《网络数据采集》第5章课件201911231
需积分: 0 175 浏览量
2022-08-03
22:46:00
上传
评论
收藏 1004KB PDF 举报


网络
数
据
采
集
第
五
章
RIA
网
站
数
据
爬
取
讲师姓名:
授课时间:
共32课时,第19-22课时
1
课
前
引
导
与上
节
回
顾
前面介绍了爬取RIA网站的一些前置基础知识。下面,将介绍使用网络爬虫爬取RIA网站信息的具体方
法。
2
本
节
课
程
主
要
内
容
内容列表:
本节目标
RIA网站的技术构成
使用Selenium爬取RIA网站信息
本节总结
课后练习
2.1
本
节
目
标
掌握RIA型网站的技术构成,重点把握AJAX的技术特点;
掌握Selenium工具的使用方法,能够使用这一工具获取ajax驱动网页的页面信息。
2.2 RIA
网
站
的
技
术构
成
2.2.1
知
识讲
解
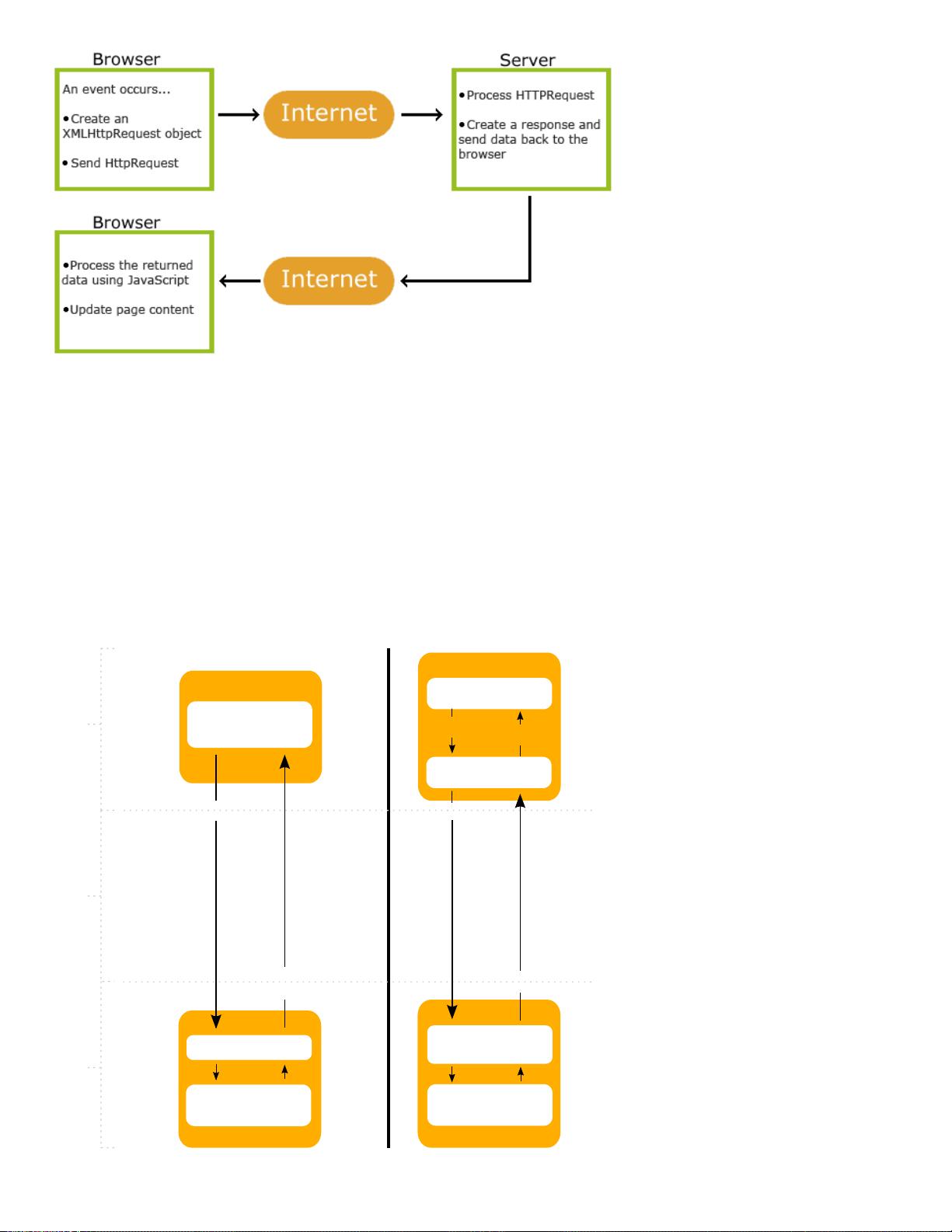
这一讲,我们介绍RIA网站数据爬取技术。
RIA是Rich Internet Applications的缩写,指富互联网应用程序。RIA是一种特殊的Web应用程序,其用
户界面比第一代和第二代Web应用程序具有更丰富的功能。它看起来和感觉更像桌面应用程序。



剩余38页未读,继续阅读













评论0