1-s2.0-S093336572100052X-main(科研通-ablesci.com)1
需积分: 0 98 浏览量
2022-08-04
14:42:19
上传
评论
收藏 8.06MB PDF 举报


Articial Intelligence In Medicine 115 (2021) 102059
Available online 26 March 2021
0933-3657/© 2021 Elsevier B.V. All rights reserved.
CEFEs: A CNN Explainable Framework for ECG Signals
Barbara Mukami Maweu
a
,
*
,
1
, Sagnik Dakshit
a
,
1
, Rittika Shamsuddin
b
,
Balakrishnan Prabhakaran
a
a
Erik Jonsson School of Eng. & Computer Science, University of Texas, Dallas, Richardson, TX, USA
b
Computer Science, Oklahoma State University, Stillwater, OK, USA
ARTICLE INFO
Keywords:
Deep learning
Convolution neural network
ECG Signals
Explainable AI
Explainable Framework
Synthetic healthcare data
ABSTRACT
In the healthcare domain, trust, condence, and functional understanding are critical for decision support sys-
tems, therefore, presenting challenges in the prevalent use of black-box deep learning (DL) models. With recent
advances in deep learning methods for classication tasks, there is an increased use of deep learning in
healthcare decision support systems, such as detection and classication of abnormal Electrocardiogram (ECG)
signals. Domain experts seek to understand the functional mechanism of black-box models with an emphasis on
understanding how these models arrive at specic classication of patient medical data. In this paper, we focus
on ECG data as the healthcare data signal to be analyzed. Since ECG is a one-dimensional time-series data, we
target 1D-CNN (Convolutional Neural Networks) as the candidate DL model. Majority of existing interpretation
and explanations research has been on 2D-CNN models in non-medical domain leaving a gap in terms of
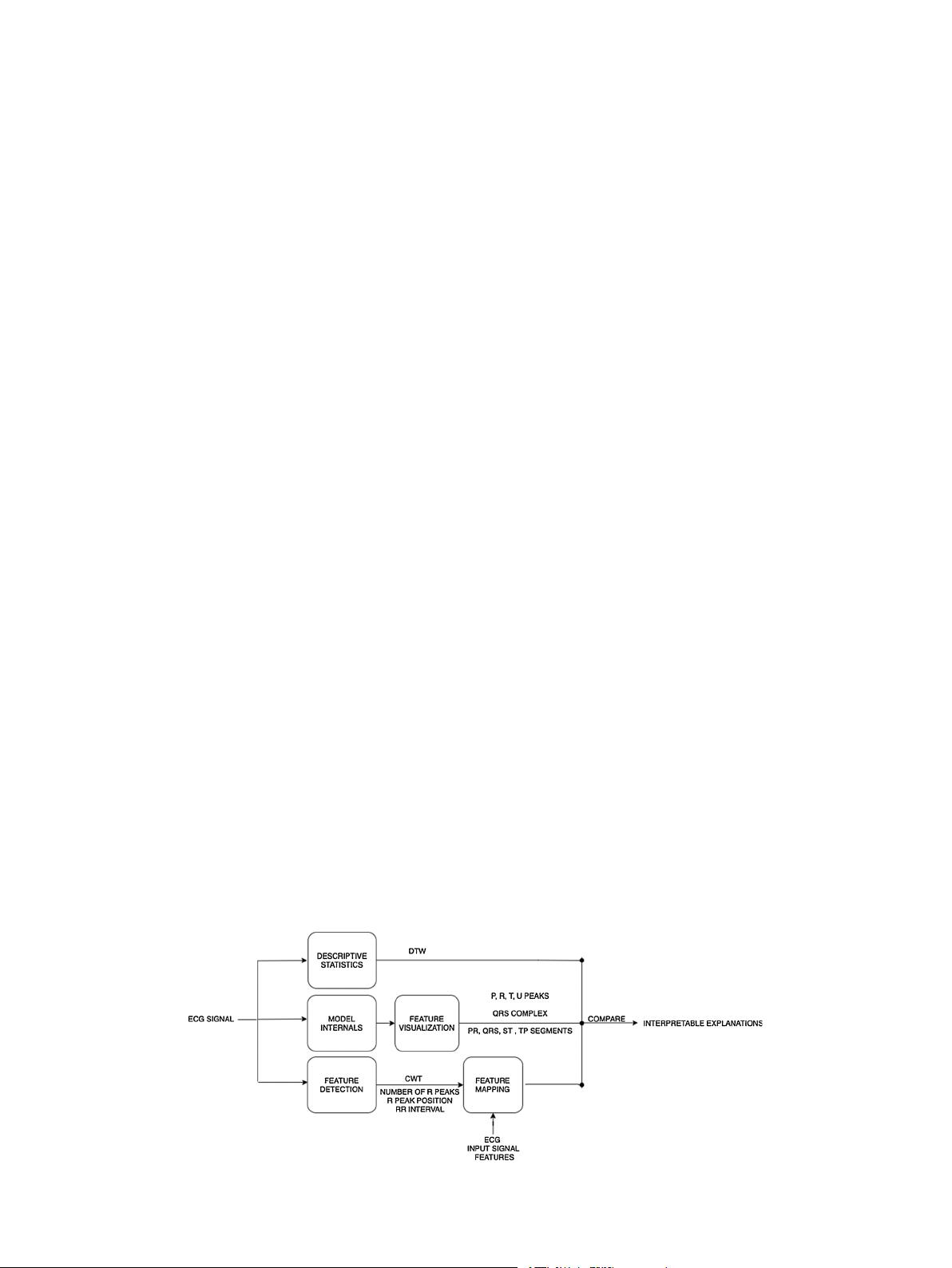
explanation of CNN models used on medical time-series data. Hence, we propose a modular framework, CNN
Explanations Framework for ECG Signals (CEFEs), for interpretable explanations. Each module of CEFEs provides
users with the functional understanding of the underlying CNN models in terms of data descriptive statistics,
feature visualization, feature detection, and feature mapping. The modules evaluate a model’s capacity while
inherently accounting for correlation between learned features and raw signals which translates to correlation
between model’s capacity to classify and it’s learned features. Explainable models such as CEFEs could be
evaluated in different ways: training one deep learning architecture on different volumes/amounts of the same
dataset, training different architectures on the same data set or a combination of different CNN architectures and
datasets. In this paper, we choose to evaluate CEFEs extensively by training on different volumes of datasets with
the same CNN architecture. The CEFEs’ interpretations, in terms of quantiable metrics, feature visualization,
provide explanation as to the quality of the deep learning model where traditional performance metrics (such as
precision, recall, accuracy, etc.) do not sufce.
1. Introduction
Deep learning models in healthcare are traditionally evaluated in
terms of accuracy, precision, and recall over the entire test set. These
metrics tell us the degree to which a model can accurately classify the
data but does not provide an interpretable explanation to the strength or
lack of capacity of the model. By the capacity of a model, we refer to the
model’s capability to correctly classify hard and easy cases alike. The
classication accuracy, precision, and recall alone are not sufcient for
deep learning-based applications in settings such as ICU (Intensive Care
Units) where ECG (Electrocardiogram) signals are monitored
automatically. There also persists the question whether the model has
learned the correct classication features (for instance, ECG features and
not some random Noise). An interpretable explanation-based metric
provides an understanding of the working of a neural network model
which can help researchers improve the model to accommodate both
hard and easy cases. While explainable methods such as class activation
mapping [31], saliency maps [27], and GradCam [11] exist, these are
not used as metrics for evaluation of model capacity and most of these
existing methods work more efciently with images, NLP (Natural
Language Processing) tasks, and 2D non-medical data. Furthermore, it is
not feasible to study each test signal’s activation maps or similar
* Corresponding author.
E-mail addresses: barbara.maweu@utdallas.edu (B.M. Maweu), sdakshit@utdallas.edu (S. Dakshit), r.shamsuddin@okstate.edu (R. Shamsuddin), bprabhakaran@
utdallas.edu (B. Prabhakaran).
1
Authors have equal contribution.
Contents lists available at ScienceDirect
Articial Intelligence In Medicine
journal homepage: www.elsevier.com/locate/artmed
https://doi.org/10.1016/j.artmed.2021.102059
Received 5 July 2020; Received in revised form 18 January 2021; Accepted 23 March 2021


剩余15页未读,继续阅读

臭人鹏
- 粉丝: 24
- 资源: 328









最新资源
- 基于Javascript的影视动画设计源码 - cad
- 基于Java和深度学习的瓦斯浓度预测系统后端设计源码 - 瓦斯浓度预测后端
- Screenshot_20240528_103010.jpg
- 基于Python的新能源承载力计算及界面设计源码 - HAINING-DG
- 基于Java的本科探索学习项目设计源码 - 本科探索
- 基于Javascript和Python的微商城项目设计源码 - MicroMall
- 基于Java的网上订餐系统设计源码 - online ordering system
- 基于Javascript的超级美眉网络资源管理应用模块设计源码
- 基于Typescript和PHP的编程知识储备库设计源码 - study-php
- Screenshot_2024-05-28-11-40-58-177_com.tencent.mm.jpg
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0