力较低。
决定机器学习算法效果的两个因素:
降低训练误差(对应欠拟合)
缩小训练误差和测试误差的差距(对应过拟合)
补充:欠拟合是指模型不能在训练集上获得足够低的误差,而过拟合是指训练误差和
测试误差之间的差距太大
2.独立同分布假设
训练集和测试集数据通过数据集上被称为数据生成过程的概率分布生成,假设每个数
据集中的样本都彼此相互独立,并且训练集和测试集都是同分布,采样自相同的分布,
我们将这个共享的潜在分布成为数据生成分布,即为 pdata,这就是独立同分布假设,
这使得我们能够用单个样本的概率分布表述数据生成过程。
在独立同分布的夹设下,训练样本的误差等于潜在样本的无查,只需要尽可能降低训
练无查即可。(实际上假设基本不能成立,而并不影响使用该假设)
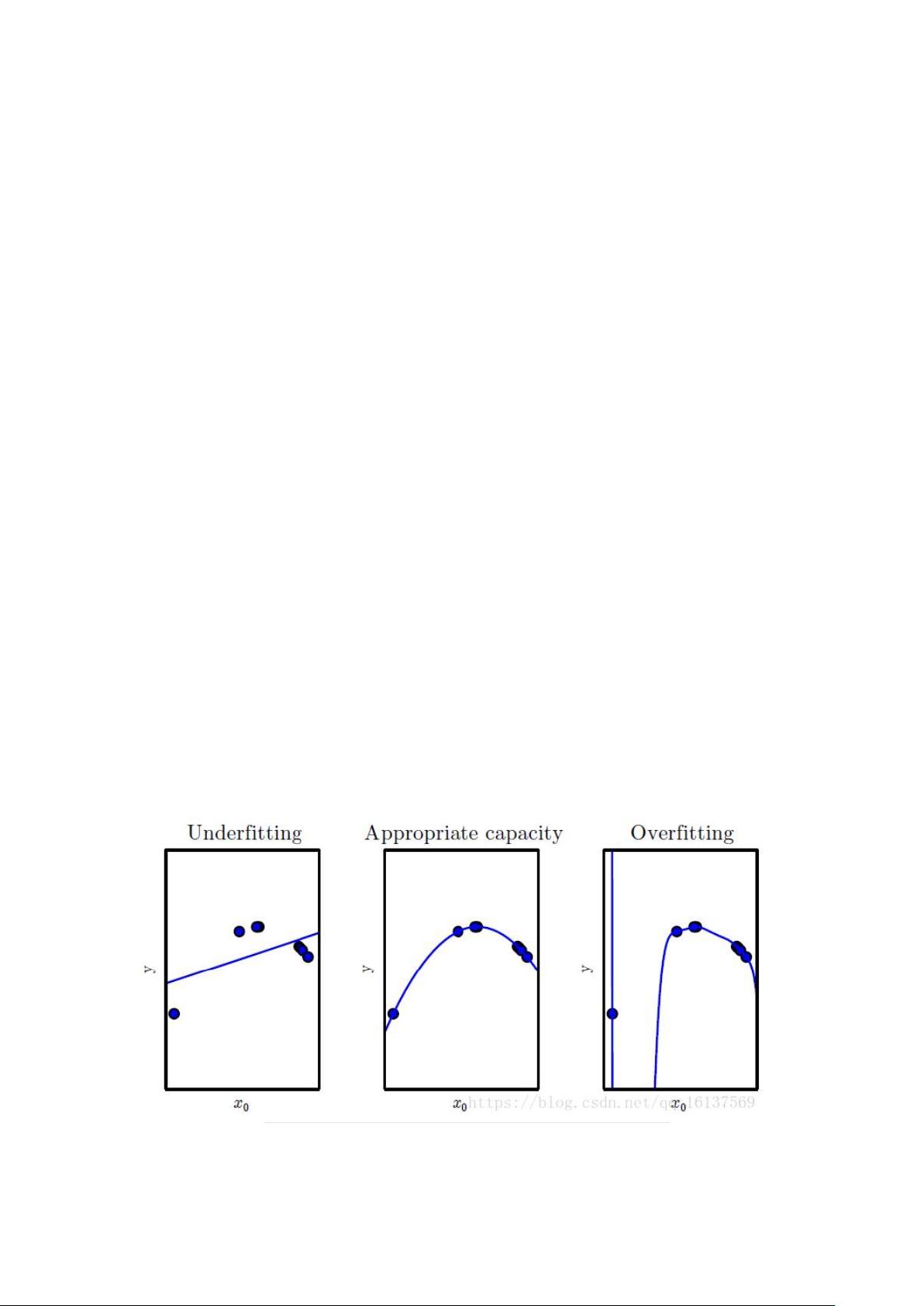
3.模型容量与过拟合
模型容量:指其拟合各种函数的能力。
我们可以通过调整模型的容量,控制模型是否偏向于过拟合与欠拟合。
过拟合、适当拟合、欠拟合:
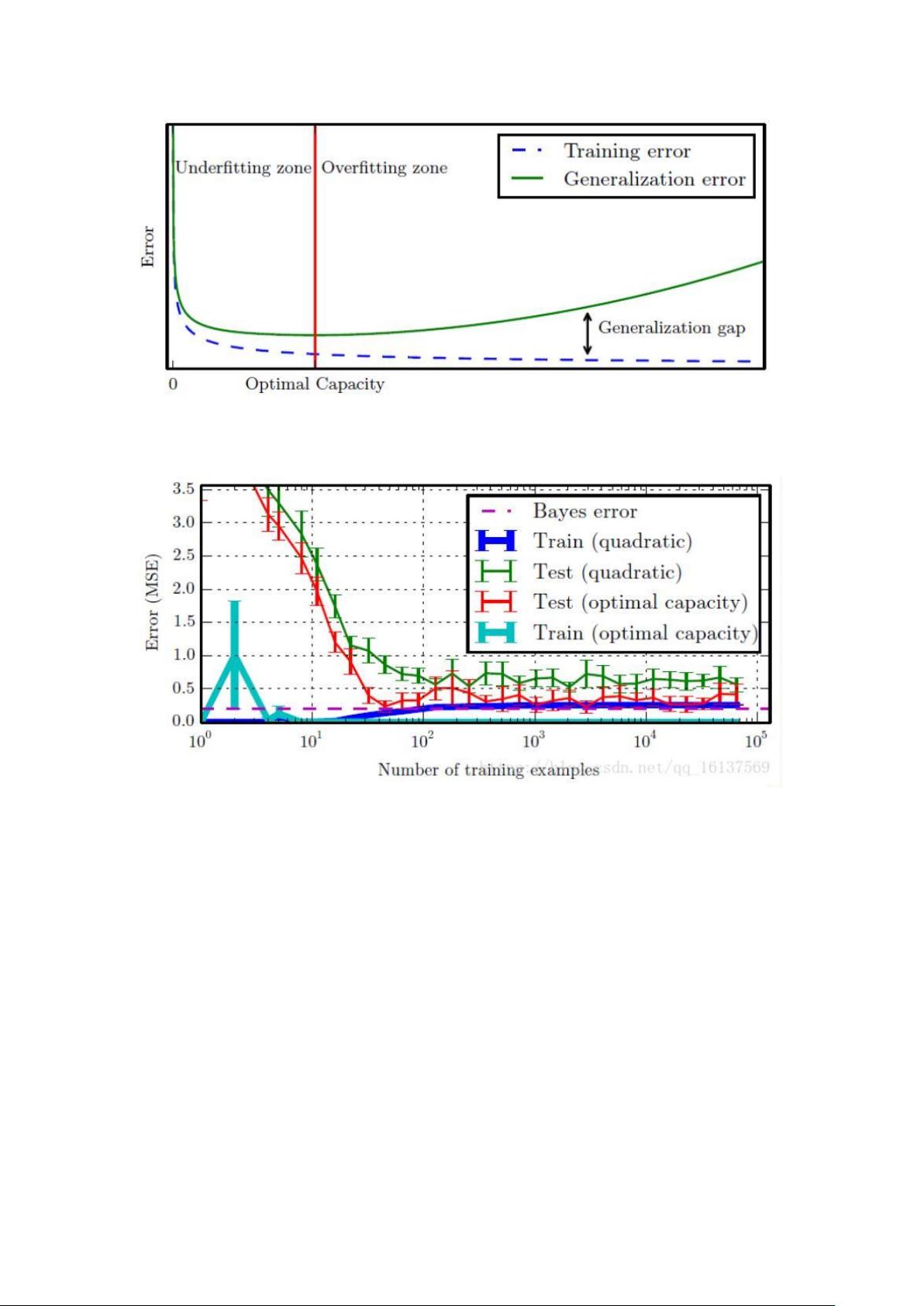
容量与误差之间典型关系:
剩余7页未读,继续阅读













评论0