20190617-华泰证券-华泰人工智能系列之二十二:基于CSCV框架的回测过拟合概率1
需积分: 0 182 浏览量
2022-08-03
20:56:01
上传
评论 1
收藏 2.41MB PDF 举报


谨请参阅尾页重要声明及华泰证券股票和行业评级标准 1
证券研究报告
金工研究/深度研究
2019 年06 月17 日
林晓明
执业证书编号:S0570516010001
研究员
0755-82080134
陈烨
执业证书编号:S0570518080004
研究员
010-56793942
李子钰
0755-23987436
联系人
何康
021-28972039
联系人
1《金工: 桑土之防:结构化多因子风险模型》
2019.06
2《金工: 基于遗传规划的选股因子挖掘》
2019.06
3《金工: 华泰单因子测试之海量技术因子》
2019.05
基于 CSCV 框架的回测过拟合概率
华泰人工智能系列之二十二
基于 CSCV 框架计算三组量化研究案例的回测过拟合概率
本文基于组合对称交叉验证(CSCV)框架,以三组量化研究为案例展示
回测过拟合概率(PBO)的计算流程,发现两组多因子选股模型的 PBO
较低,择时模型的 PBO 较高。案例 1 为 7 种机器学习模型的多因子选股
策略,指数增强组合 PBO 大多在 15%~50%,“ XGBoost 表现最佳”的结
论大概率不是回测过拟合。案例 2 为 6 种交叉验证方法的多因子选股策略,
多空组合 PBO 在 20%~50%,“分组时序交叉验证表现最佳”的结论大概
率不是回测过拟合。案例 3 为双均线 50ETF 择时策略,PBO 在 50%~90%,
“参数组合[11,30]和[11,24]表现最佳”的结论可能为回测过拟合。
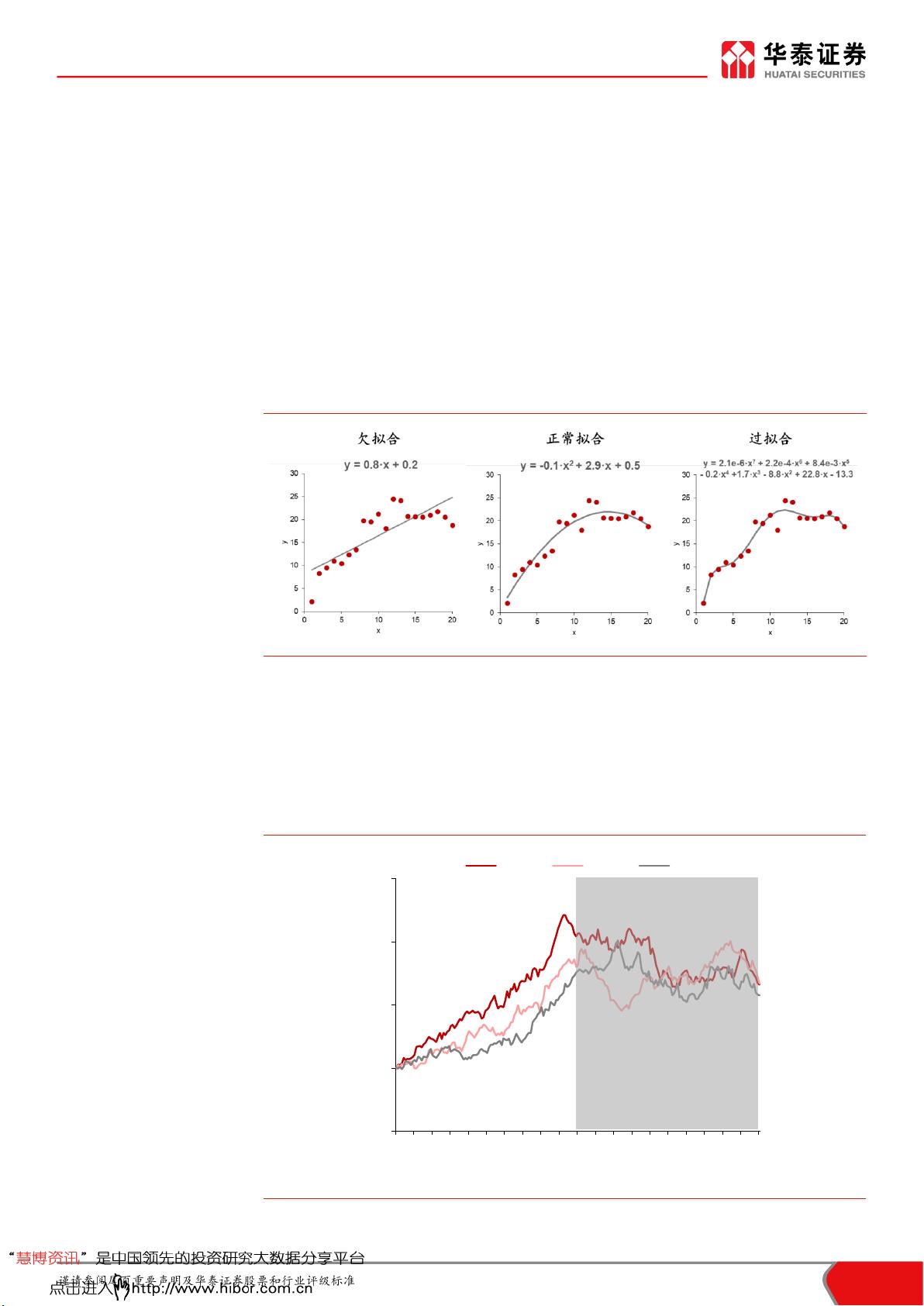
过拟合可分为两个层次:训练过拟合和回测过拟合
华泰人工智能系列多项研究探讨过拟合。过拟合可分为训练过拟合和回测
过拟合两个层次。训练过拟合是机器学习语境下偏狭义色彩的过拟合,是
指机器学习模型在训练集表现好,在测试集表现差,产生原因是模型超参
数选择不当或者模型过度训练,解决方案是采用合理的交叉验证方法选择
模型超参数或迭代次数。回测过拟合是量化研究语境下偏广义色彩的过拟
合,是指量化模型在回测阶段表现好,在实盘阶段表现差,产生原因是市
场规律发生变化,或者对回测期数据噪音的过度学习。回测过拟合难以根
除,相对合理的解决方案是借助量化指标检验回测过拟合程度。
核心思想是计算“训练集”夏普比率最高的策略在“测试集”的相对排名
CSCV 框架下回测过拟合概率的核心思想是:计算“训练集”夏普比率最
高的策略,在“测试集”中的相对排名,如果相对排名靠前,代表回测过
拟合概率较低,反之则代表回测过拟合概率较高。“训练集”和“测试集”
的划分基于组合的思想,将全部回测时间划分成 S 份,任取其中 S/2 份拼
接得到“训练集”,剩余 S/2 份拼接得到“测试集”,分别计算各条策略的
夏普比率,进而得到相对排名,并重复多次,将相对排名大于 50%即排在
后一半的概率视作回测过拟合概率。回测过拟合概率的计算相对简单,不
仅适用于机器学习策略,还能推广到其它类型的量化策略。
探讨回测过拟合概率计算过程中的各项细节
回测过拟合概率的计算过程中包含多项细节。将长度为 T 的全部回测时间
划分成 S 份,每份回测时间长度为 T/S。T/S 越小,组合次数越大,计算
时间开销越大;T/S 越大,组合次数越小,策略排名结果受偶然性因素影
响更大,实际使用时建议采用较小的 T/S 比。对策略进行排名时一般采用
夏普比率,也可以根据实际需要选择其它评价指标,例如本文的指数增强
组合采用信息比率进行排名更为合理。
风险提示:多因子选股和择时等量化模型都是对历史投资规律的挖掘,若
未来市场投资环境发生变化,则量化投资策略存在失效的可能。回测过拟
合概率是将历史回测表现的时间序列经过简单打乱重排计算得到,忽略回
测的路径依赖特性,存在过度简化的可能。
相关研究



剩余21页未读,继续阅读






评论0
最新资源