2020春-lecture111
需积分: 0 191 浏览量
2022-08-03
16:39:13
上传
评论
收藏 1.86MB PDF 举报

1
高等计算机体系结构
第十一讲: 主存储器(II)、虚拟存储
栾钟治
北京航空航天大学 计算机学院 中德联合软件研究所
2020-05-29
提醒: 作业
• 作业 5
• 5月8日发布,6月5日上课前截止提交
• Cache和Memory
• 作业 6
• 6月5日发布,6月19日截止
• 预取和并行
2
实验2-5
• 5月10日发布,预计7月10日截止
3
阅读材料
• 分层存储体系结构
• Patterson & Hennessy‘s Computer Organization and
Design: The Hardware/Software Interface (计算机组
成与设计:软硬件接口)
• 第五章:5.1-5.3, 5.4
• Maurice Wilkes早期关于cache的论文
• Wilkes, “Slave Memories and Dynamic Storage Allocation,”
IEEE Trans. On Electronic Computers, 1965.
• 推荐阅读
• Denning, P. J. Virtual Memory. ACM Computing Surveys. 1970
• Jacob, B., & Mudge, T. Virtual Memory in Contemporary Microprocessors.
IEEE Micro. 1998
4
1 2
3 4
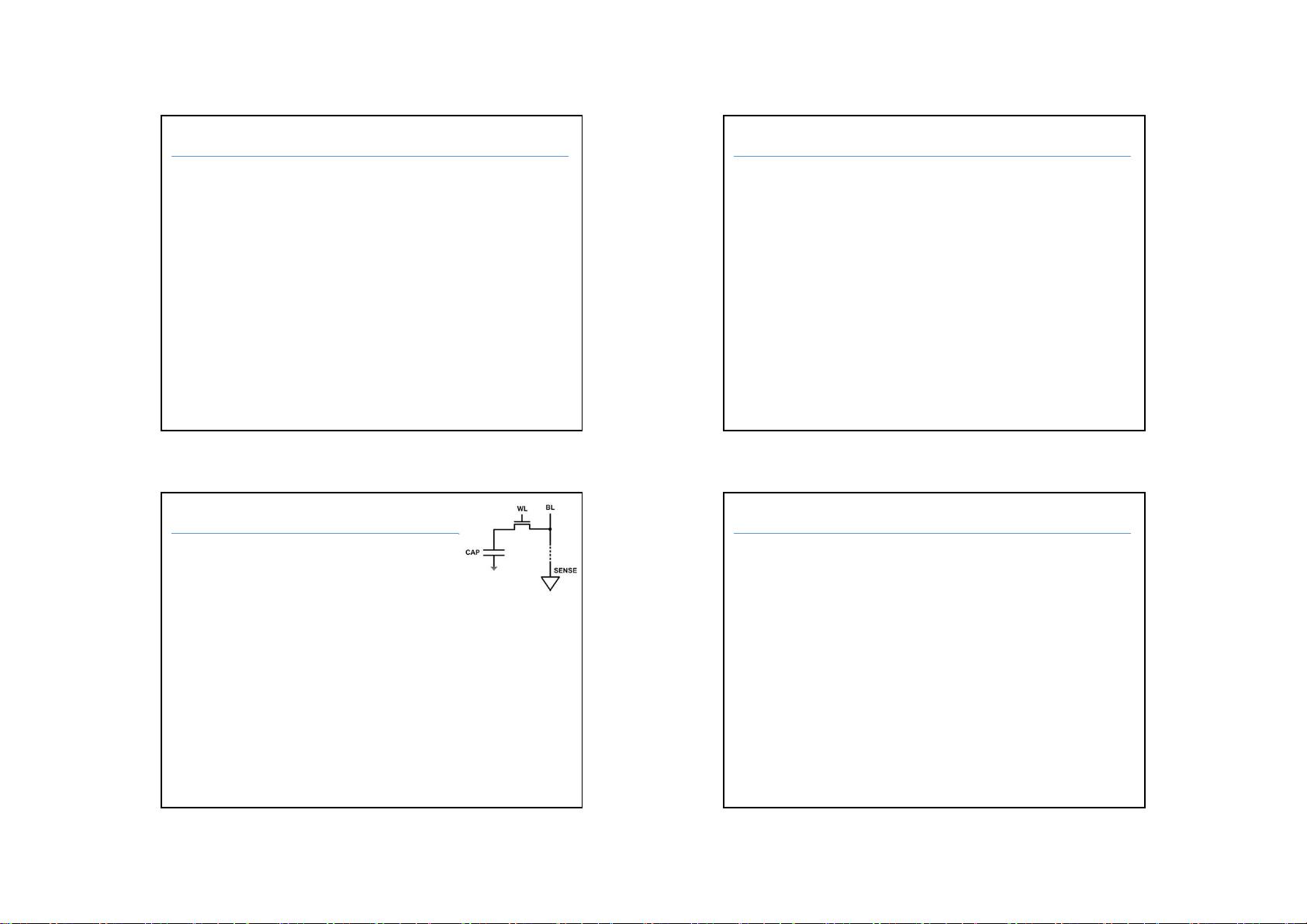
剩余30页未读,继续阅读













评论0