
Impala 与 Hive 的比较
1. Impala 架构
Impala 是 Cloudera 在受到 Google 的 Dremel 启发下开发的实时交互 SQL 大数据查询工具,Impa
la 没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布
式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直
接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。其架构如
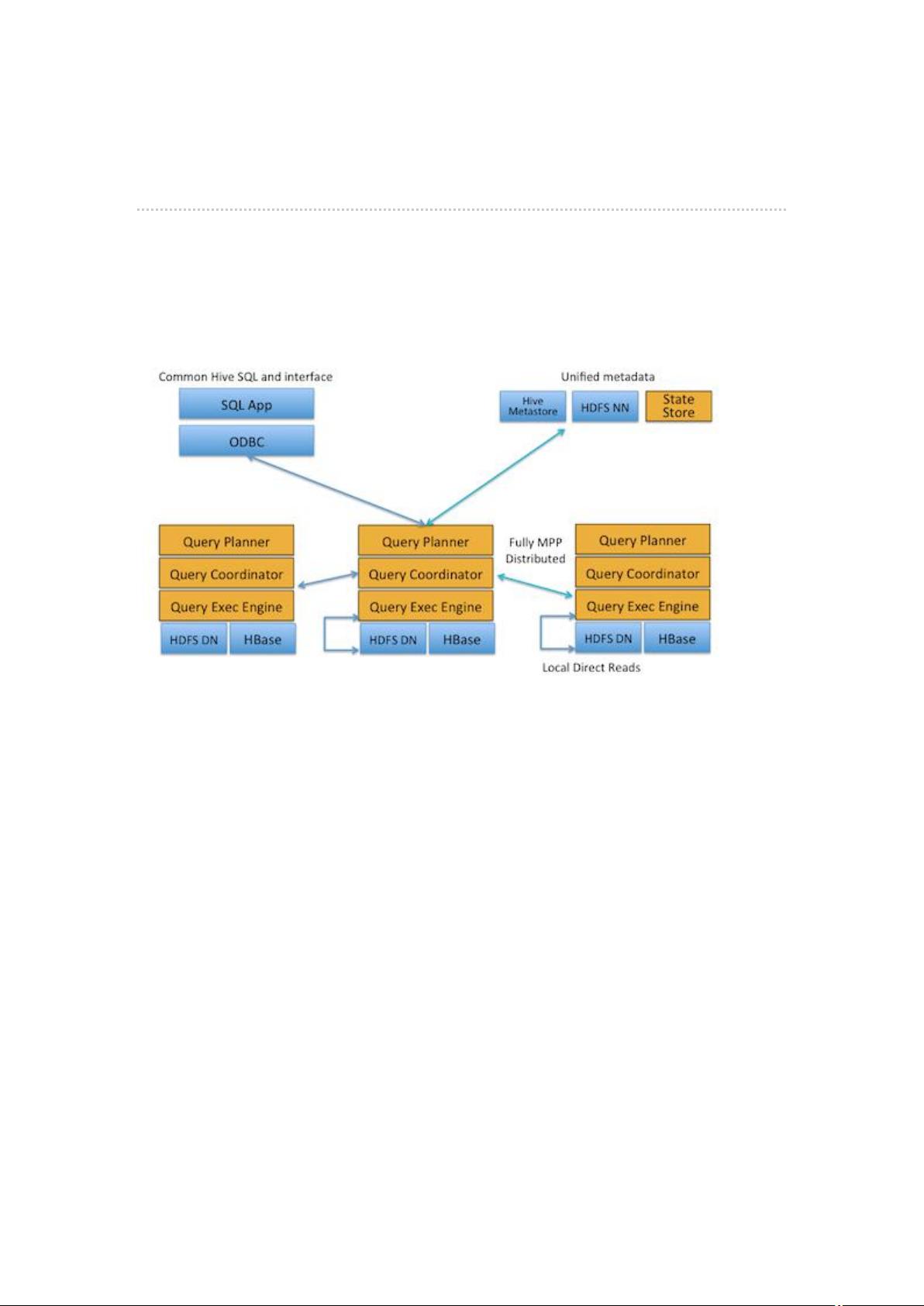
图 1 所示,Impala 主要由 Impalad, State Store 和 CLI 组成。
图 1
Impalad: 与 DataNode 运行在同一节点上,由 Impalad 进程表示,它接收客户端的查询请求
(接收查询请求的 Impalad 为 Coordinator,Coordinator 通过 JNI 调用 java 前端解释 SQL 查询语句,
生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它 Impalad 进行执行),读写数
据,并行执行查询,并把结果通过网络流式的传送回给 Coordinator,由 Coordinator 返回给客户端。
同时 Impalad 也与 State Store 保持连接,用于确定哪个 Impalad 是健康和可以接受新的工作。在 Impal
ad 中启动三个 ThriftServer: beeswax_server(连接客户端),hs2_server(借用 Hive 元数据),
be_server(Impalad 内部使用)和一个 ImpalaServer 服务。
Impala State Store: 跟踪集群中的 Impalad 的健康状态及位置信息,由 statestored 进程表示,
它通过创建多个线程来处理 Impalad 的注册订阅和与各 Impalad 保持心跳连接,各 Impalad 都会缓存
一份 State Store 中的信息,当 State Store 离线后(Impalad 发现 State Store 处于离线时,会进入
recovery 模式,反复注册,当 State Store 重新加入集群后,自动恢复正常,更新缓存数据)因为 Impalad
有 State Store 的缓存仍然可以工作,但会因为有些 Impalad 失效了,而已缓存数据无法更新,导致
把执行计划分配给了失效的 Impalad,导致查询失败。
CLI: 提供给用户查询使用的命令行工具(Impala Shell 使用 python 实现),同时 Impala 还提
供了 Hue,JDBC, ODBC 使用接口。

剩余6页未读,继续阅读
资源评论


普通网友
- 粉丝: 23
- 资源: 319









最新资源
- CDH6.3.2版本hive2.1.1修复HIVE-14706后的jar包
- 鸿蒙项目实战-天气项目(当前城市天气、温度、湿度,24h天气,未来七天天气预报,生活指数,城市选择等)
- Linux环境下oracle数据库服务器配置中文最新版本
- Linux操作系统中Oracle11g数据库安装步骤详细图解中文最新版本
- SMA中心接触件插合力量(插入力及分离力)仿真
- 变色龙记事本,有NPP功能,JSONview功能
- MongoDB如何批量删除集合中文最新版本
- seata-server-1.6.0 没有梯子的可以下载这个
- loadrunner参数化连接mysql中文4.2MB最新版本
- C#从SQL数据库中读取和存入图片中文最新版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


