
Python 自然语言处理
NLTK 入门(详细使用见官网:http://www.nltk.org/)
安装
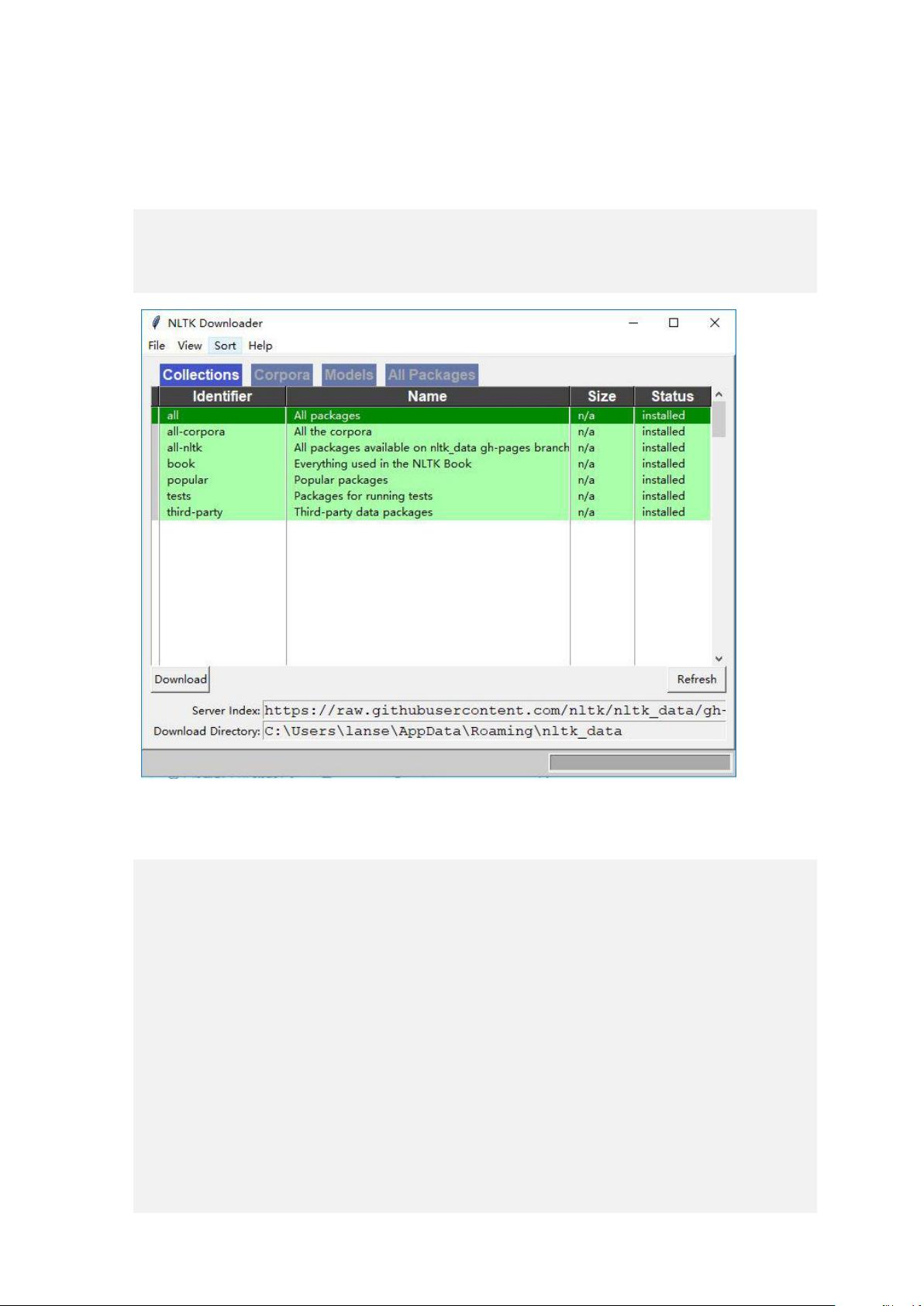
选择需要的包安装,建议默认路径下载,全部包安装大概需要 2G 内存
测试安装是否成功
pip install nltk
>>> import nltk
>>> nltk.download()
>>> from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908













评论0