
通信1701 胡成成 41724260
作业1:Apriori与FP-Growth算法比较
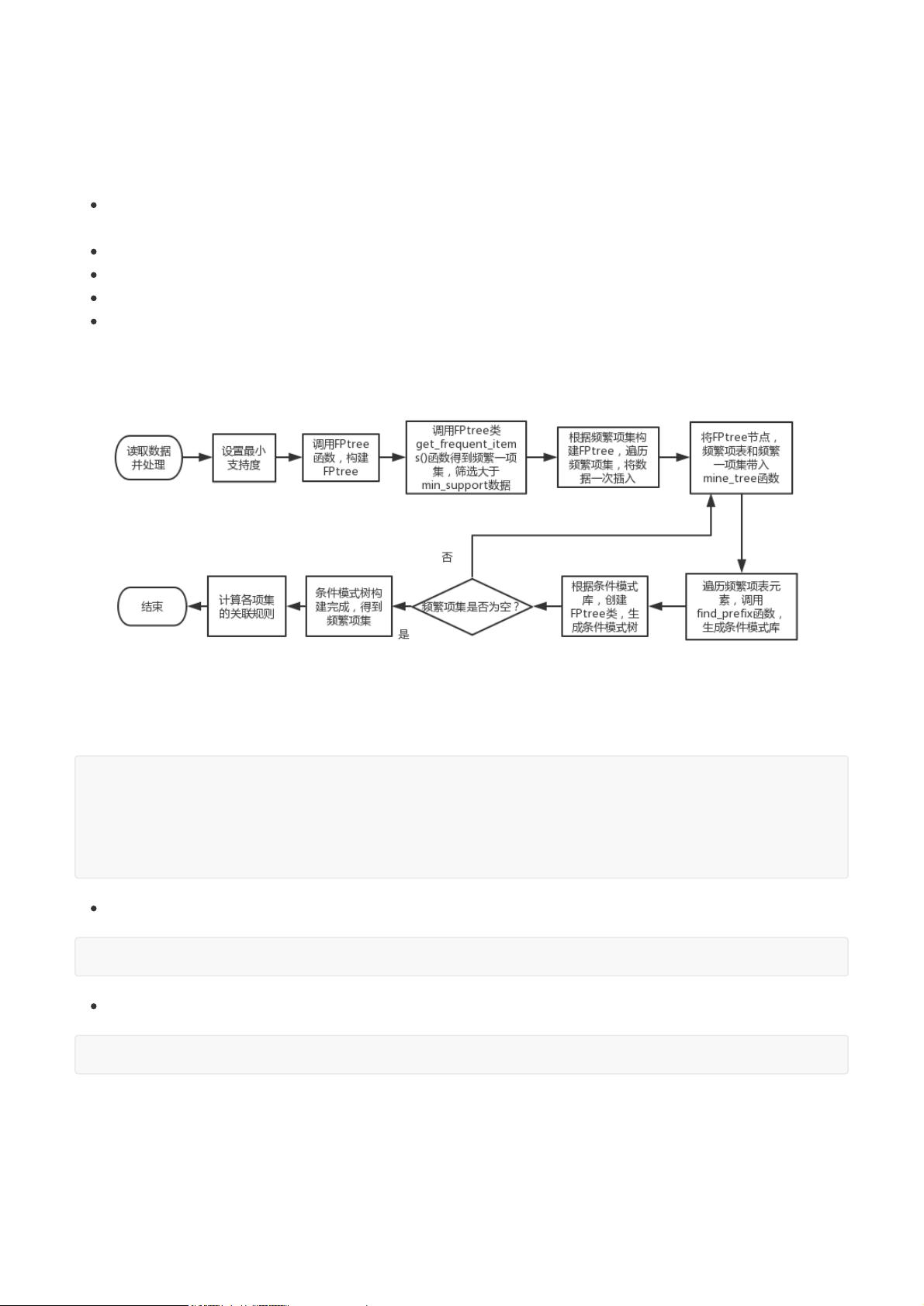
1. Apriori 与FP-Growth算法流程图
1.1. 概念回顾
支持度:P(A ∩ B),既有A又有B的概率
置信度:P(B|A),在A发生的事件中同时发生B的概率 p(AB)/P(A)
频繁k项集:如果事件A中包含k个元素,那么称这个事件A为k项集事件A满足最小支持度阈值的事件称为频繁k
项集
强规则:同时满足最小支持度阈值和最小置信度阈值的规则称为强规则
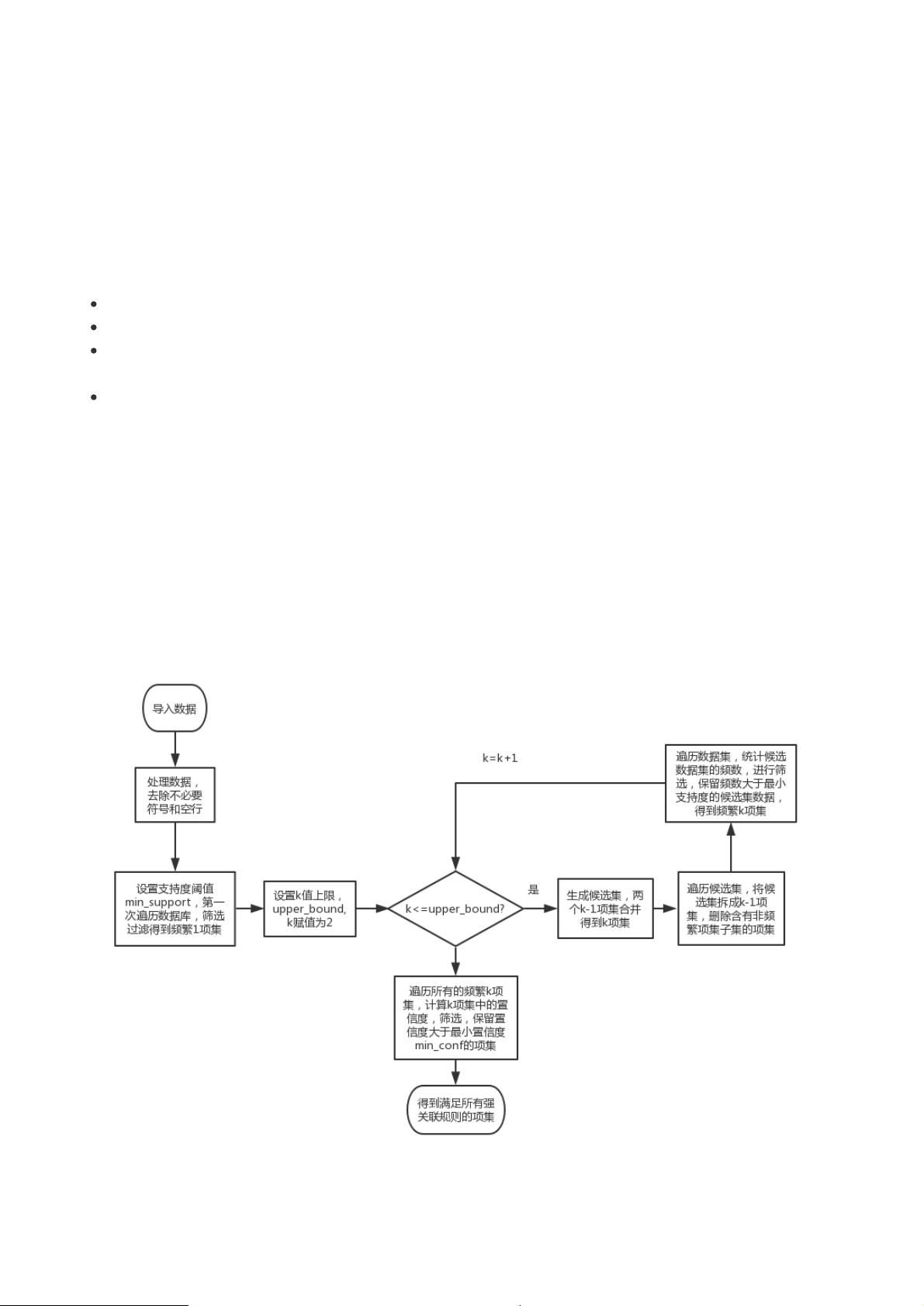
1.2. Apriori 算法过程
1.2.1 算法描述
第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;
第二步利用频繁项集构造出满足用户最小信任度的规则。具体做法就是:首先找出频繁1-项集,记为L1;然后利用L1
来产生候选项集C2,对C2中的项进行判定挖掘出L2,即频繁2-项集;不断如此循环下去直到无法发现更多的频繁k-
项集为止。每挖掘一层Lk就需要扫描整个数据库一遍。
1.2.2 算法流程图
剩余7页未读,继续阅读

是因为太久
- 粉丝: 24
- 资源: 295









最新资源
- java项目,毕业设计-家具商城系统
- sparse-occ-cpu.onnx
- c2532703d1b4e83f570f28ff6cf94aef_语法.pdf
- C# 将不限数量的Excel表格进行合并,支持多文件多表合并.zip
- java项目,毕业设计-体育场馆运营
- 阿里云联合中国信通院安全所发布-大模型安全研究报告2024
- 低空经济政策与产业生态研究报告(2024年)
- 基于微信小程序的手机商城的设计与实现ssm.zip
- 基于springboot汽车维修管理系统微信小程序springboot.zip
- 非常好用 的一款,网卡流量监控工具,可长时间 监控,有图标展示流量趋势,要记录一段时间 内的平均 流量,可单独记录每个网卡的流量, 绿色好用, 无功能 限制
- 基于微信小程序的医院挂号预约系统ssm.zip
- 基于机器学习的商品评论分析系统源代码+文档说明+GUI界面(高分项目)
- 基于微信小程序的校园二手交易平台ssm.zip
- 基于微信小程序的校园综合服务平台ssm.zip
- 基于微信小程序高校订餐系统的设计与开发ssm.zip
- 线性回归实现股票预测源代码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0