COMP130144.01 计算机系统基础(下) 16307130194 陈中钰
2
1 总体状况
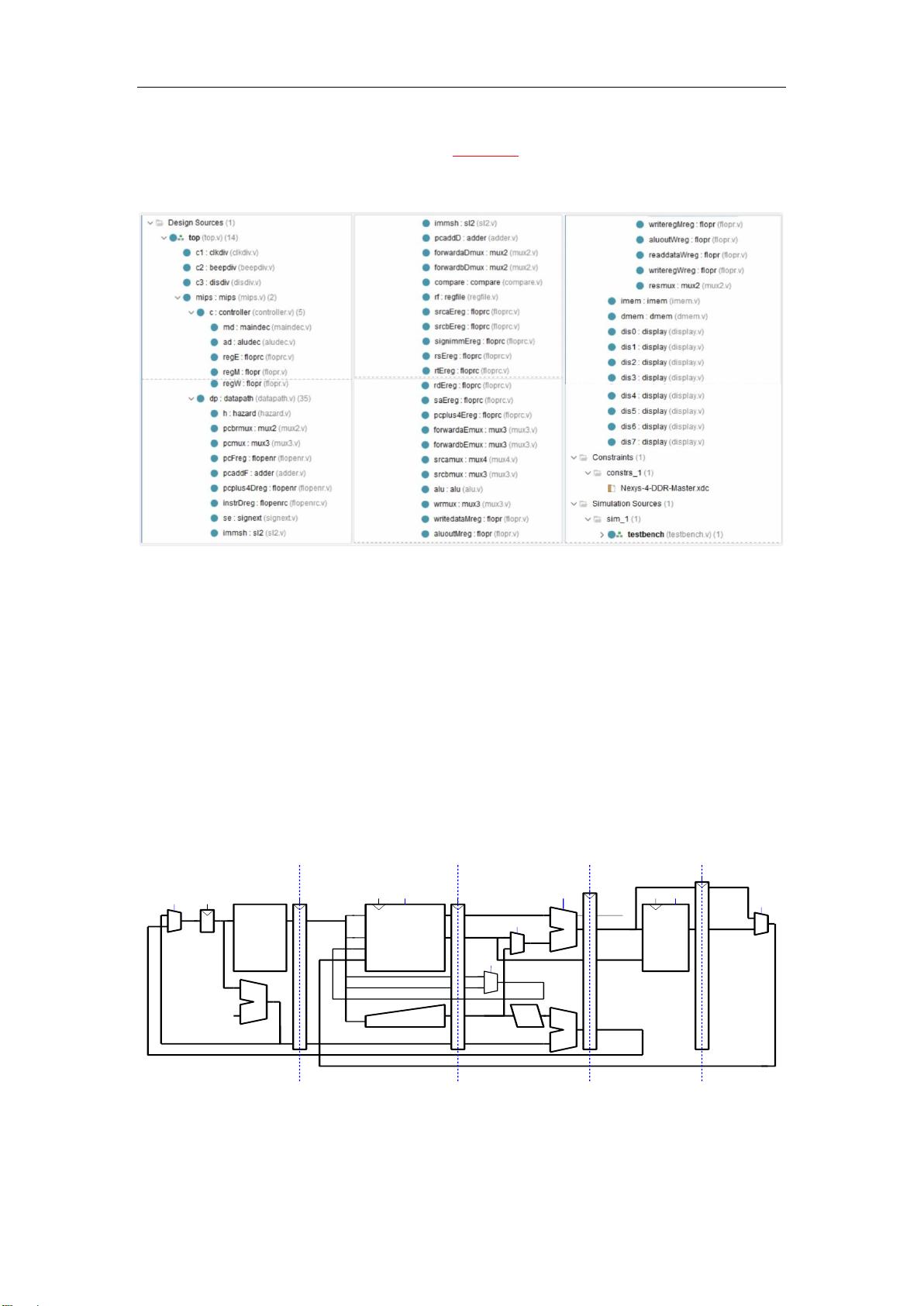
1.1 流水线 MIPS 处理器
单周期处理器在一个周期内执行一条完整的指令,结构易于解释且控制单元简单,
不需要其他非体系结构状态。但存在以下缺点:
时钟周期是由最慢的指令决定的,因此对于其他指令,每个周期都会有多余的时
间,整个处理器都处于空闲状态;
在一个时钟周期内,只执行一条指令,因此在任意时刻,大部分处理器硬件都处于
空闲状态,极大地限制了处理器的吞吐量。
因此,如要提高处理器效率,则需要减少处理器硬件空闲、提高吞吐量。而通过以
下的操作,可以实现上述的优化,获得流水线处理器:
在单周期处理器中插入 5 个流水线寄存器,分解成 5 个流水线阶段,使得可以在
每阶段流水线中同时执行 5 条指令,还可以几乎把时钟频率提高 5 倍,进而在理
想情况下,整个处理器的吞吐量可以提高 5 倍;
每个阶段的执行所需要的数据,包括 controller 控制信号,都要储存在流水线寄
存器中,随着流水线向前传播并保持同步;
正在并行处理的指令之间可能存在依赖关系(一条指令依赖另一条指令的结果),
这时候就会产生冲突,因此需要另外设计硬件来解决冲突。
尽管引入流水线寄存器增大了硬件成本,同时引入了一些开销,使吞吐量并不能达
到 5 倍之高,单条指令运行时间延长,但是流水线仍然有小成本的强大优势,并得到了
广泛的应用。
1.2 指令集(共 29 条指令,红色的是添加的 19 条指令)
逻辑运算:addi, and, or, add, sub, andi, ori, xor, xori, nor
移位运算:sll, srl, sra, lui, nop
分支跳转:beq, bne, bgez, bgtz, blez, bltz
比较运算:slt, slti
内存读写:sw, lw
跳转: j, jal, jalr, jr
注意:
以上指令的实现按照 MIPS 指令集文档中的格式,故不再附上指令格式要求
jal/jalr 指令调用函数,jr 函数返回后,紧跟 jal/jalr 的指令不会被执行
1.3 规格
register file: 32bit*32
data memory: 32bit*128
instruction memory: 32bit*128
1.4 实现功能
1. stop:屏蔽时钟,暂停运行
2. next:可在暂停的情况下,运行一条指令
3. reset:重置处理器

















评论0