
实验 4 图的三角形计数
1. 实验要求
实验背景
图的三角形计数问题是一个基本的图计算问题,是很多复杂网络分析(比如社
交网络分析)的基础。目前图的三角形计数问题已经成为了 Spark 系统中 GraphX 图计算库
所提供的一个算法级 API。本次实验任务就是要在 Hadoop 系统上实现 Twitter 社交网络图的
三角形计数任务。
实验任务
一个社交网络可以看做是一张图(离散数学中的图)。社交网络中的人对应于图的顶点;社
交网络中的人际关系对应于图中的边。在本次实验任务中,我们只考虑一种关系——用户之
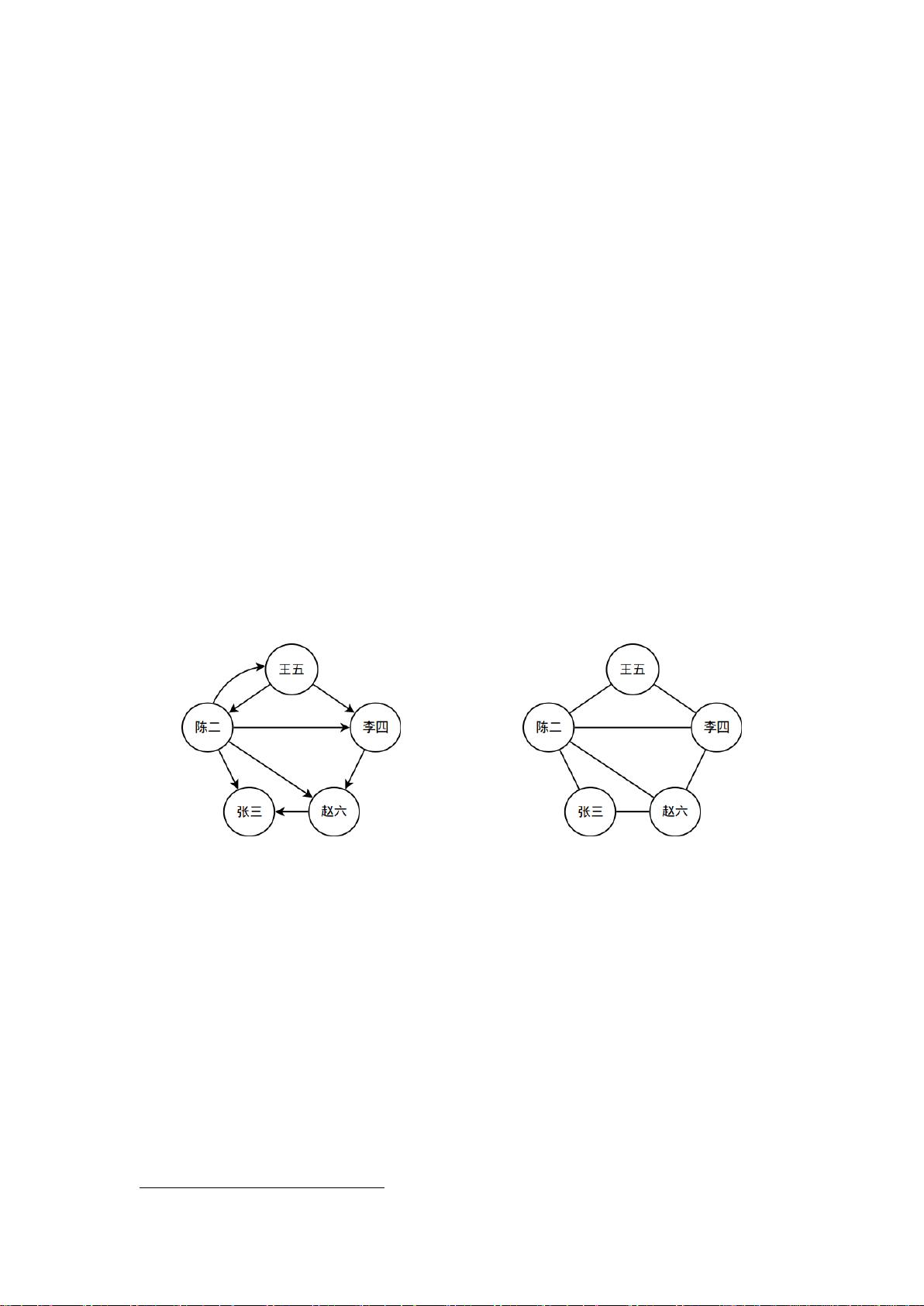
间的关注关系。假设“王五”在 Twitter/微博中关注了“李四”,则在社交网络图中,有一条对
应的从“王五”指向“李四”的有向边。图 1 中展示了一个简单的社交网络图,人之间的关注关
系通过图中的有向边标识了出来。。
图 1 一个简单的社交网络示例。左侧的是一个社交网络图;右侧的图是将左侧图中的有向边转
换为无向边后的无向图。
本次的实验任务就是在给定的社交网络图中,统计图中所有三角形的数量。
在统计前,需要先进行有向边到无向边的转换,依据如下逻辑转换:
IF ( A→B) OR (B→A) THEN A-B
“A→B”表示从顶点 A 到顶点 B 有一条有向边。A-B 表示顶点 A 和顶点 B 之间有一条无向边。
一个示例见图 1,图 1 右侧的图就是左侧的图去除边方向后对应的无向图。
请在无向图上统计三角形的个数。在图 1 的例子中,一共有 3 个三角形。
资源评论


明儿去打球
- 粉丝: 19
- 资源: 327









最新资源
- vk162、vk172安卓车机驱动+软件+教程
- STM32开发 FIR高通滤波器 STM32实现FIR有限冲击响应高通滤波器,自编代码,汉明窗,送MATLAB程序,代码注释详细
- 20kw光伏逆变器 20KW双路光伏BOOST三相三电平光伏并网逆变器 带两路boost追踪MPPT 主控平台:TMS320F28335+TM320F28035 逆变拓扑:三相三电平逆变 功能:并网发
- 分时电价下用户需求侧响应优化调度 摘要:为研究需求侧响应随着分时电价的响应策略,构建了含有可中断负荷、可转移负荷在内的需求侧优化调度模型,研究分时电价下可中断、可转移负荷的具体调度策略,并通过图展示其
- 风电-光热-生物质混合电站鲁棒优化调度模型 摘要:为解决混合电站参与电力市场运行问题,从混合电站的结构及运行机理出发,提出了电力市场下风电-光热-生物质混合电站鲁棒优化调度模型 该模型以最大化运行利
- 机器学习(图像识别):排球球体检测数据集
- 计及电动汽车灵活性的微网多时间尺度协调调度模型 摘要:构建了含有电动汽车参与的微网 电厂多时间尺度协调优化模型,其中包括日前-日内-实时三阶段,日前阶段由于风光出力具有不确定性,结合风光预测值作初步经
- 用COMSOL 模拟双重介质注浆模型,浆液在多孔介质和裂隙中流动 裂隙为浆液流动的优势通道,明显快与无裂隙的基质通道 裂隙为随机均匀分布 注:本算例考虑浆液的渗滤效应 浆液粘度随扩散距离增加而
- 牛拉法电力系统潮流计算 MATLAB编写潮流计算程序 BPA计算潮流 另外包含参考文献 这个程序把潮流计算的一般流程包括了,非常适合基础学习,并进一步的进行拓展创新
- 模型及MATLAB代码:考充分考虑并结合疫情下封控区域生活物资配送问题及车辆路径问题的特点构建物资配送优化模型 在一般单一目标-时间最短的基础上,加入综合满意率优化目标的路径优化问题 关键词:遗传
- carsim,simulink联合仿真,自动驾驶基于mpc自定义期望速度跟踪控制,可以在外部自定义期望速度传入sfunction函数,设置了两个不同状态方程,控制量为加速度,加速度变化量提供进行对比
- 机器学习(预测模型):外国援助是指一个国家或实体向另一个国家或实体提供资金、物资或服务的行为
- 永磁同步电机的控制算法仿真模型: 1. 永磁同步电机的MRAS无传感器矢量控制: 2. 永磁同步电机的SMO无传感器矢量控制(反正切+锁相环); 3. 永磁同步电机DTC直接转矩控制; 4. 永磁同步
- MATLAB代码:电动汽车有序充电策略 关键词:电动汽车;有序充电;分时电价;鸡群算法 使用软件:MATLAB(有注释,易理解) 参考lunwen:基于峰谷分时电价引导下的电动汽车充电负荷优化-欧名
- 永磁同步电机谐波注入、谐波抑制5 7次谐波电流,MATLAB simulink仿真模型 欢迎来交流学习 主要有以下: 1.改善三相电流波形的正弦度,抑制电机电磁转矩脉动和转速波动 2.削弱三相电
- 115个Java面试题和答案-终极-尚硅谷-宋红康.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


