2018-10-第二周1

需积分: 0 94 浏览量
更新于2022-08-04
1
收藏 91KB PDF 举报
在本周的工作中,主要聚焦于SqueezeSeg网络的训练与数据预处理方面,这是一个针对语义分割任务的轻量级卷积神经网络模型,尤其适用于车载LiDAR数据的实时处理。SqueezeSeg网络设计的核心在于高效利用计算资源,通过SqueezeNet的压缩架构来实现对三维点云数据的二维投影分割。
对SqueezeSeg模型进行了训练,并在测试数据集上得到了初步结果。这一步骤通常包括模型的搭建、参数设置、优化器选择以及损失函数的定义。训练过程可能涉及到多轮迭代,每一轮都会更新模型权重以逐步提高对数据的理解和预测准确性。测试数据结果的分析是评估模型性能的关键,它可以帮助我们了解模型在未见过的数据上的泛化能力。
对原始数据进行了预处理,这是深度学习项目中的重要环节。原始数据往往需要经过一系列转换以适应模型的需求。在这个案例中,数据被转化为0-180度和0-360度的npy格式,这是一种常见的数值型数据存储方式,便于模型读取。这样的转换可能是因为SqueezeSeg网络需要输入特定角度范围的俯视图数据,将角度标准化有利于模型学习和减少冗余信息。
在数据处理过程中,提出了三种策略来应对数据集的问题:一是将图片拆分为四份,每份对应90度,以充分利用每个文件中的点;二是拆分为两份,使用180度的正向,同样是为避免数据浪费;三是不拆分图片,直接使用全部数据进行训练。这些尝试都是为了优化模型的学习效果,尤其是在数据量有限的情况下,通过数据增强技术可以有效提升模型的泛化能力。
此外,还提到了使用预训练模型(pretrain model)的方法,这通常是指利用已经在大规模数据集上训练好的模型作为初始权重,然后在目标数据集上进行微调(finetune)。在SqueezeSeg的情况下,可以使用lidar_2d预训练模型,并调整最后一层网络以适应新的任务。这样做的好处是可以利用预训练模型已经学习到的特征,加速训练进程并提高最终模型的性能。
下周的工作计划主要是继续数据预处理和模型优化。转换360度数据是为了让模型学习更全面的角度信息,而结合finetune方法使用预训练模型,则是希望在0-180度数据上进一步提升模型的表现。这种逐步迭代和优化的过程是深度学习项目中常见的实践,通过不断试验和调整,可以逐步提高模型的准确性和实用性。
这次工作涵盖了深度学习模型训练、数据预处理、模型优化以及预训练模型的应用等多个关键知识点,这些都是在进行网络软件开发或毕业设计时必须掌握的重要技能。
2018-10-第二周
CASIA
工作总结与安排
上周工作
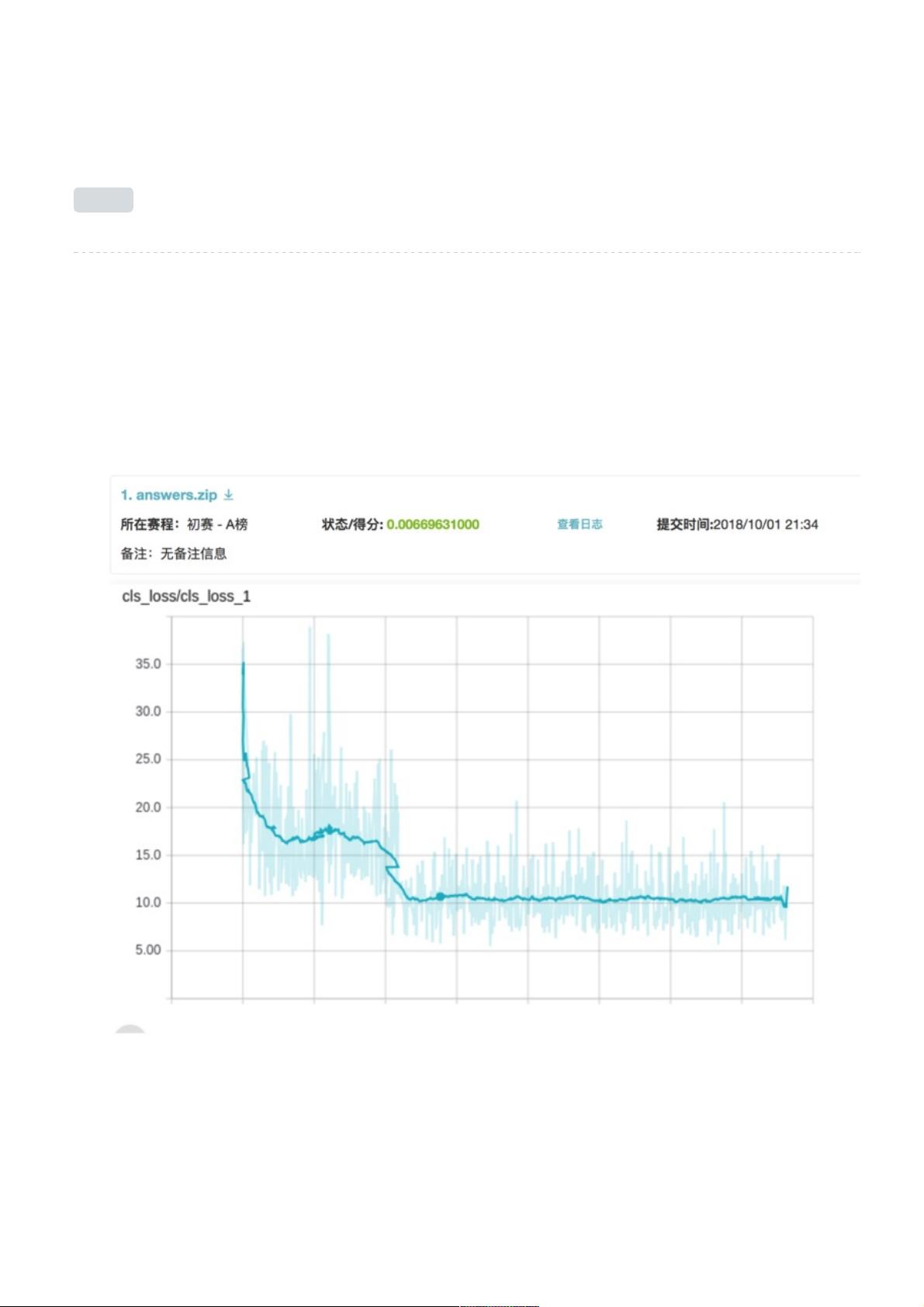
1. 本周在SqueezeSeg网络上进行了训练,用模型得出了测试数据的结果,结果如下:
2. 修改了转换数据的代码,将原始数据转换成0-180度的npy数据,以及0-360度的npy数
据;
3. 在0-180度数据上进行训练,loss并没有明显下降;
下载后可阅读完整内容,剩余1页未读,立即下载
资源评论


高工-老罗
- 粉丝: 25
- 资源: 314









最新资源
- 机械设计四通道漏液检测机sw18非常好的设计图纸100%好用.zip
- 机械设计铜端子打孔开槽sw21可编辑非常好的设计图纸100%好用.zip
- 基于深度强化学习的混合动力汽车能量管理策略 1.利用DQN算法控制电池和发动机发电机组的功率分配 2.状态量为需求功率和SOC,控制量为EGS功率 3.奖励函数设置为等效油耗和SOC维持 4.可以将D
- MATLAB 图像处理中的噪声分析与图像评价源程序.zip
- GIS各种名词解释,总共有196个名词解释
- 特征点检测与匹配-MATLAB R2022b资料及代码
- 机械设计吸塑件自动堆叠机sw14非常好的设计图纸100%好用.zip
- 直流电压源+双向DCDC变器+负载+锂离子电池+控制系统,Simulink仿真模型文件 有两种工作模式: 1锂离子电池经双向DCDC变器为负载供电 2电压源为负载供电同时经双向DCDC变器为
- 机械设计无纺布提袋机step非常好的设计图纸100%好用.zip
- 【电动汽车无序充电】采用蒙特卡洛抽样模拟电动汽车到达时间及到达的soc,对电动汽车无序充电总负荷进行了仿真计算 仿真平台:matlab+yalmip+cplex
- 基于FPGA的PWM电机控制+项目源码+文档说明
- 【新年快乐特效】点击放烟花
- jdk17安装包,window下的安装包
- CNN-LSTM-SAM-Attention分类 ,基于卷积神经网络(CNN)-长短期记忆神经网络(LSTM)结合空间注意力机制(SAM-Attention)的数据分类预测,多变量输入单输入 LSTM
- QT组件以及属性和方法
- 基于FPGA的RISC-V SoC,包含一个RV32I CPU、一个简单可扩展的总线、一些外设.zip
