18302010018-俞哲轩-lab1-part11

需积分: 0 21 浏览量
更新于2022-08-03
收藏 2.09MB PDF 举报
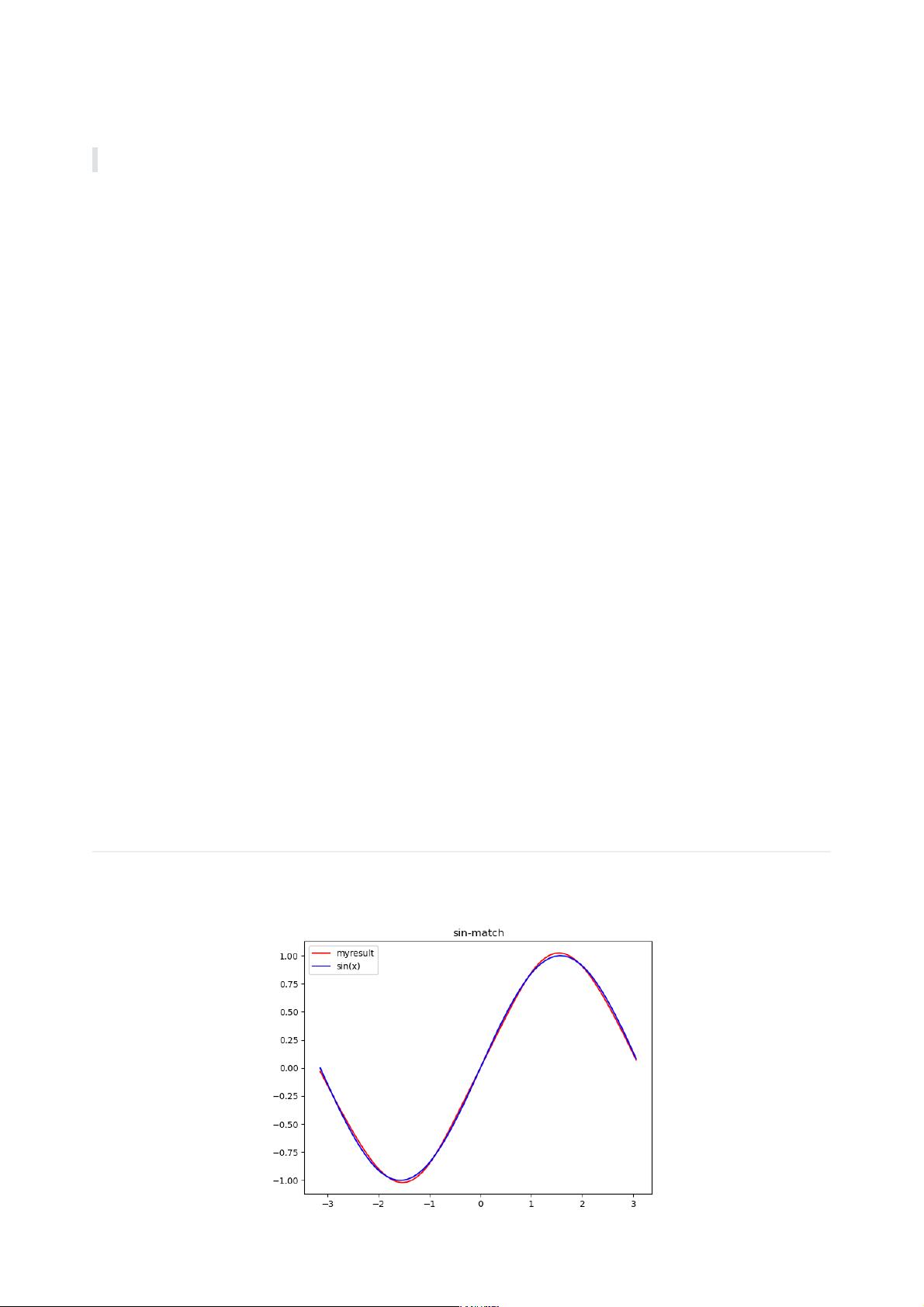
在给定的代码段中,我们看到了一个简单的神经网络实现,包括`Network`类和`Layer`类。这个网络主要用于处理sin函数的12周期数据,并应用了不同的激活函数,如Sigmoid、Tanh以及Leaky ReLU(LeRU)。让我们深入探讨这些知识点:
1. **网络结构**:
`Network`类包含了网络的结构信息,通过`size`属性表示层数,`layers`列表存储各个层对象。构造函数`Network(int[] structure, boolean classification, double weightLR, double biasLR)`接收网络结构数组(每层神经元数量),分类任务标识,以及权重和偏置的学习率。
2. **前向传播**:
`forward(double[] input)`方法实现了前向传播过程。输入层的神经元将输入数组赋值为输出。然后,从第二个层(隐藏层)开始逐层进行前向传播,直到最后一层(输出层)。
3. **反向传播**:
`backward(double[] desired)`方法执行反向传播。计算输出层的误差(delta),然后从最后一个层开始回溯,对每个层的神经元进行误差反向传播,直到输入层。
4. **Softmax函数**:
`softmax()`方法用于将输出层神经元的激活值转换为概率分布。它计算所有神经元输出的指数和,然后除以该和,确保所有输出之和为1,符合概率的要求。
5. **层的实现**:
`Layer`类代表网络中的单个层,包含神经元数组`neurons`,前后相邻层的引用,以及学习率属性。构造函数`Layer(int quantity, Layer backLayer, boolean classification, double weightLR, double biasLR)`初始化层的大小、前一层、是否为分类层,以及权重和偏置的学习率。
6. **激活函数**:
- **Sigmoid**:这是一个S-shaped函数,输出范围在0到1之间,常用于二分类问题,因为其输出可以解释为概率。
- **Tanh**:双曲正切函数,输出范围在-1到1之间,相比Sigmoid,通常能提供更好的梯度分布。
- **Leaky ReLU(LeRU)**:修正线性单元,解决了ReLU在负区的梯度消失问题,允许小量负值通过,以保持神经元的激活。
7. **学习率**:
权重和偏置的学习率(`weightLR`和`biasLR`)控制着参数更新的速度。较高的学习率可能导致训练更快,但可能不稳定;较低的学习率则可能使训练更稳定,但收敛速度较慢。
8. **随机性**:
`Random`类的实例`rd`用于初始化权重和偏置,这是训练过程中引入随机性的常见方式,有助于跳出局部最优解。
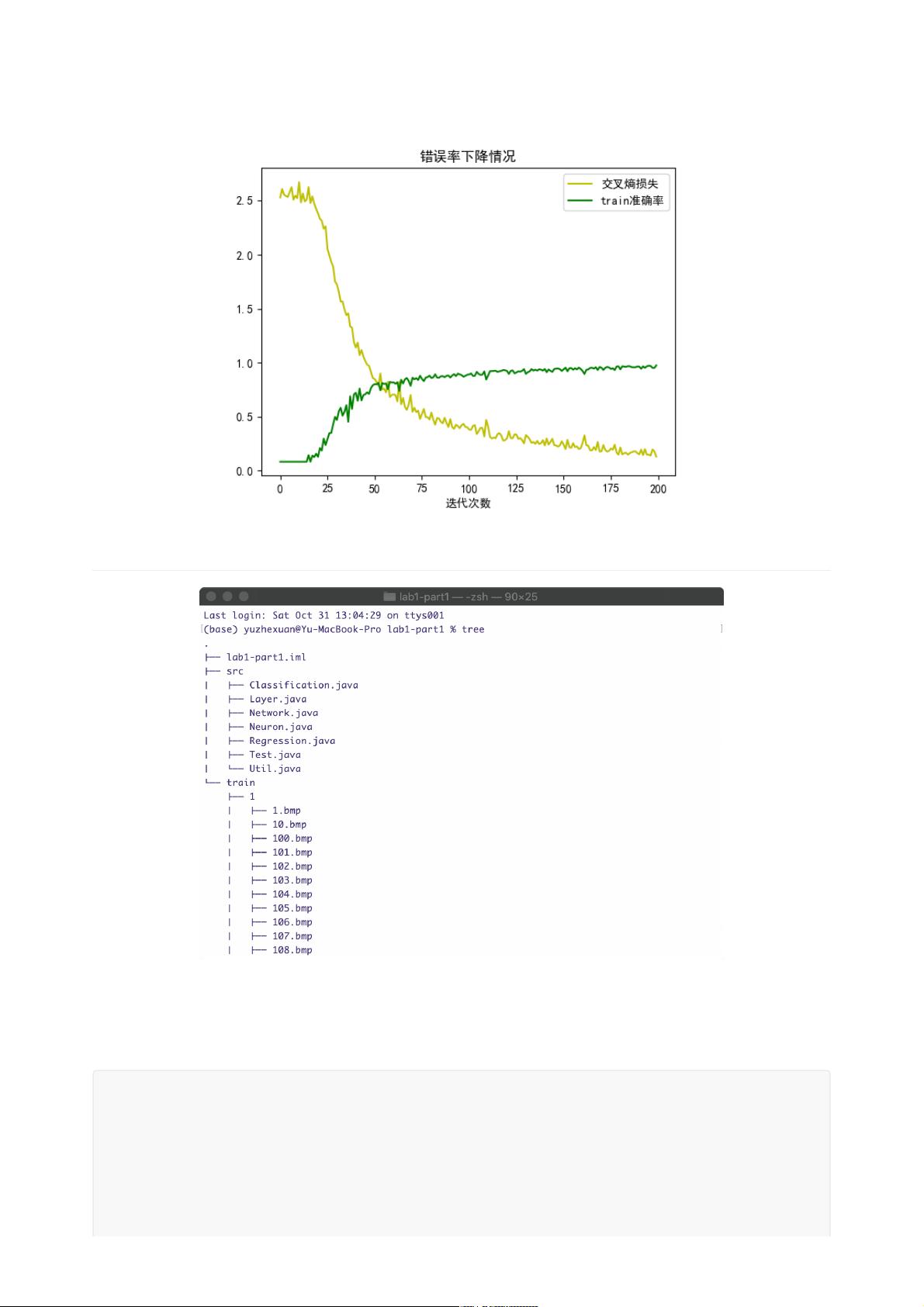
这个简化的神经网络模型虽然基础,但它展示了深度学习模型的核心元素,如前向传播、反向传播和激活函数的选择。在实际应用中,还需要包括权重和偏置的更新规则(如梯度下降或其变体)、损失函数以及训练循环等更多细节。
190 浏览量
104 浏览量
2011-04-29 上传
2022-04-16 上传
190 浏览量
166 浏览量
168 浏览量
196 浏览量
197 浏览量
168 浏览量
2018-06-07 上传
103 浏览量
187 浏览量
136 浏览量
145 浏览量
2011-04-29 上传
122 浏览量
2011-04-29 上传
163 浏览量
2019-04-09 上传
126 浏览量
2022-07-11 上传
2022-07-11 上传
资源评论


明儿去打球
- 粉丝: 19
- 资源: 327









最新资源
- 西门子200SMART系列PLC自由口通讯CRC校验程序 该程序已经实测
- 基于事件触发机制的多智能体系统事件触发控制,Matlab数值仿真实验
- 基于Dart语言的Flutter应用开发设计源码
- 基于SpringBoot与阿里云AI的智慧云相册双端设计源码
- 基于maven-assembly-plugin的Spring Boot项目环境打包设计源码
- 串联混合动力汽车模型预测能量管理程序设计,在MATLAB环境下,利用脚本编写串联模型,并基于CasADi模型预测控制算法工具,结合构型图与参数进行MPC能量算法程序编制,测试工况为CLTC-P工况(可
- microsoft-edge-dev-133.0.3014.0-1.x86_64.rpm
- abaqus 随机喷丸仿真,附带随机喷丸模型生成源程序,模型尺寸,丸粒尺寸,个数,角度,速度等均可自由改动 源程序讲解视频,模型操作,后处理操作,模型文件均有 喷丸微观仿真
- comsol实现激光熔覆的凝固相场树枝晶生长 考虑溶质、 相场 温度场耦合 提供资料 全套的模型文件和参考文献以及讲解视频 利用凝固组织的建模和验证可以减少获得所需组织的迭代成本 结合Marango
- 双馈电机三矢量模型预测控制
- 基于深度混合核极限学习机DHKELM的回归预测,优化算法采用的是北方苍鹰NGO,可替成其他方法
- 多项式曲线拟合,c代码,可实现1阶线性,2-4阶多项式曲线拟合,代码注释详细,方便移植,书写规范 图片有现场拟合参数的1-4阶的keil仿真结果和Excel对照图 备注一下,这是个多项式求解代码,求
- 基于SpringCloud的ZebraCloud设计源码项目,JavaScript与Java双语言支持,正在孵化中...
- 基于Yapi接口平台的接口方法文件自动生成设计源码
- 事件触发,微电网分层下垂控制 有应用图中文献算法的matlab仿真模型
- 基于Python的DNF装备搭配及伤害计算设计源码
