

文本相似度计算方法研究综述
王春柳,杨永辉,邓 霏,赖辉源
(中国工程物理研究院 计算机应用研究所,四川 绵阳 621000)
摘 要:【目的/意义】文本相似度计算是自然语言处理中的一项基础性研究,通过总结和分析文本相似度计算的经
典方法和当前最新的研究成果,完善对文本相似度计算方法的系统化研究,以便于快速学习和掌握文本相似度计
算方法。【方法/内容】对过去 20 年的文本相似度计算领域的经典文献进行整理,分析不同计算方法的基本思想、优
缺点,总结每种计算方法的侧重点和不同方向上最新的研究进展。【结果/结论】从表面文本相似度计算方法和语义
相似度计算方法两方面进行阐述,形成较为全面的分类体系,其中语义相似度计算方法中的基于语料库的方法是
该领域最为主要的研究方向。
关键字:文本相似度;语义相似度;语料库
中图分类号:G254; G252.8 DOI:10.13833/j.issn.1007-7634.2019.03.026
A Review of Text Similarity Approaches
WANG Chun-liu, YANG Yong-hui, DENG Fei, LAI Hui-yuan
(Institute of Computer Application, China Academy of Engineering Physics, Mianyang 621000,China)
Abstract:【Purpose/significance】Text similarity calculation is a basic research in natural language processing. Through
summing up and analyzing the classical methods of text similarity calculation and the latest research results, we improve
the systematic research on text similarity algorithms, so as to quickly learn and grasp the text similarity calculation methods.
【Method/process】We collate the classical literature in the field of text similarity algorithms in the past 20 years, and ana⁃
lyze the basic ideas, advantages and disadvantages of different computing methods, and summarizes the emphasis of each
method and the latest research progress in different directions.【Result/conclusion】The surface text similarity calculation
method and semantic similarity calculation method were discussed to form a more comprehensive classification system. Cor⁃
pus-based approach to semantic similarity calculation is the most important research direction in this field.
Keywords: text similarity; semantic similarity; sorpus-based; review
收稿日期:2018-05-27
基金项目:国防基础科研计划重点项目(JCKY2016212B004)
作者简介:王春柳(1993-),女,吉林辽源人,硕士研究生,主要从事语义计算、对话系统评测研究.
1 引 言
文本相似度计算是指通过一定的策略比较两个或多个
实体(包括词语、短文本、文档)之间的相似程度,得到一个具
体量化的相似度数值。随着计算机技术的迅速发展,越来越
多的信息充斥在网络平台上,对这些文本信息的深度挖掘和
研究对于帮助人们快速准确获取与需求相关的内容具有非
常实际的意义。其中,文本相似度算法是文本挖掘中的一个
至关重要的算法,是联系文本建模和表示等基础研究和文本
潜在信息上层应用研究的纽带
【1】
。例如,在文本分类、文本
聚类、词义消歧等信息检索问题上,搜索引擎中的问答系
统、智能检索等问题都需要文本相似度算法作为支撑。此
外,文本相似度算法也广泛应用在自动摘要、机器翻译等自
然语言处理问题中,是自然语言处理问题中的核心算法。
因此,完善对文本相似度算法的系统化研究具有非常重要
的应用价值。
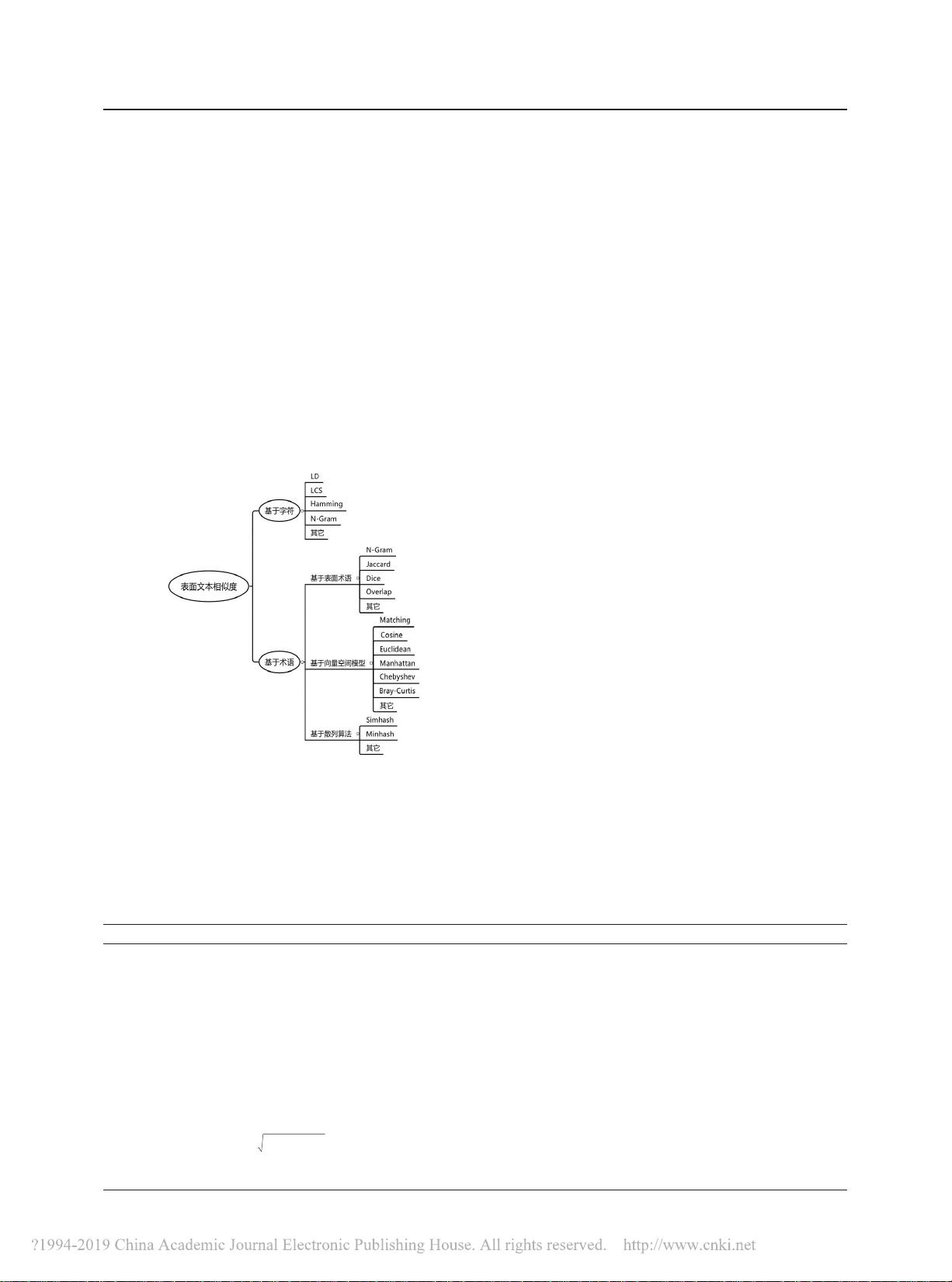
目前,文本相似度计算的方法已经越来越多,大多数学
者比较认可的分类方式是:基于字符串(String-Based)的方
法、基于语料库(Corpus-Based)的方法、基于知识库(Knowl⁃
edge-Based)的方法和混合方法
【2-4】
。为便于快速学习文本相
似度计算方法,本文将近年来的国内外相关文献进行收集、
情报科学
第第 3737 卷卷 第第 33 期期 20192019 年年 33 月月
·
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
综
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述
述·
-- 158
剩余10页未读,继续阅读













评论0