中文文本分类方法综述_于游1

需积分: 0 146 浏览量
更新于2022-08-03
收藏 847KB PDF 举报
中文文本分类是当前信息技术领域的研究焦点,它涉及到如何高效地将大量文本数据归类到预定义的类别中。这一过程通常包括多个步骤,如文本预处理、分词、特征提取和分类模型的建立。文本分类在信息检索、智能推荐系统、社交媒体监控等多个领域都有广泛应用。
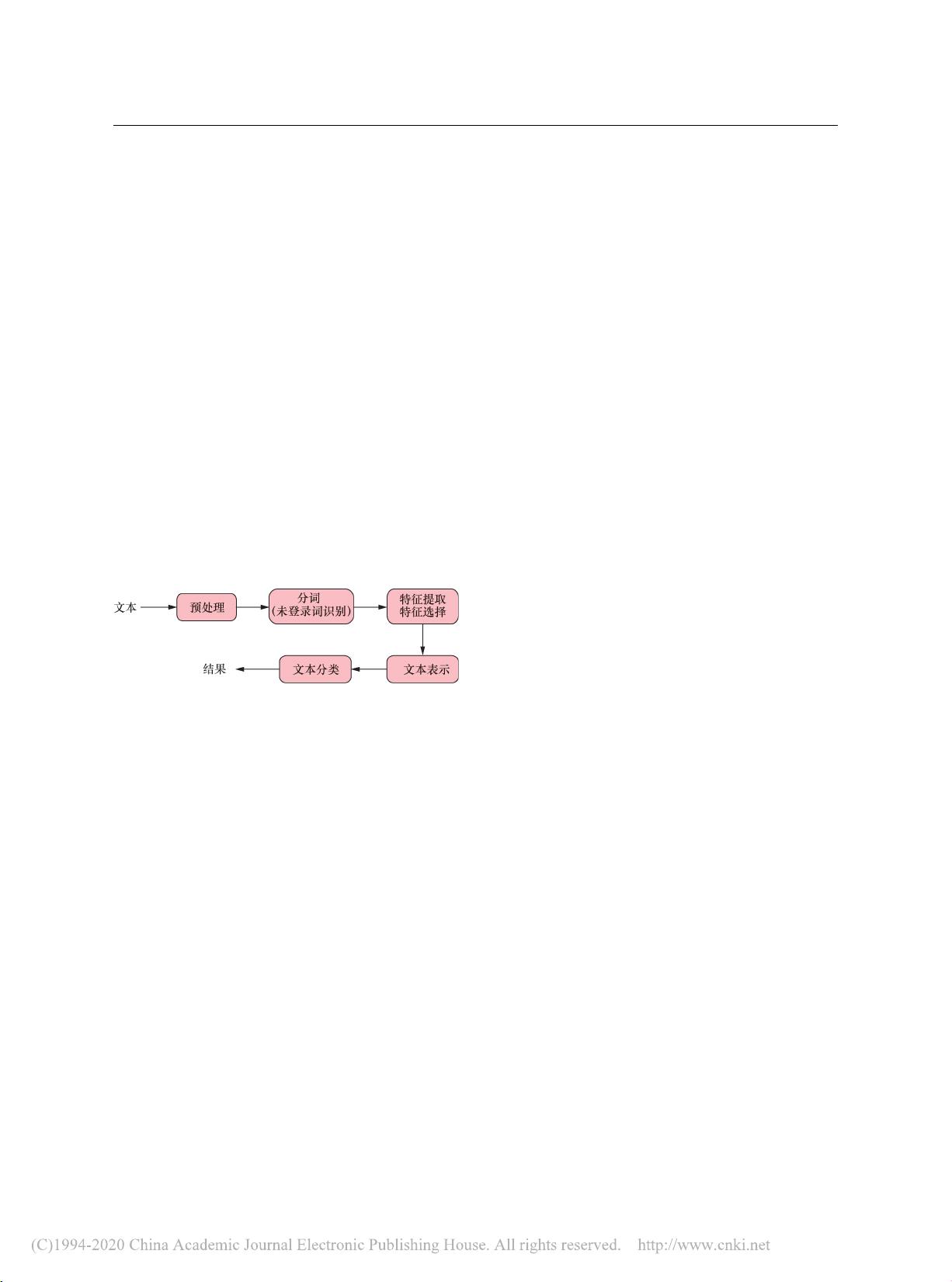
文本分类的概念是基于一定的分类标准或规则,将文本自动分配到相应的类别中。这个过程通常包含四个主要步骤:预处理、分词、特征提取和模型构建。预处理阶段是为了去除文本中的噪声,如标点符号、停用词等,以便更好地进行后续处理。分词是中文文本处理的关键,它将连续的字符序列切割成具有语义意义的词汇单元,对于中文来说,由于没有明显的空格分隔,这一过程相对复杂。分词技术包括基于词典的分词、统计分词和深度学习分词等方法。
接着,特征提取和选择是文本分类中的重要环节。特征是从原始文本中抽取出来,能够反映文本本质属性的信息。常见的特征表示方法有词袋模型(Bag-of-Words)、TF-IDF(Term Frequency-Inverse Document Frequency)以及词向量(Word Embedding)。特征选择则是在所有可能的特征中挑选出最具代表性和区分性的特征,以降低计算复杂度,提升分类效果。
文本分类的方法多样,传统的机器学习方法如朴素贝叶斯、支持向量机(SVM)、决策树等常被用于文本分类。近年来,随着深度学习的发展,卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)以及Transformer等模型在文本分类任务上展现出强大的性能,尤其在处理长文本和理解上下文方面。
然而,现有的文本分类技术还面临着一些挑战,如语义理解的难度、词序信息的处理、多义词和同义词的识别、大规模词汇表的管理以及实时性需求等。为了应对这些挑战,研究人员正在探索更先进的自然语言处理技术,如预训练模型(BERT、GPT等)和自注意力机制,以提高分类的准确性和泛化能力。
未来,文本分类的发展趋势可能包括以下几个方向:一是结合深度学习和传统机器学习的优势,发展混合模型;二是利用更强大的预训练模型提升文本理解能力;三是研究更有效的特征表示和选择方法;四是关注跨语言和跨领域的文本分类问题;五是提高分类系统的实时响应和适应性,以满足大数据环境下快速变化的需求。
中文文本分类是一个涉及多种技术、持续发展的研究领域,随着技术的进步,我们有望看到更高效、准确的文本分类解决方案,为信息管理和智能应用提供强大支持。

2019 年 10 月 Chinese Journal of Network and Information Security October 2019
2019045-1
第 5 卷第 5 期 网络与信息安全学报
Vol.5
No.5
中文文本分类方法综述
于游,付钰,吴晓平
(海军工程大学信息安全系,湖北 武汉 430033)
摘 要:如何高效地文本分类是当前研究的一个热点。首先对文本分类概念及流程中的分词、特征提取和文
本分类方法等相关技术及研究现状进行了介绍和阐述,然后分析了现有文本分类相关技术面临的挑战,最后
对文本分类的发展趋势进行了总结。
关键词:文本分类;分词;特征选择
中图分类号:TP391
文献标识码:A
doi: 10.11959/j.issn.2096−109x.2019045
Summary of text classification methods
YU You, FU Yu, WU Xiaoping
Department of Information Security, Naval University of Engineering, Wuhan 430033, China
Abstract: How to effectively classify text has become a hot topic. Firstly, the concept of text classification, word
segmentation, feature extraction and text classification methods were introduced, and the research actuality was
summarized. And then the challenges of text classification related technologies were analyzed. Finally, the develop-
ment trend of text classification was summarized.
Key words: text classification, word segmentation, feature selection
1 引言
随着大数据、云计算等现代信息技术的发
展,传统的纸质文档快速向电子化、数字化转
变。面对大量的数据和信息,人们越来越倾向
于利用计算机对数据和信息进行处理,不但可
以提高相关操作的效率,还可以在一定程度上
提高相关操作的准确度。信息挖掘和检索、自
然语言处理是目前数据管理的关键技术,而文
本分类则是这些技术进行操作的重要基础,是
目前研究的一个热点,也是一个难点。传统的
文本分类主要依靠人工完成,费时费力,为提
高文本分类的效率、降低成本,文本自动分类
技术已成为当前研究的一个热点。
收稿日期:2019−05−25;修回日期:2019−08−09
通信作者:于游,874354471@qq.com
基金项目:国家自然科学基金资助项目(No.61672531)
Foundation Item: The National Natural Science Foundation of China (No.61672531)
论文引用格式:于游, 付钰, 吴晓平. 中文文本分类方法综述[J]. 网络与信息安全学报, 2019, 5(5): 1-8.
YU Y, FU Y, WU X P. Summary of text classification methods[J]. Chinese Journal of Network and Information Security, 2019,
5(5): 1-8.
剩余7页未读,继续阅读
2009-10-10 上传
182 浏览量
141 浏览量
170 浏览量
189 浏览量
2021-10-02 上传
167 浏览量
2021-01-19 上传
196 浏览量
113 浏览量
2021-09-24 上传
172 浏览量
2019-08-07 上传
2022-08-04 上传
2022-09-21 上传
资源评论


赵小杏儿
- 粉丝: 26
- 资源: 314









最新资源
- 数据库应用程序开发银行ATM存取款机系统
- 温度指示报警电路设计资料
- 基于深度学习的文本生成视频的实现源码(毕业设计)
- 机械设计自动拧螺钉阀体装配设备sw2017全套设计资料100%好用.zip
- 同步控制vsg 仿真模型 matlab simulink 电压电流双环控制 同步控制 svpwm 离网 并网均可运行 仿真模型 交流复杂突变 电网频率波动 有功指令突变 均可稳定运行
- 超市订单管理系统ssm
- 中医喉科精义.pdf
- 三相异步电机本体模型 Matlab Simulink仿真模型(成品) 本模型利用数学公式搭建了三相异步电机的模型,可以很好的模拟三相异步电机的运行性能,适合研究电机本体时修改参考,电机的各波形都很好可
- 代码-智能网联汽车先进驾驶辅助系统
- 中医临床经验汇编 第一辑.pdf
- 中医临床经验选编 续集.pdf
- 中医临床经验资料汇编 第二辑.pdf
- 中医临床验案汇辑 第六辑.pdf
- 中医临床经验资料汇编 第一辑.pdf
- 中医千古不传之秘——药性阴阳转变大法.pdf
- T0002 电池舱基础施工图 24.12.28.dwg
